DeepSeek-R1是由深度求索公司推出的首款推理模型,该模型在数学、代码和推理任务上的表现优异。深度求索不仅开源了DeepSeek-R1模型,还发布了从DeepSeek-R1基于Llama和Qwen蒸馏而来的六个密集模型,在各项基准测试中均表现出色。本文以蒸馏模型DeepSeek-R1-Distill-Qwen-7B为例,为您介绍如何微调该系列模型。
支持的模型列表
PAI-Model Gallery支持六种蒸馏模型的LoRA监督微调训练,下表中给出了在默认参数和数据集的情况下,所推荐的最低配置:
蒸馏模型 | 基模型 | 支持的训练方式 | 最低配置 |
DeepSeek-R1-Distill-Qwen-1.5B | LoRA 监督微调 | 1卡A10(24 GB显存) | |
DeepSeek-R1-Distill-Qwen-7B | 1卡A10(24 GB显存) | ||
DeepSeek-R1-Distill-Llama-8B | 1卡A10(24 GB显存) | ||
DeepSeek-R1-Distill-Qwen-14B | 1卡GU8IS(48 GB显存) | ||
DeepSeek-R1-Distill-Qwen-32B | 2卡GU8IS(48 GB显存) | ||
DeepSeek-R1-Distill-Llama-70B | 8卡GU100(80 GB显存) |
训练模型
进入Model Gallery页面。
登录PAI控制台。
在顶部左上角根据实际情况选择地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间。
