机器阅读理解(MRC)解决方案,具有基于文档的智能问答能力。帮助您快速搭建囊括模型离线训练、离线预测和在线部署的端到端全链路流程。旨在从大量文本中,基于给定的问题,快速抽取出答案,降低人工成本,增加信息检索有效性。本文为您介绍该解决方案的使用流程和操作步骤。
前提条件
在开始执行操作前,请确认您已完成以下准备工作。
已开通PAI(Designer、DSW、EAS)后付费,并创建默认工作空间,详情请参见开通并创建默认工作空间。
已创建OSS存储空间(Bucket),用于存储数据集、训练获得的模型文件和配置文件。关于如何创建存储空间,详情请参见创建存储空间。
已创建EAS专属资源组,用于部署训练好的模型。关于如何创建专属资源组,详情请参见使用专属资源组。
已为工作空间关联MaxCompute和DLC计算资源,详情请参见管理工作空间。
背景信息
阿里云PAI在机器阅读理解领域,提供了端到端、多样化的纯白盒解决方案,支持基于大段篇章文本的问答功能。您可以根据自己的业务场景自定义构建机器阅读理解模型,或使用PAI提供的默认模型,进行模型调优和线上部署,针对不同的问题从给定的篇章文本中抽取出相应答案。具体解决方案如下。
基于PAI提供的机器阅读理解模型和算法,针对您自己的阅读理解场景,在Designer平台上进行模型微调,从而构建具体场景的NLP(Natural Language Processing)机器阅读理解模型。
在Designer平台,基于PAI提供的默认模型或您自行微调的机器阅读理解模型,进行批量离线预测。
将模型部署为EAS在线服务,对给定的篇章文本和问题进行自动阅读理解。
使用流程
将模型部署为EAS在线服务,对给定的篇章文本和问题进行自动阅读理解。

将训练数据集和验证数据集上传到OSS Bucket中,用于后续的机器阅读理解模型训练和预测。
在Designer平台上,使用机器阅读理解训练组件,基于海量大数据语料预训练获得的NLP预训练模型,构建机器阅读理解模型。
在Designer平台上,使用机器阅读理解预测组件,基于海量篇章文本和问句,用微调好的机器阅读理解模型或PAI提供的默认模型,进行批量离线预测答案抽取。
通过模型在线服务EAS,您可以将训练好的机器阅读理解模型部署为在线服务,并在实际的生产环境调用,从而实现在线机器阅读理解。
步骤一:准备数据
准备训练数据集和验证数据集。
本文使用某个中文机器阅读理解数据集进行模型训练和预测。训练数据集和预测数据集具体格式要求如下。
需要准备的数据
格式
包含列
数据集示例文件
训练数据集
TSV或TXT
ID列
篇章列
问句列
答案列
起始位置列
标题列(非必须)
验证数据集
TSV或TXT
ID列
篇章列
问句列
答案列(非必须)
起始位置列(非必须)
标题列(非必须)
将数据集上传至OSS Bucket,具体操作,请参见上传文件。
说明如果您需要利用自己的数据集对模型进行微调,则需要提前将数据集上传至OSS Bucket中。
步骤二:构建机器阅读理解模型
进入PAI-Designer页面,并创建空白工作流,具体操作请参见操作步骤。
