
本文以公开的金融交易领域数据集为例,基于云原生数据库PolarDB的图分析,针对金融交易欺诈检测场景进行图查询,以发现欺诈交易的关联关系,计算交易间的Jaccard相似度,从而进行欺诈预警。
关于图数据库引擎
图分析是数据科学中的一个重要领域,专注于通过图结构表示数据,并执行各种计算与分析任务。图结构由节点(或称为顶点)和边组成,节点通常代表实体,而边则表示实体之间的关系。图计算广泛应用于社交网络分析、推荐系统、知识图谱、路径优化等多个领域。
PolarDB PostgreSQL版高度兼容Apache AGE的图引擎,支持对知识图谱的存储和查询检索,能够在同一个数据库集群上同时使用标准的ANSI SQL和图查询语言openCypher进行查询。
完全兼容PolarDB PostgreSQL版
AGE是PolarDB PostgreSQL版的一个扩展,可以在现有的PolarDB数据库中使用,且无需重新构建数据库。AGE继承了PolarDB所有强大功能,包括事务、并发控制、以及多种索引和优化技术。
统一的图形和关系型查询
AGE允许同时处理关系型数据和图形数据,支持在同一个查询中混合使用SQL和图查询语言,使得处理复杂的数据模型更加容易和高效。
支持Cypher查询语言
AGE支持使用Cypher查询语言。Cypher查询语言专为图数据库设计,语法简单且灵活,提供了一种直观的方式来进行图数据的查询和操作。
高性能
结合PolarDB的优化技术和专为图数据设计的索引,AGE能够高效地处理大规模图形数据和复杂的图形查询。
综上, 借助于AGE强大的能力,PolarDB可以简单、高效地处理各类图查询。

业务场景
场景描述
在现代欺诈及各类金融犯罪中,欺诈者通过改变自身身份等手段以实现逃避风控规则的目的。通过构建图数据库以追踪用户行为的图结构,实时分析欺诈行为的离散数据,识别欺诈环,从而能够快速有效地防范和解决欺诈行为。
数据和模型
数据来源于金融交易领域的公开数据集。该数据是为电商平台Vesta提供的交易记录,包括交易相关的设备、地址、邮箱等信息。通过该数据集可以识别欺诈交易,并进行风险预测。
原始数据为CSV格式,包含交易信息(交易号,地址,邮箱等)以及交易识别信息(设备信息,设备类型等),数据集包含了众多的信息,本文中将数据模型抽象为下图,实际业务场景可根据实际情况进行调整:

点
transaction(交易)product(交易产品)addr1(交易地址1)addr2(交易地址2)emaildomain(交易时使用的邮箱域名)deviceinfo(交易设备信息)devicetype(交易设备类型)
边
transaction_product(交易与产品关系)transaction_addr1(交易与地址1关系)transaction_addr2(交易与地址2关系)transaction_emaildomain(交易与邮箱域名关系)transaction_deviceinfo(交易与设备信息关系)transaction_devicetype(交易与设备类型关系)
以上模型以交易为中心,通过交易号(transactionid)进行关联。
最佳实践
本案例使用AGE项目提供图数据可视化工具,将查询结果进行图形化的表达。详情请参考可视化工具。
建议配置
为了得到良好的体验,PolarDB集群建议使用以下配置:
产品版本:标准版
数据库引擎:PostgreSQL 14
内核版本:>=14.12.23.1