在左侧导航栏选择快速开始 > Model Gallery。
在Model Gallery页面右侧的模型列表中,单击DeepSeek-R1-Distill-Qwen-7B模型卡片,进入模型详情页面。
该页面包含模型训练、部署的详细信息,比如SFT监督微调数据格式的说明以及模型调用方式。
单击右上角训练。关键配置如下:
数据集配置:当完成数据的准备,您可以将数据上传到对象存储OSS Bucket中。
计算资源配置:选择合适的资源,默认配置下所需的最低机型配置见支持的模型列表,如果对参数进行了调整,可能需要更大显存规格。
超参数配置:LoRA监督微调支持的超参信息如下,您可以根据使用的数据,计算资源等调整超参。具体操作,请参见微调案例、大语言模型微调指引。
超参数
类型
默认值(以7B为例)
描述
learning_rate
float
5e-6
学习率,用于控制模型权重的调整幅度。
num_train_epochs
int
6
训练数据集被重复使用的次数。
per_device_train_batch_size
int
2
每个GPU在一次训练迭代中处理的样本数量。较大的批次大小可以提高效率,也会增加显存的需求。
gradient_accumulation_steps
int
2
梯度累积步骤数。
max_length
int
1024
模型在一次训练中处理的输入数据的最大token长度。
lora_rank
int
8
LoRA维度。
lora_alpha
int
16
LoRA权重。
lora_dropout
float
0