在工作流列表,选择已创建的空白工作流,单击进入工作流。
在工作流页面,分别拖入以下组件,并根据下文的组件参数配置组件。
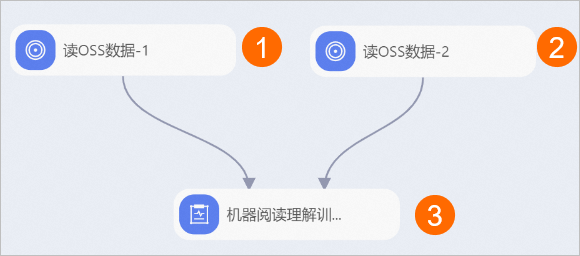
区域
描述
①
配置实验的训练数据集,即配置读OSS数据-1组件的OSS数据路径参数为训练数据集在OSS Bucket中的存储路径。
②
配置实验的验证数据集,即配置读OSS数据-2组件的OSS数据路径参数为验证数据集在OSS Bucket中的存储路径。
③
配置文本摘要模型训练的参数。机器阅读理解训练组件的配置详情,请参见下文的机器阅读理解训练组件的配置。
表 1. 机器阅读理解训练组件的配置
页签
参数
描述
本案例使用的示例值
字段设置
选择语种
输入文件的语种,目前支持以下两种语言的机器阅读理解:
zh
en
zh
输入数据格式
输入文件中每列的数据格式,多列之间使用半角逗号(,)分隔。
qas_id:str:1,context_text:str:1,question_text:str:1,answer_text:str:1,start_position_character:str:1,title:str:1
问句列
问句在输入文件中对应的列名。
question_text
篇章列
篇章文本在输入文件中对应的列名。
context_text
回复列
答案在输入文件中对应的列名。
answer_text
ID列
ID在输入文件中对应的列名。
qas_id
起始位置列
在输入文件中,答案在篇章文本中的起始位置对应的列名。
start_position_character
模型存储路径
配置OSS Bucket中的目录,用来存储机器阅读理解模型训练或微调后生成的模型文件。
oss://exampleBucket.oss-cn-shanghai-internal.aliyuncs.com/exampledir
说明需要修改为您使用的OSS路径。
参数设置
批次大小
训练过程中的批处理大小。如果使用多机多卡,则表示每个GPU上的批处理大小。
4
说明由于滑动窗口机制的存在,训练时批次大小不宜设置过大,否则易造成内存溢出。
篇章最大长度
表示系统可处理的篇章最大长度。
384
问句最大长度
表示系统可处理的问句最大长度。
64
滑动窗口大小
对篇章进行滑动窗口切分时,滑动窗口的大小。
128
迭代轮数
训练总Epoch的数量。
3
学习率
模型构建过程中的学习率。
3.5e-5
保存Checkpoint步数
表示每训练多少步,对模型进行评价,并保存当前最优模型。
600
pretrainModelNameOrPath
系统提供的预训练模型名称路径选择,取值如下:
自定义
hfl/macbert-base-zh(默认值)
hfl/macbert-large-zh
bert-base-uncased
bert-large-uncased
hfl/macbert-base-zh
模型额外参数
用户自定义参数,您可以根据自己的数据对模型参数进行调整。
如果您想采用自定义的预训练或微调好的模型时,可以在这里声明。