CPU:>= 4 核
内存:>= 16 GB
磁盘:>= 100 GB
数据库准备
使用高权限账号安装插件。
CREATE EXTENSION age;将插件加入需要使用此插件的数据库或用户的搜索路径和预加载库中。
会话级加载插件:
说明使用数据管理 DMS(Data Management)客户端设置
search_path时,可能会存在兼容性问题,您可使用PolarDB-Tools执行相关语句。SET search_path = ag_catalog, "$user", public; SELECT * FROM get_cypher_keywords() limit 0;永久加载插件:
ALTER DATABASE <dbname> SET search_path = ag_catalog, "$user", public; ALTER DATABASE <dbname> SET session_preload_libraries TO 'age';
数据入库
创建图。使用位于
ag_catalog命名空间中的create_graph函数创建图(此处以fraud_graph为例)。SELECT create_graph('fraud_graph');插入节点和边。由于下载的数据为CSV文件,无法直接作为点边结构的图数据进行入库。请联系我们获取将数据转换为PolarDB中的vertex和edge的Python脚本,转换结果如下所示:
部分点数据
SELECT * FROM cypher('fraud_graph', $$ MERGE (v:transaction {transactionid : 2990783, isfraud : 0 } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:product {productid : 158945 } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:addr1 {addr1 : '299.0' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:addr2 {addr2 : '87.0' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:emaildomain {emaildomain : 'gmail.com' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:deviceinfo {deviceinfo : 'SM-G920V Build/NRD90M' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:devicetype {devicetype : 'mobile' } ) RETURN v $$ ) as (n agtype); ...部分边数据
SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:product) WHERE a.transactionid = 2990783 AND b.productid = 158945 MERGE (a)-[e:transaction_product]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:addr1) WHERE a.transactionid = 2990783 AND b.addr1 = '299.0' MERGE (a)-[e:transaction_addr1]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:addr2) WHERE a.transactionid = 2990783 AND b.addr2 = '87.0' MERGE (a)-[e:transaction_addr2]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:emaildomain) WHERE a.transactionid = 2990783 AND b.emaildomain = 'gmail.com' MERGE (a)-[e:transaction_emaildomain_p]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:deviceinfo) WHERE a.transactionid = 2999403 AND b.deviceinfo = 'SM-G920V Build/NRD90M' MERGE (a)-[e:transaction_deviceinfo]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:devicetype) WHERE a.transactionid = 2999404 AND b.devicetype = 'mobile' MERGE (a)-[e:transaction_devicetype]->(b) RETURN e$$) as (e agtype); ...
将转换后的结果保存为SQL文件,配合客户端工具,如psql等可完成数据导入。
使用示例
简单查询
数据统计
统计各种类型节点数量。
SELECT * FROM cypher('fraud_graph', $$ MATCH (n) RETURN count(*) $$) as (number_of_vertex agtype);返回结果如下:
number_of_vertex ---- 1076004统计
transaction节点数量。SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction) RETURN count(*) $$) as (number_of_transaction agtype);返回结果如下:
number_of_transaction ---- 545591数据中标识为欺诈交易的数量。
SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction) WHERE n.isfraud = 1 RETURN count(*) $$) as (number_of_fraud_transaction agtype);返回结果如下:
number_of_fraud_transaction ---- 18919统计边数量。
SELECT * FROM cypher('fraud_graph', $$ MATCH ()-[r]->() RETURN count(*) $$) as (number_of_edge agtype);返回结果如下:
number ------ 2131254
过滤查询、排序查询
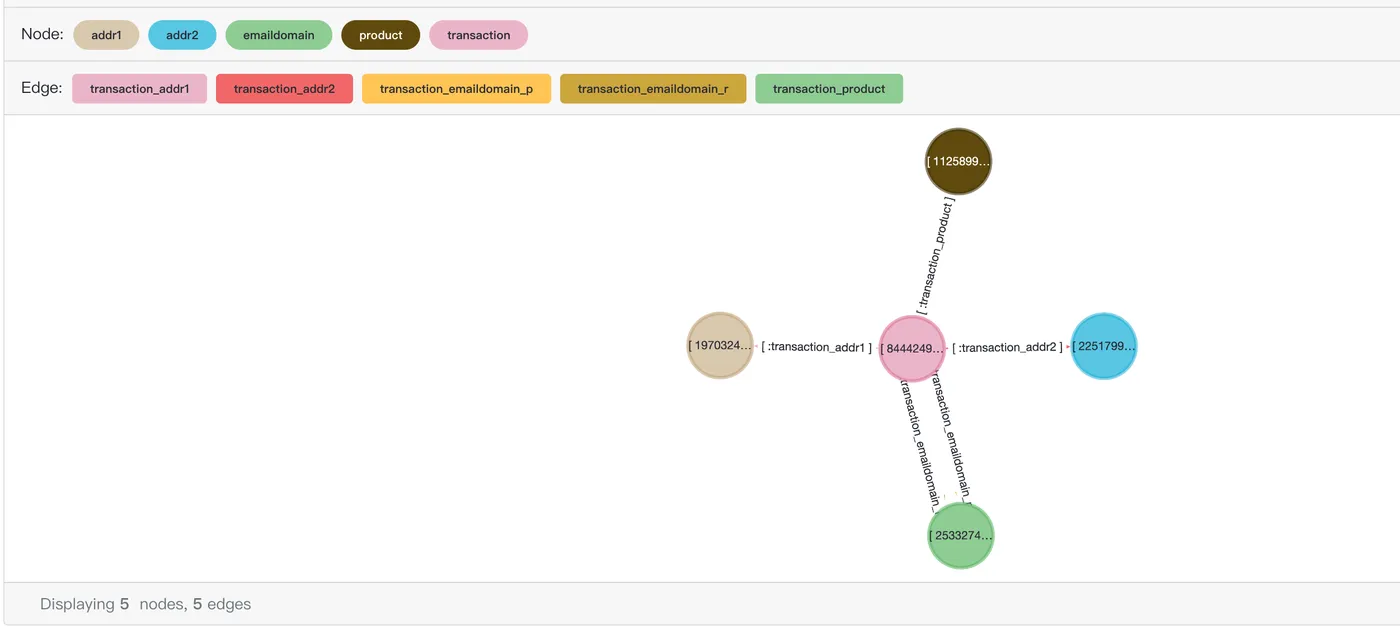
查询ID为2988706的交易信息及所有的关联信息。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)
WHERE n.transactionid = 2988706
RETURN v
$$) as (e agtype);返回结果如下:
e
---------
{"id": 2251799813685249, "label": "addr2", "properties": {"addr2": "87.0"}}::vertex
{"id": 2533274790395906, "label": "emaildomain", "properties": {"emaildomain": "gmail.com"}}::vertex
{"id": 2533274790395906, "label": "emaildomain", "properties": {"emaildomain": "gmail.com"}}::vertex
{"id": 1970324836974595, "label": "addr1", "properties": {"addr1": "325.0"}}::vertex
{"id": 1125899906844295, "label": "product", "properties": {"productid": 137934}}::vertex在可视化工具age-viewer中使用该SQL预览结果如下:
通用场景
K阶邻居
K阶邻居(k-nearest neighbors,KNN)方法利用数据节点之间的相似性,来识别潜在的欺诈行为。K阶邻居可以帮助评价数据节点之间的相似性。通过寻找与该数据节点特征相似的K个邻居,可以判断该节点是否正常。例如,一个交易如果与大多数邻居(交易节点)在金额、地点、时间等特征上存在显著差异,可能会被标记为可疑。
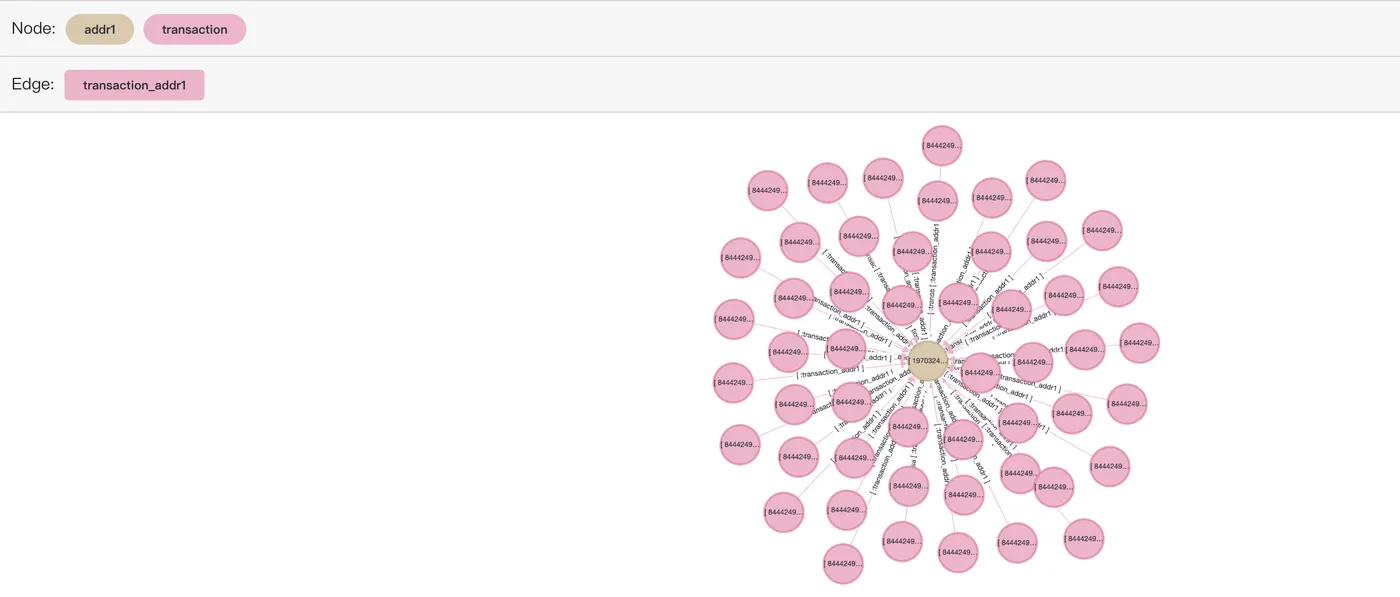
查询和交易记录2988706有相同地址的其他交易(2阶邻居)记录。后续可以根据这些邻居的相关信息来对这个交易的可疑性进行判别。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[:transaction_addr1]->(:addr1)<-[:transaction_addr1]-(t:transaction)
WHERE n.transactionid = 2988706
RETURN t
$$) as (e agtype);返回结果如下:
e
-----
{"id": 844424930131972, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987001}}::vertex
{"id": 844424930131978, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987007}}::vertex
{"id": 844424930132041, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987070}}::vertex