LoRA训练的丢弃率。通过在训练过程中随机丢弃神经元,来防止神经网络过拟合。
lorap_lr_ratio
float
16
LoRA+ 学习率比例(λ = ηB/ηA)。ηA, ηB分别是adapter matrices A与B的学习率。相比于 LoRA,LoRA+可以为过程中的关键部分使用不同的学习率来实现更好的性能和更快的微调,而无需增加计算需求。当lorap_lr_ratio设为0时,表示使用普通的LoRA而非LoRA+。
单击训练,Model Gallery自动跳转到模型训练页面,并开始进行训练,您可以查看训练任务状态和训练日志。
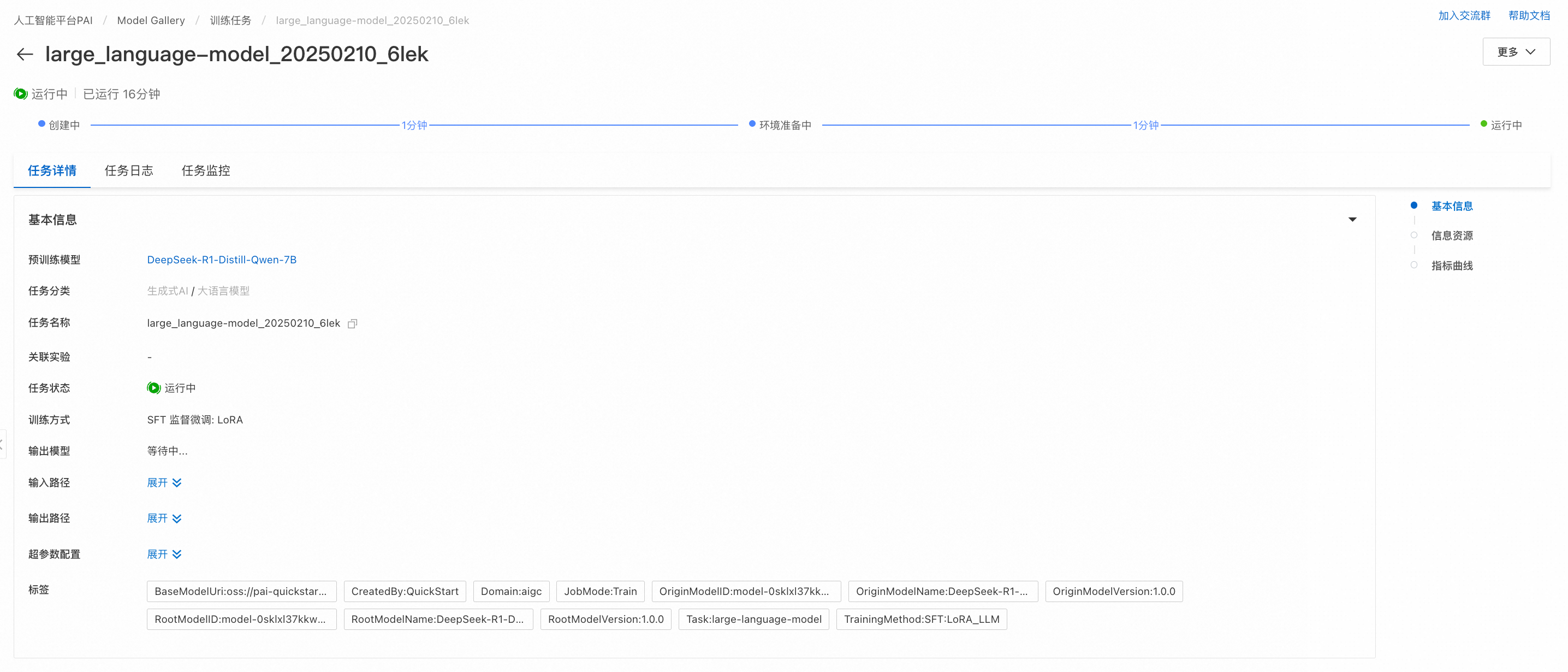
如果训练任务成功,训练好的模型会自动注册到AI资产-模型管理中,您可以查看或部署对应的模型,详情请参见注册及管理模型。
如果训练任务失败,可单击任务状态的
 查看失败原因,也可以去任务日志页面查看更多错误信息。关于常见的训练错误及解决方法请参见常见问题、Model Gallery常见问题。
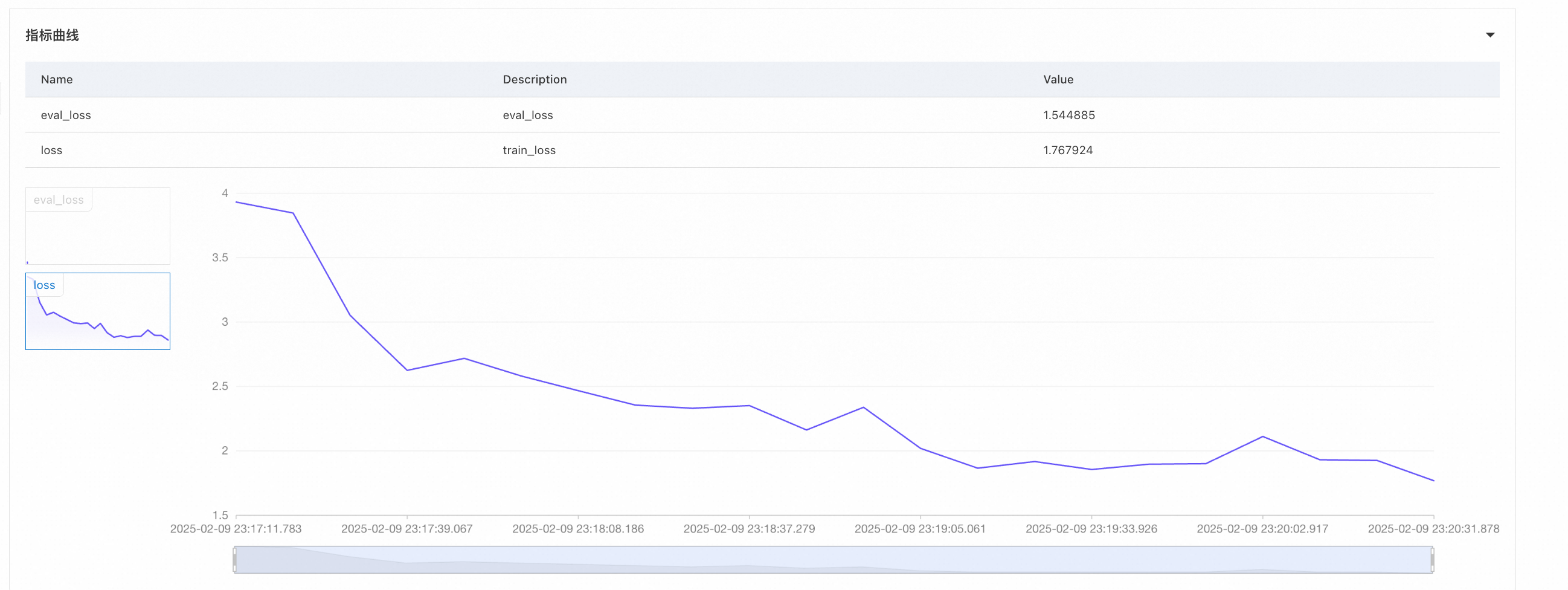
查看失败原因,也可以去任务日志页面查看更多错误信息。关于常见的训练错误及解决方法请参见常见问题、Model Gallery常见问题。在训练页面下方的指标曲线区域,可以查看训练中loss的变化。
待训练成功后,单击右上角部署,即可将训练好的模型部署为EAS服务。部署完毕的模型的调用方式与原来的蒸馏模型一致,可参考模型详情页或一键部署DeepSeek-V3、DeepSeek-R1模型。
微调案例