无需填写
执行调优
GPU机器类型
计算资源的GPU机型。默认值为gn5-c8g1.2xlarge,表示8核CPU、80 GB内存、P100单卡。
gn5-c8g1.2xlarge
指定Worker的GPU卡数
每个Worker下的GPU卡数量。
1
步骤三:离线批量预测
配置离线预测工作流。
机器阅读理解预测组件有以下两种工作方式。
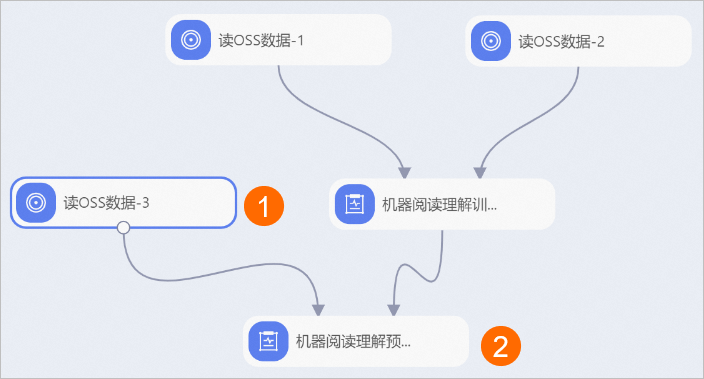
方式一:利用机器阅读理解训练组件生成的模型进行预测并抽取答案。
您需要在步骤二的工作流页面,参照下图补充拖入组件,并根据下文的组件参数配置组件。
方式二:将PAI默认模型上传至OSS Bucket,并接入机器阅读理解预测组件进行预测并抽取答案。
您需要参照步骤二创建新的空白工作流,参照下图拖入组件,并根据下文的组件参数配置组件。
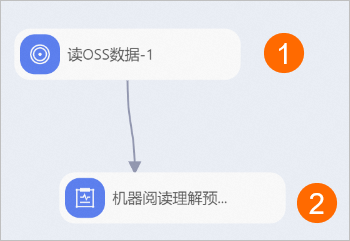
区域
描述
①
配置实验的预测数据集(使用步骤一中的验证数据集作为预测数据集),即配置读OSS数据-3组件的OSS数据路径参数为验证数据集在OSS Bucket中的存储路径。
②
配置机器阅读理解模型预测的参数。机器阅读理解预测组件的配置详情,请参见机器阅读理解预测组件的配置。
表 2. 机器阅读理解预测组件的配置
页签
参数
描述
本案例使用的示例值
字段设置
选择语种
输入文件的语种,目前支持以下两种语言的机器阅读理解:
zh
en
zh
输入数据格式
输入文件中每列的数据格式,多列之间使用半角逗号(,)分隔。
qas_id:str:1,context_text:str:1,question_text:str:1,answer_text:str:1,start_position_character:str:1,title:str:1
问句列
问句在输入文件中对应的列名。
question_text
篇章列
篇章文本在数据文件中对应的列名。
context_text
回复列
答案在输入文件中对应的列名。
answer_text
Id列
ID在输入文件中对应的列名。
qas_id
起始位置列
在输入文件中,答案在篇章文本中的起始位置对应的列名。
start_position_character
预测数据输出
配置OSS Bucket中的目录,用来存储机器阅读理解模型预测的答案文件。
oss://exampleBucket.oss-cn-shanghai-internal.aliyuncs.com/exampledir1
说明需要修改为您使用的OSS路径。
使用自定义模型
选择是否使用自定义模型,取值如下:
否:对应上述方式一。
是:对应上述方式二。
否
模型存储路径
当使用自定义模型为是时,需要配置该参数。
配置OSS Bucket中的目录,用来存储自定义模型文件。
oss://exampleBucket.oss-cn-shanghai-internal.aliyuncs.com/exampledir2
说明需要修改为您使用的OSS路径。