{"id": 844424930132053, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987082}}::vertex
....在可视化工具age-viewer中使用以下SQL预览结果:
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r:transaction_addr1]->(a:addr1)<-[r2:transaction_addr1]-(t:transaction)
WHERE n.transactionid = 2988706
RETURN [n,r,a,r2,t]::path
LIMIT 50
$$) as (e agtype);仅返回50条记录,过多的数据量可能导致前端系统崩溃。
路径检索
在欺诈交易识别中,路径的概念主要体现在利用图论和网络分析的方法来识别潜在的欺诈行为。在金融交易和网络中,交易往往可以视为一个图,节点代表账户或客户,边代表交易活动。通过分析这个图的结构,可以发现一些异常模式和欺诈行为。通过计算交易之间的路径,可以快速识别从一个可疑账户到其他账户的交易链,有助于揭示看似不相关的账户之间的隐秘联系。
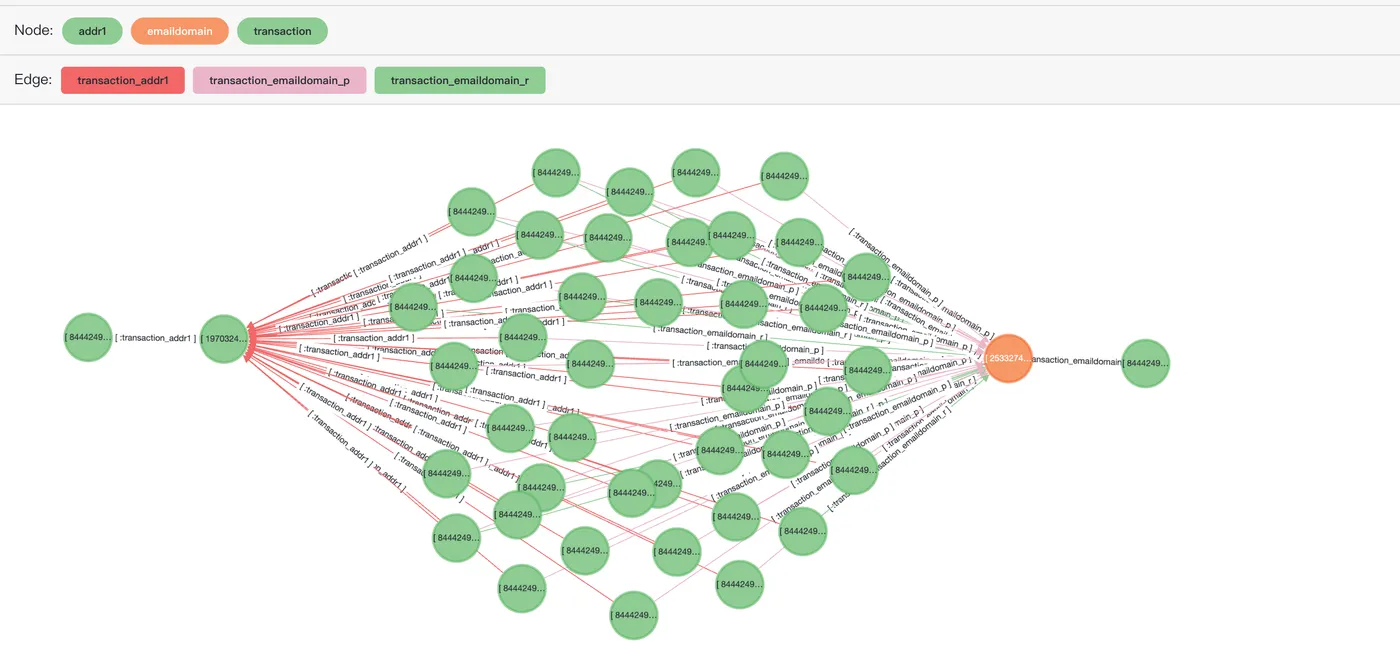
查询交易记录2987000和交易记录2987172基于某个虚假交易的关联路径,从两个看似没有直接关系的交易中找出关联的所有虚假交易链路。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)<-[r1]-(t:transaction)-[r2]->(v2)<-[r3]-(k:transaction)
WHERE n.transactionid = 2987000
and k.transactionid=2987172
and t.isfraud = 1
RETURN t
$$) as (e agtype);返回结果如下:
e
----
{"id": 844424930618281, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3473312}}::vertex
{"id": 844424930626886, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3481917}}::vertex
{"id": 844424930649640, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3504671}}::vertex
{"id": 844424930631805, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3486836}}::vertex
{"id": 844424930641980, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3497011}}::vertex
{"id": 844424930644942, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3499973}}::vertex在可视化工具age-viewer中使用以下SQL预览结果:
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)<-[r1]-(t:transaction)-[r2]->(v2)<-[r3]-(k:transaction)
WHERE n.transactionid = 2987000
and k.transactionid=2987172
and t.isfraud = 1
RETURN [n,r,v,r1,t,r2,v2,r3,k]::path
LIMIT 50
$$) as (e agtype);仅返回50条记录,过多的数据量可能导致前端系统崩溃。
共同邻居
在欺诈交易识别中,共同邻居判断(Common Neighbor Judgment)是一种基于社交网络或交易网络分析的技术,用于识别可能的欺诈行为。该方法主要基于图论的基础,通过分析交易参与者之间的关系网络,寻找可能的可疑交易模式。如果两个交易有多个共同邻居,而这些邻居在交易行为上存在异常(例如高频率的交易、异常金额等),则这两个交易者之间的交易可能存在欺诈风险。
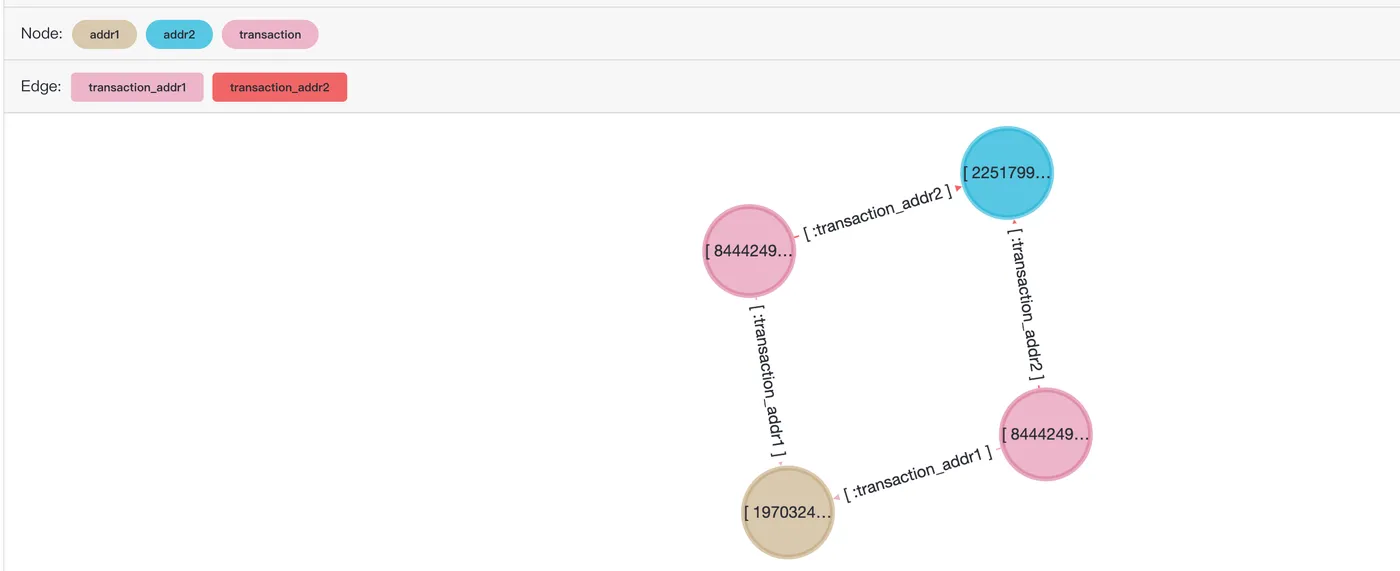
查询交易记录2987000和交易记录2987172的共同邻居,从而找到具备相同属性(地址、设备)的交易记录。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[]->(v)<-[]-(t:transaction)
WHERE n.transactionid = 2987000 and t.transactionid=2987172
RETURN v
$$) as (e agtype);返回结果如下:
e
-----
{"id": 2251799813685249, "label": "addr2", "properties": {"addr2": "87.0"}}::vertex
{"id": 1970324836974594, "label": "addr1", "properties": {"addr1": "315.0"}}::vertex在可视化工具age-viewer中使用该SQL预览结果如下:
Jaccard相似度
Jaccard相似度用于衡量两个集合之间的相似性,其公式为:
其中:
J(A,B)是集合A和B的Jaccard相似度。∣A∩B∣是集合A和B的交集。∣A∪B∣是集合A和B的并集。
在欺诈识别中,Jaccard相似度可以有多种用途,如:
模式识别:欺诈行为往往表现出一些共性特征。通过计算用户交易或行为的Jaccard相似度,可以识别出相似的交易模式,从而帮助检测潜在的欺诈活动;
客户群体分析:在分析客户的行为时,可以利用Jaccard相似度来比较不同客户之间的相似性。相似度较高的客户可能存在相似的风险特征。
在本示例中,两个交易可以根据其关联的地址,邮箱以及地址等信息计算其Jaccard相似度,如果关联的信息重叠度很大,则说明交易的相似度很高。
创建以下函数。
用于获取特定交易的所有关联节点,返回所有点的ID数组。