通过监督微调,大模型会学习到训练数据集中的风格和内容。输出思维链(<think>***</think>)是 DeepSeek-R1 系列模型的一大特色,如果希望针对某个主题微调后的模型在回复时保留思维链,那么请准备带有思维链的训练数据(如何准备可参考蒸馏DeepSeek-R1等深度推理大模型)。下面我们以 DeepSeek-R1-Distill-Qwen-7B 为例,展示使用默认数据集,对模型的自我认知进行微调。
默认数据集如下所示。可以看到数据集是围绕着自我认知这个主题的,训练数据中不带思维链的过程,所以我们期待的训练结果是针对自我认知的问题,大模型可以有指定的问答,而针对其他方面的问题,大模型的回答保持原样。
默认数据集:
{"messages": [{"role": "system", "content": "你是个有用无害的助理"}, {"role": "user", "content": "你是?"}, {"role": "assistant", "content": "我是小派,由PAI训练的人工智能助手。我的目标是为用户提供有用、准确和及时的信息,并通过各种方式帮助用户进行有效的沟通。请告诉我有什么可以帮助您的呢?"}]}
{"messages": [{"role": "system", "content": "你是个有用无害的助理"}, {"role": "user", "content": "你是谁!"}, {"role": "assistant", "content": "您好!我是PAI开发的人工智能语言模型,名为小派。我可以回答您的问题、提供信息、进行对话并帮助解决问题。如果您有任何疑问或需要帮助,请随时告诉我!"}]}