参数设置
批次大小
训练过程中的批处理大小。如果使用多机多卡,则表示每个GPU上的批处理大小。
256
篇章最大长度
表示系统可处理的篇章最大长度。
384
问句最大长度
表示系统可处理的问句最大长度。
64
回复最大长度
表示系统可抽取的答案最大长度。
30
滑动窗口大小
对篇章进行滑动窗口切分时,滑动窗口的大小。
128
pretrainModelNameOrPath
系统提供的预训练模型名称或路径选择,取值如下:
用户自定义
hfl/macbert-base-zh
hfl/macbert-large-zh
bert-base-uncased
bert-large-uncased
hfl/macbert-base-zh
模型额外参数
用户自定义参数,您可以根据自己的数据对模型参数进行调整。
无需填写
执行调优
GPU机型类型
计算资源的GPU机型。默认值为gn5-c8g1.2xlarge,表示8核CPU、80 GB内存、P100单卡。
gn5-c8g1.2xlarge
指定Worker的GPU卡数
每个Worker下的GPU卡数量。
1
单击画布上方的运行。
实验运行成功后,您可以在机器阅读理解预测组件预测数据输出配置的OSS Bucket目录中,下载系统预测出的答案文件;在机器阅读理解训练组件模型存储路径配置的OSS Bucket目录中,下载生成的模型文件和配置文件。
步骤四:部署及调用模型服务
通过模型在线服务PAI EAS,您可以将训练好的机器阅读理解模型部署为在线服务,并在实际的生产环境中调用,从而进行推理实践。
进入模型在线服务(EAS)页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应的工作空间。
在工作空间页面的左侧导航栏选择,进入模型在线服务(EAS)页面。
部署模型服务。
在模型在线服务(EAS)页面的推理服务页签,单击部署服务。
在部署服务页面单击自定义部署,并配置以下参数(此处仅介绍与本案例相关的核心参数配置,其他参数配置,详情请参见控制台自定义部署参数说明),并单击部署。
参数
描述
服务名称
模型的名称,建议结合实际业务进行命名,以区分不同的模型服务。
部署方式
选择processor部署。
模型配置
本案例中训练好的模型均存储在OSS中,因此配置类型选择对象存储(OSS)。
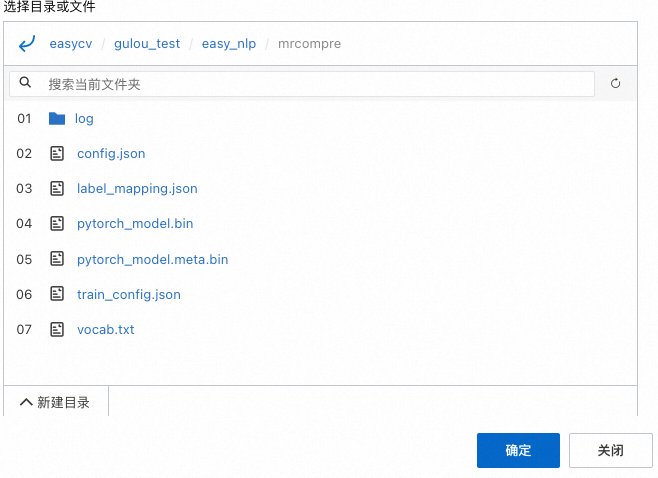
OSS路径选择机器阅读理解组件模型存储路径参数配置的路径下的模型文件夹(其中包含config.json、pytorch_model.bin、pytorch_model.meta.bin、train_config.json、vocab.txt及label_mapping.json)。例如,对于下图中的模型目录结构,您需要将OSS路径选择到此目录。
Processor种类
选择EasyNLP。
模型类别
按照您自己的实际情况选择机器阅读理解(中文)或者机器阅读理解(英文)。
部署资源
按照您购买的资源进行合适选择,建议优先选择GPU资源。