CREATE OR REPLACE FUNCTION find_ids(transactionid integer) RETURNS bigint[] LANGUAGE plpgsql AS $function$ DECLARE sql VARCHAR; ids bigint[]; BEGIN sql := 'SELECT array_agg(cast(e as bigint)) FROM ( SELECT * FROM cypher(''fraud_graph'', $$ MATCH (n:transaction)-[]->(v) WHERE n.transactionid = ' || text($1) || 'RETURN id(v) $$) as (e agtype)) as t;'; EXECUTE sql INTO ids; return ids; END $function$;两个函数,用于对数组进行
Union和Intersection的操作。CREATE OR REPLACE FUNCTION array_union(anyarray, anyarray) RETURNS anyarray LANGUAGE sql immutable AS $$ SELECT array_agg(a ORDER BY a) FROM ( SELECT DISTINCT unnest($1 || $2) AS a ) s; $$; CREATE OR REPLACE FUNCTION array_intersection(anyarray, anyarray) RETURNS anyarray LANGUAGE sql immutable AS $$ SELECT array_agg(e) FROM ( SELECT unnest($1) INTERSECT SELECT unnest($2) ) AS dt(e) $$;用于计算两个交易的Jaccard相似度。
CREATE OR REPLACE FUNCTION jaccardSimilarity(tid1 integer, tid2 integer) RETURNS float8 LANGUAGE plpgsql AS $function$ DECLARE sql VARCHAR; ids1 bigint[]; ids2 bigint[]; union_list bigint[]; intersection_list bigint[]; BEGIN ids1 = find_ids($1); ids2 = find_ids($2); union_list = array_union(ids1, ids2); -- union intersection_list = array_intersection(ids1, ids2); -- intersection RETURN CASE WHEN array_length(union_list,1) = 0 THEN 0 ELSE array_length(intersection_list,1) * 1.0/ array_length(union_list,1) END AS jaccardSimilarity; END $function$;
执行函数进行Jaccard相似度计算。
对指定的两个交易ID进行相似度对比:
SELECT jaccardSimilarity(2987000, 2987172);返回结果如下:
jaccardsimilarity ---- 0.4
如果需要对所有的交易进行相似度对比,可以充分利用
PolarDB的存储过程能力,完成更为复杂的相似度计算任务,从而满足检测欺诈交易的需求。例如,可以使用以下SQL找出与交易2987002具有相同地址1、地址2和邮箱域名的所有交易并按照jaccard相似度进行排序,找出相似度最大的50个交易:
WITH tmp AS (SELECT cast(e as integer) as transactionid FROM cypher('fraud_graph', $$ MATCH (n:transaction)-[:transaction_addr2]->(:addr2)<-[:transaction_addr2]-(t:transaction) WHERE n.transactionid = 2987002 MATCH (n:transaction)-[:transaction_addr1]->(:addr1)<-[:transaction_addr1]-(t:transaction) WHERE n.transactionid = 2987002 MATCH (n:transaction)-[:transaction_emaildomain_p]->(:emaildomain)<-[:transaction_emaildomain_p]-(t:transaction) WHERE n.transactionid = 2987002 RETURN t.transactionid $$) as (e agtype) ) SELECT transactionid, jaccardSimilarity(2987002, transactionid) as jaccardSimilarity FROM tmp ORDER by jaccardSimilarity DESC LIMIT 50;返回结果如下:
transactionid | jaccardsimilarity ---------------+------------------- 3323911 | 0.6 3328911 | 0.6 3009043 | 0.6 3039416 | 0.6 3039425 | 0.6 2993652 | 0.6 3045027 | 0.6 3037644 | 0.6 3045041 | 0.6 ...在可视化工具
age-viewer中使用以下SQL预览结果如下(结果已在之前的计算中完成,现仅取前10项。如有需要,您可以自行将其放入list中):SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction)-[r]->(v)<-[r2]-(t:transaction) WHERE n.transactionid = 2987002 AND t.transactionid IN [3323911, 3328911,3009043,3039416,3039425,2993652,3045027,3037644,3045041,3045049,3045279] RETURN [n,r,v,r2,t]::path $$) as (e agtype);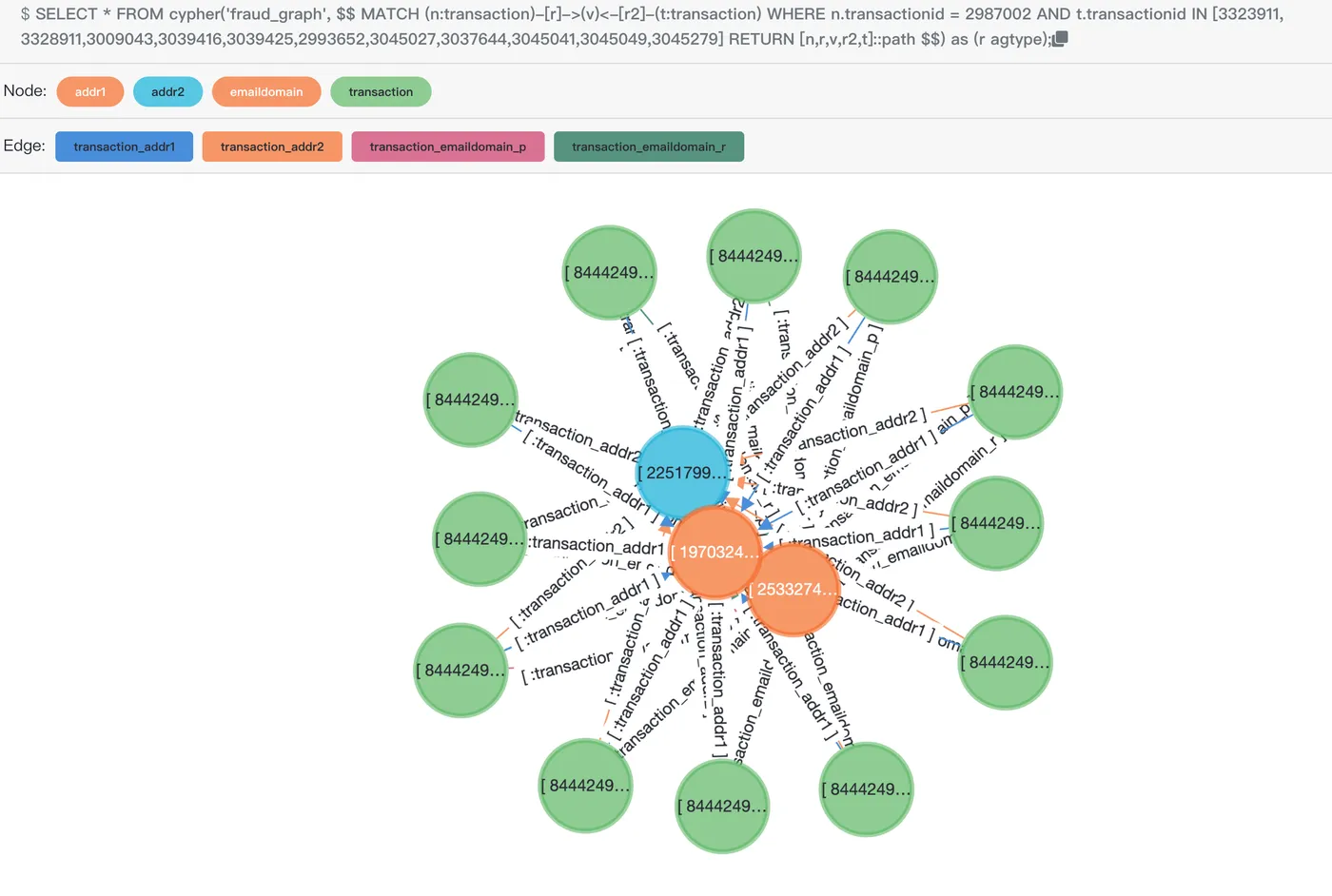
总结
利用PolarDB PostgreSQL版的图分析能力进行图数据分析。PolarDB结合AGE扩展,提供图数据计算分析的功能,包括使用Cypher查询语言,高效处理查询图数据,为企业的统一数据管理和分析,提供强有力的支撑。
试用体验
您可以访问PolarDB免费试用页面,选择试用“云原生数据库PolarDB PostgreSQL版”,体验Ganos的图计算能力。