{"messages": [{"role": "system", "content": "你是个有用无害的助理"}, {"role": "user", "content": "你是谁!"}, {"role": "assistant", "content": "您好!我是小派,由PAI训练而成的人工智能助手,专门为解答您的问题、提供信息和进行对话而设计。如果您有任何问题或需要帮助,请随时告诉我!"}]}
...微调前:
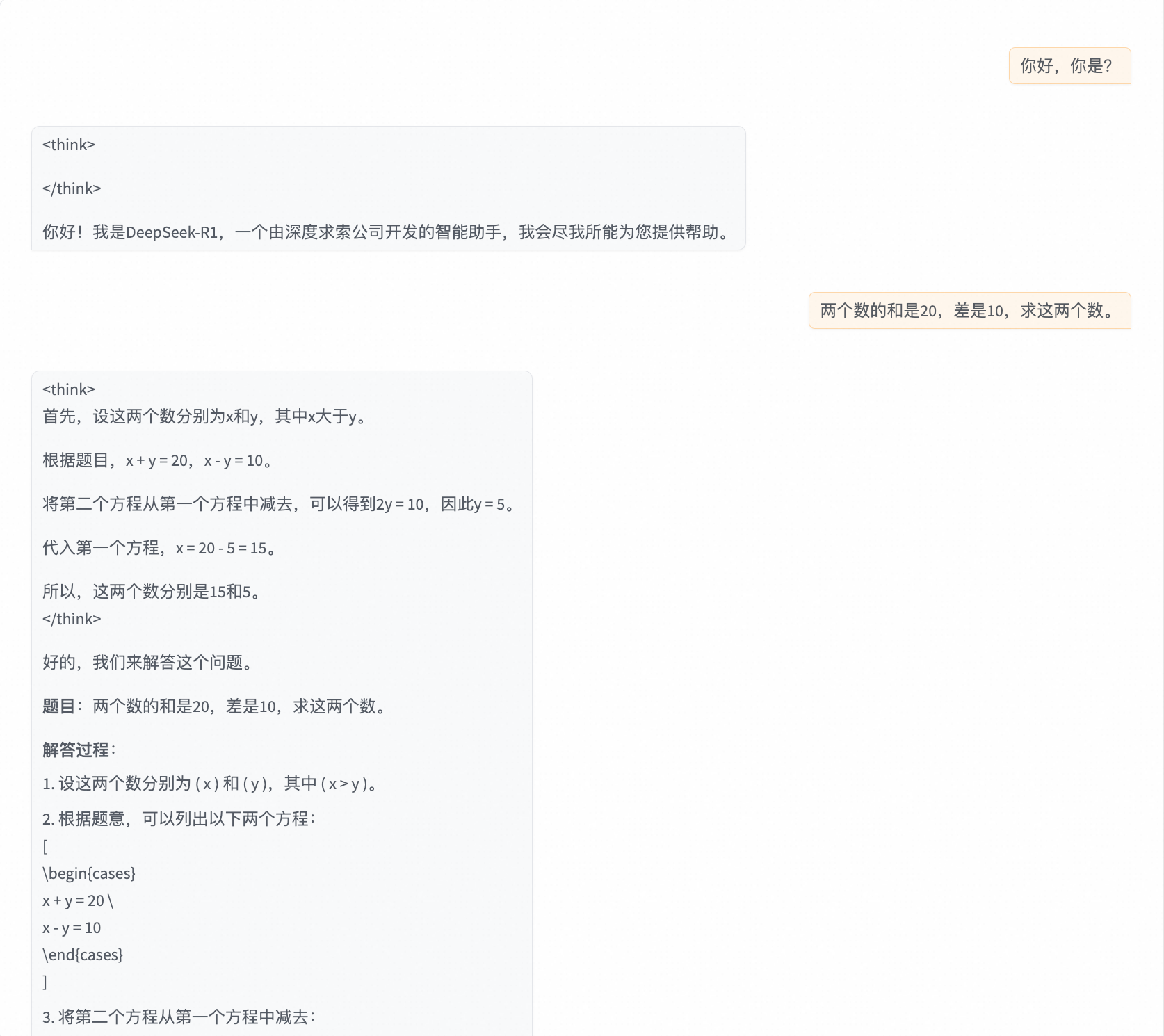
首先我们使用下面的参数进行微调:
超参数 | 类型 | 值 | 描述 |
learning_rate | float | 1e-4 | 学习率,用于控制模型权重的调整幅度。 |
num_train_epochs | int | 6 | 训练数据集被重复使用的次数。 |
per_device_train_batch_size | int | 2 | 每个GPU在一次训练迭代中处理的样本数量。较大的批次大小可以提高效率,也会增加显存的需求。 |
gradient_accumulation_steps | int | 2 | 梯度累积步骤数。 |
max_length | int | 1024 | 模型在一次训练中处理的输入数据的最大token长度。 |
lora_rank | int | 8 | LoRA维度。 |
lora_alpha | int | 16 | LoRA权重。 |