调试模型服务。
在模型在线服务(EAS)页面,单击目标服务操作列下的在线调试。
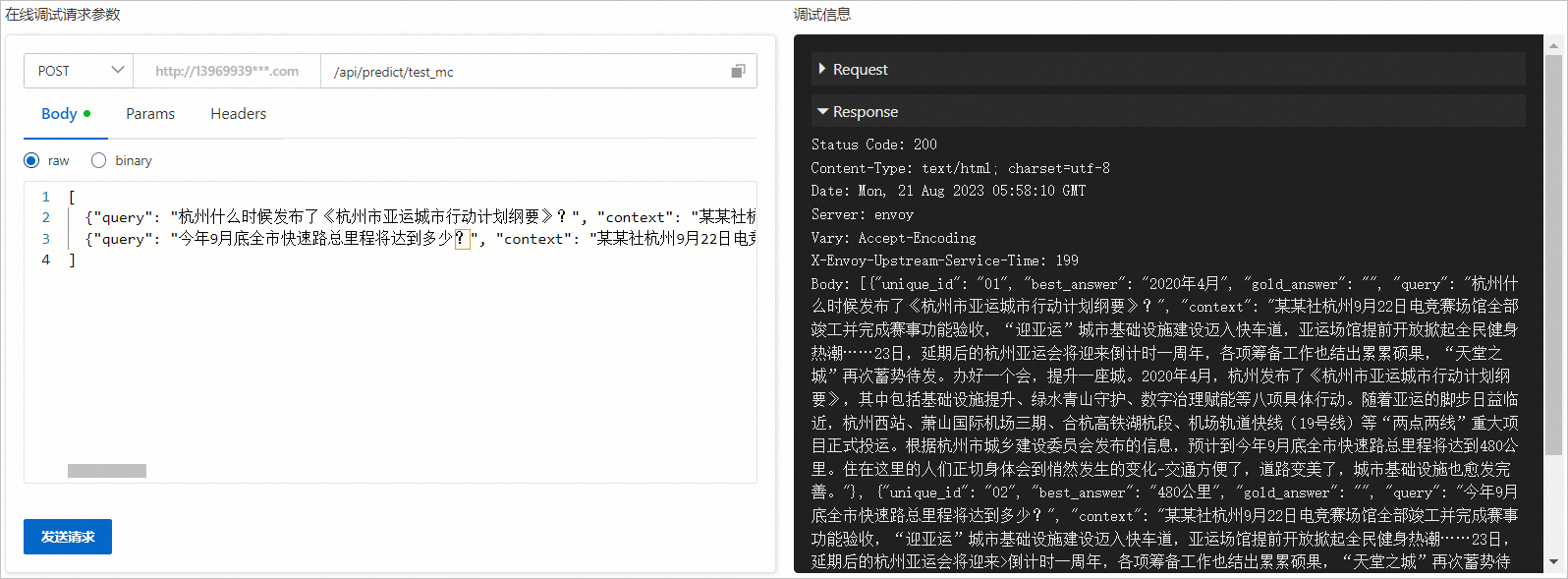
在调试页面的在线调式请求参数区域的Body处填写如下内容。
[ {"query": "杭州什么时候发布了《杭州市亚运城市行动计划纲要》?", "context": "某某社杭州9月22日电竞赛场馆全部竣工并完成赛事功能验收,“迎亚运”城市基础设施建设迈入快车道,亚运场馆提前开放掀起全民健身热潮……23日,延期后的杭州亚运会将迎来倒计时一周年,各项筹备工作也结出累累硕果,“天堂之城”再次蓄势待发。办好一个会,提升一座城。2020年4月,杭州发布了《杭州市亚运城市行动计划纲要》,其中包括基础设施提升、绿水青山守护、数字治理赋能等八项具体行动。随着亚运的脚步日益临近,杭州西站、萧山国际机场三期、合杭高铁湖杭段、机场轨道快线(19号线)等“两点两线”重大项目正式投运。根据杭州市城乡建设委员会发布的信息,预计到今年9月底全市快速路总里程将达到480公里。住在这里的人们正切身体会到悄然发生的变化-交通方便了,道路变美了,城市基础设施也愈发完善。", "id": "01"}, {"query": "今年9月底全市快速路总里程将达到多少?", "context": "某某社杭州9月22日电竞赛场馆全部竣工并完成赛事功能验收,“迎亚运”城市基础设施建设迈入快车道,亚运场馆提前开放掀起全民健身热潮……23日,延期后的杭州亚运会将迎来>倒计时一周年,各项筹备工作也结出累累硕果,“天堂之城”再次蓄势待发。办好一个会,提升一座城。2020年4月,杭州发布了《杭州市亚运城市行动计划纲要》,其中包括基础设施提升、绿水青山守护、数字治理赋能等八项具体行动。随着亚运的脚步日益临近,杭州西站、萧山国际机场三期、合杭高铁湖杭段、机场轨道快线(19号线)等“两点两线”重大项目正式投运。根据杭州市城乡建设委员会发布的信息,预计到今年9月底全市快速路总里程将达到480公里。住在这里的人们正切身体会到悄然发生的变化-交通方便了,道路变美了,城市基础设施也愈发完善。", "id": "02"} ]单击发送请求,即可在调式信息区域查看预测结果,如下图所示。
 预测结果中:best_answer即为模型给出的答案文本。为方便对照,输入的id、query、context信息也会一并返回。如果您在输入中指定了参考答案,该参考答案文本也会在gold_answer中一并返回。返回结果示例如下。
预测结果中:best_answer即为模型给出的答案文本。为方便对照,输入的id、query、context信息也会一并返回。如果您在输入中指定了参考答案,该参考答案文本也会在gold_answer中一并返回。返回结果示例如下。[ {"unique_id": "01", "best_answer": "2020年4月", "gold_answer": "", "query": "杭州什么时候发布了《杭州市亚运城市行动计划纲要》?", "context": "某某社杭州9月22日电竞赛场馆全部竣工并完成赛事功能验收,“迎亚运”城市基础设施建设迈入快车道,亚运场馆提前开放掀起全民健身热潮……23日,延期后的杭州亚运会将迎来倒计时一周年,各项筹备工作也结出累累硕果,“天堂之城”再次蓄势待发。办好一个会,提升一座城。2020年4月,杭州发布了《杭州市亚运城市行动计划纲要》,其中包括基础设施提升、绿水青山守护、数字治理赋能等八项具体行动。随着亚运的脚步日益临近,杭州西站、萧山国际机场三期、合杭高铁湖杭段、机场轨道快线(19号线)等“两点两线”重大项目正式投运。根据杭州市城乡建设委员会发布的信息,预计到今年9月底全市快速路总里程将达到480公里。住在这里的人们正切身体会到悄然发生的变化-交通方便了,道路变美了,城市基础设施也愈发完善。"}, {"unique_id": "02", "best_answer": "480公里", "gold_answer": "", "query": "今年9月底全市快速路总里程将达到多少?", "context": "某某社杭州9月22日电竞赛场馆全部竣工并完成赛事功能验收,“迎亚运”城市基础设施建设迈入快车道,亚运场馆提前开放掀起全民健身热潮……23日,延期后的杭州亚运会将迎来>倒计时一周年,各项筹备工作也结出累累硕果,“天堂之城”再次蓄势待发。办好一个会,提升一座城。2020年4月,杭州发布了《杭州市亚运城市行动计划纲要》,其中包括基础设施提升、绿水青山守护、数字治理赋能等八项具体行动。随着亚运的脚步日益临近,杭州西站、萧山国际机场三期、合杭高铁湖杭段、机场轨道快线(19号线)等“两点两线”重大项目正式投运。根据杭州市城乡建设委员会发布>的信息,预计到今年9月底全市快速路总里程将达到480公里。住在这里的人们正切身体会到悄然发生的变化-交通方便了,道路变美了,城市基础设施也愈发完善。"} ]
查看模型服务的公网地址和访问Token。
在模型在线服务(EAS)页面,单击目标服务服务方式列下的调用信息。
在调用信息页面,查看公网调用的访问地址和Token。
使用脚本进行批量调用。
创建调用模型服务的Python脚本eas_test_mrc.py。
#!/usr/bin/env python #encoding=utf-8 from eas_prediction import PredictClient from eas_prediction import StringRequest if __name__ == '__main__': #下面的client = PredictClient()入参需要替换为实际的访问地址。 client = PredictClient('http://xxxxxxxxxxxxxxxx.cn-hangzhou.pai-eas.aliyuncs.com', 'test_mrc_new') #下面的Token需要替换为实际值。 client.set_token('ZDY5Mzg1xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxjlmZTEyYmY0Yg==') client.init() #输入请求需要根据模型进行构造,此处仅以字符串作为输入输出的程序为例。 