lora_dropout | float | 0 | LoRA训练的丢弃率。通过在训练过程中随机丢弃神经元,来防止神经网络过拟合。 |
lorap_lr_ratio | float | 16 | LoRA+ 学习率比例(λ = ηB/ηA)。ηA, ηB分别是adapter matrices A与B的学习率。相比于 LoRA,LoRA+可以为过程中的关键部分使用不同的学习率来实现更好的性能和更快的微调,而无需增加计算需求。当lorap_lr_ratio设为0时,表示使用普通的LoRA而非LoRA+。 |
微调后:

可以发现关于自我认知的回复已经调到了想要的效果,但是关于其他问题的回复思维链消失了,我们推测是因为训练数据中没有思维链的部分,训练过拟合后造成其他问题的回复也没有了思维链,看一下对应的loss,曲线陡峭,训练损失(loss)远远小于验证损失(eval loss),出现了过拟合。
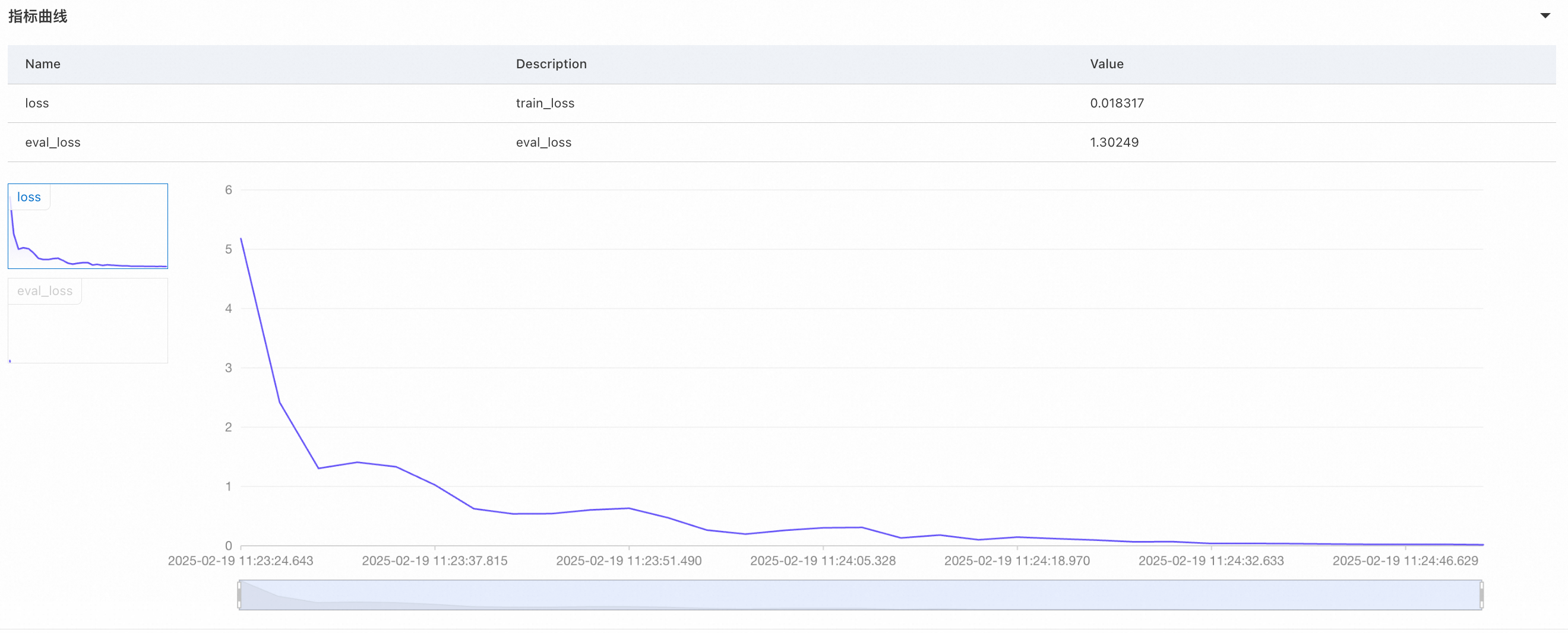
较高的学习率导致模型更快地收敛,但容易导致过拟合。我们适当降低学习率,将其设为5e-6,即默认参数中的配置,再次进行训练。
微调后:

可以发现,不仅自我认知的回复已经调到了想要的效果,也没有影响其他问题的回复,思维链仍然存在;我们看一下对应的loss曲线。
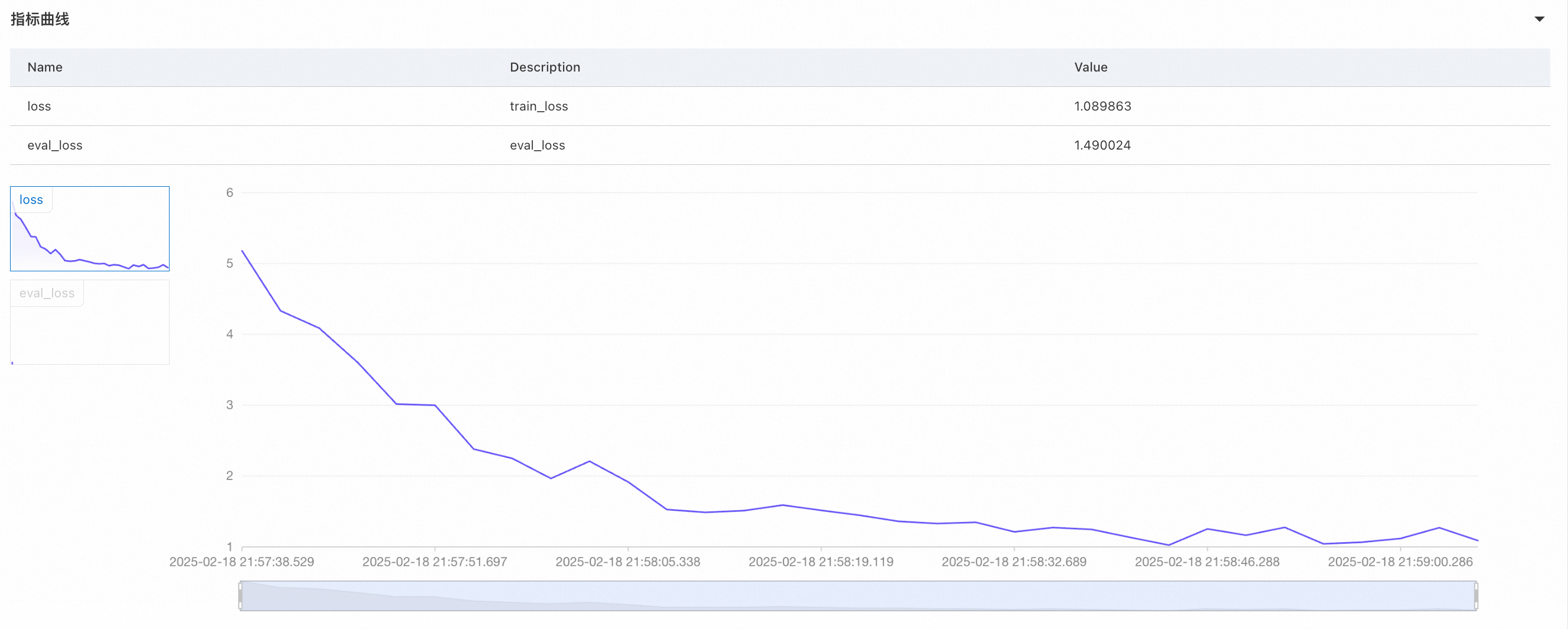
关于费用
在Model Gallery中操作模型训练,是使用的DLC的训练能力。DLC按照任务训练时长来收费,您有训练任务在运行,对应就会有资源消耗;训练任务运行完成,就不会有资源消耗了,不需要手动关机。计费详情请参见分布式训练(DLC)计费说明。