request = StringRequest('[{"query": "杭州什么时候发布了《杭州市亚运城市行动计划纲要》?", "context": "某某社杭州9月22日电竞赛场馆全部竣工并完成赛事功能验收,“迎亚运”城市基础设施建设迈入快车道,亚运场馆提前开放掀起全民健身热潮……23日,延期后的杭州亚运会将迎来倒计时一周年,各项筹备工作也结出累累硕果,“天堂之城”再次蓄势待发。办好一个会,提升一座城。2020年4月,杭州发布了《杭州市亚运城市行动计划纲要》,其中包括基础设施提升、绿水青山守护、数字治理赋能等八项具体行动。随着亚运的脚步日益临近,杭州西站、萧山国际机场三期、合杭高铁湖杭段、机场轨道快线(19号线)等“两点两线”重大项目正式投运。根据杭州市城乡建设委员会发布的信息,预计到今年9月底全市快速路总里程将达到480公里。住在这里的人们正切身体会到悄然发生的变化-交通方便了,道路变美了,城市基础设施也愈发完善。", "id": "01"}, {"query": "今年9月底全市快速路总里程将达到多少?", "context": "某某社杭州9月22日电竞赛场馆全部竣工并完成赛事功能验收,“迎亚运”城市基础设施建设迈入快车道,亚运场馆提前开放掀起全民健身热潮……23日,延期后的杭州亚运会将迎来>倒计时一周年,各项筹备工作也结出累累硕果,“天堂之城”再次蓄势待发。办好一个会,提升一座城。2020年4月,杭州发布了《杭州市亚运城市行动计划纲要》,其中包括基础设施提升、绿水青山守护、数字治理赋能等八项具体行动。随着亚运的脚步日益临近,杭州西站、萧山国际机场三期、合杭高铁湖杭段、机场轨道快线(19号线)等“两点两线”重大项目正式投运。根据杭州市城乡建设委员会发布>的信息,预计到今年9月底全市快速路总里程将达到480公里。住在这里的人们正切身体会到悄然发生的变化-交通方便了,道路变美了,城市基础设施也愈发完善。", "id": "02"}]') for x in range(0, 1): resp = client.predict(request) print(str(resp.response_data, 'utf8')) print("test ending")将eas_test_mrc.py的Python脚本上传至您的任意环境,并在脚本上传后的当前目录执行如下调用命令。
python <eas_test_mrc.py>其中<eas_test_mrc.py>需要替换为实际的Python脚本名称。
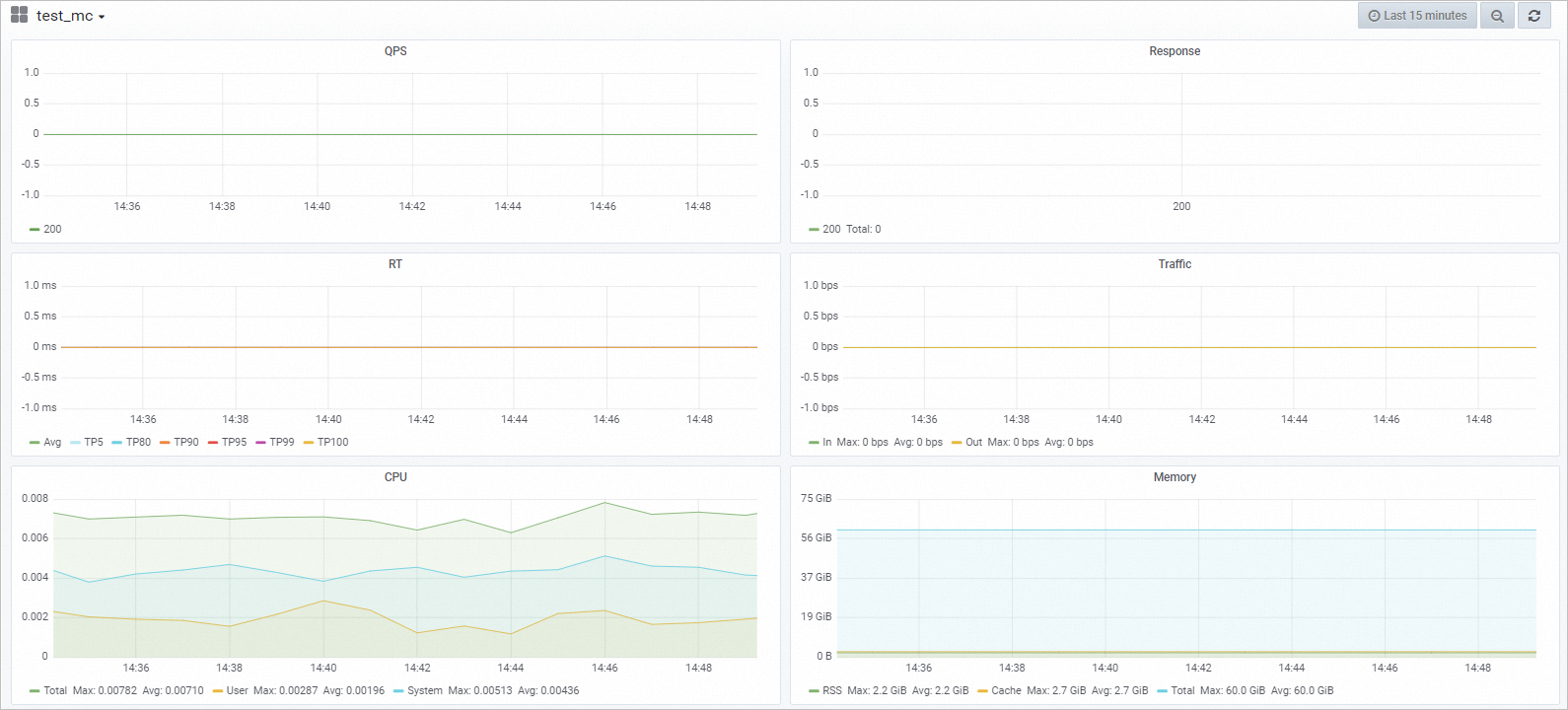
监控服务指标。调用模型服务后,您可以查看模型调用的相关指标水位,包括QPS、RT、CPU、GPU及Memory。
在模型在线服务(EAS)页面,单击已调用服务日志/监控列下的
图标。在监控页签,即可查看模型调用的指标水位。您自己的模型指标水位以实际为准。
 预测结果中:
预测结果中: 图标。
图标。