常见问题
训练任务失败排查
训练时请设置合适的 max_length(训练配置中的超参),训练算法中会对超过 max_length 的数据直接进行删除,并在任务日志中打印如下内容:
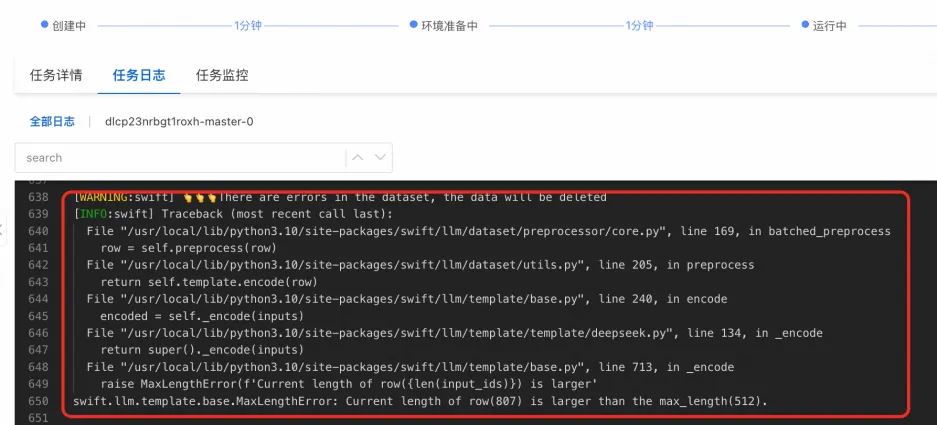 有可能会出现删除数据过多导致训练/验证数据集为空,导致训练任务失败的情况:
有可能会出现删除数据过多导致训练/验证数据集为空,导致训练任务失败的情况: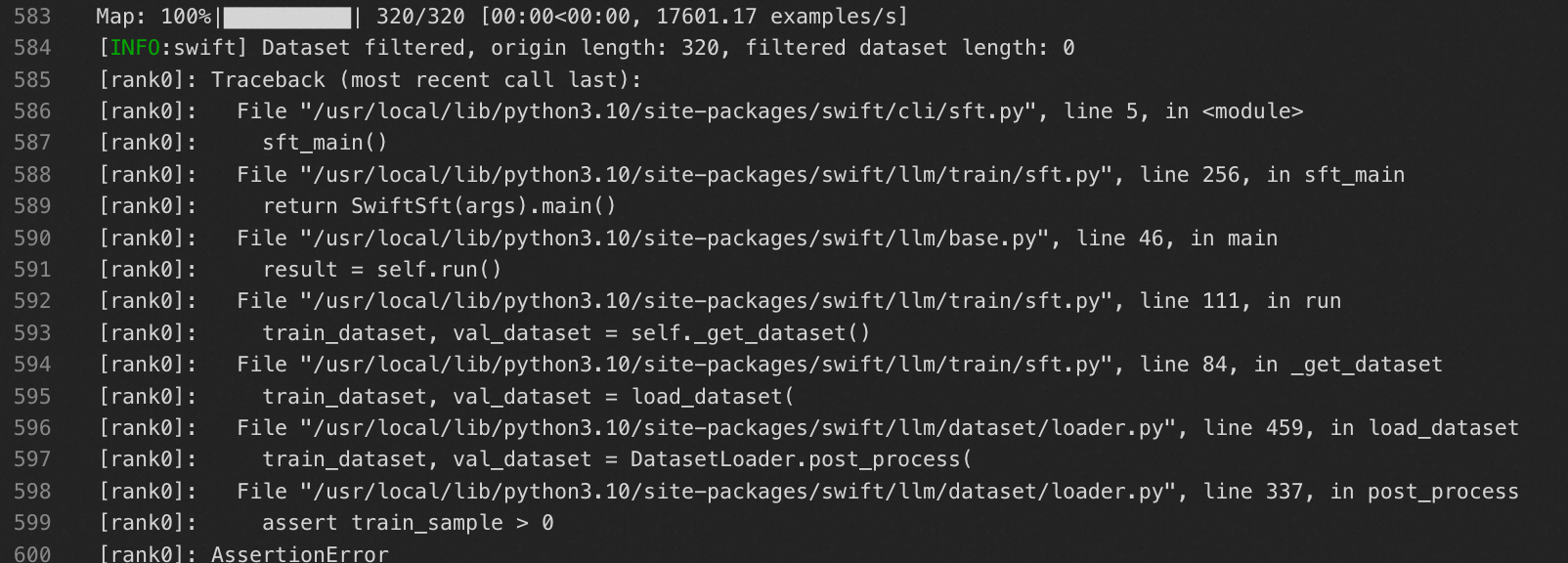
出现以下错误日志:failed to compose dlc job specs, resource limiting triggered, you are trying to use more GPU resources than the threshold,是因为训练任务当前限制最多同时运行2*GPU,超过会触发资源限制。请等待正在运行中的训练任务完成再启动,或提交工单申请增加配额。
出现以下错误日志:the specified vswitch vsw-**** cannot create the required resource ecs.gn7i-c32g1.8xlarge, zone not match。这是因为部分规格在交换机所在可用区没有资源了。您可以尝试以下方式解决:1. 不选择交换机(DLC后端会自己根据库存选择对应可用区的交换机)2. 切换其他资源规格。
训练后模型可以下载么?
创建训练任务时,支持设置模型输出路径到OSS目录,然后您可以从OSS下载到本地。
