
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
日志服务提供下探分析功能,用于对多维时序进行自动化、智能化的根因定位。您可以根据根因定位的结果,判断是时序数据的哪些维度(单个维度和若干维度的组合)异常导致的问题,缩小问题排查范围。本文介绍创建下探分析作业的操作步骤。
前提条件
操作步骤
登录日志服务控制台。
进入创建作业页面。
在日志应用区域的智能运维页签,单击智能异常分析。
在实例列表中,单击目标实例。
在左侧导航栏,选择其他任务 > 下探分析。
在下探分析任务区域,单击立即创建。
在创建下探分析作业配置向导的基础信息步骤中,完成如下配置,然后单击下一步。
参数
说明
任务名
设置下探分析作业的名称。
角色
如果您在创建实例时已完成授权,则此处自动显示AliyunLogETLRole角色的角色标识。
日志库
目标日志库,固定为internal-ml-log。
在创建下探分析作业配置向导的数据配置步骤中,完成指标数据配置和事件源配置。
在指标数据配置区域,完成如下配置。
指标数据的配置用于抽取多维指标序列。
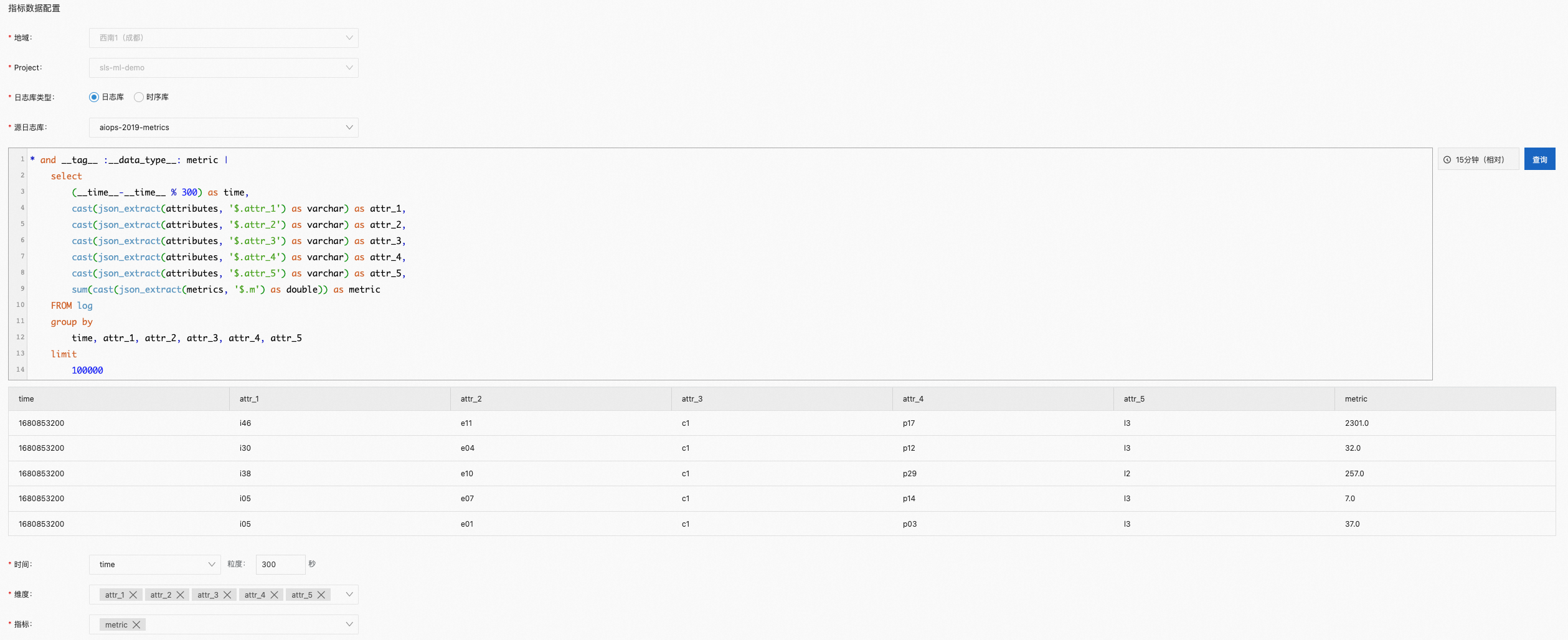
对应的查询和分析语句示例如下所示。更多信息,请参见查询概述、分析概述。
* and __tag__ :__data_type__: metric | select (__time__-__time__ % 300) as time, cast(json_extract(attributes, '$.attr_1') as varchar) as attr_1, cast(json_extract(attributes, '$.attr_2') as varchar) as attr_2, cast(json_extract(attributes, '$.attr_3') as varchar) as attr_3, cast(json_extract(attributes, '$.attr_4') as varchar) as attr_4, cast(json_extract(attributes, '$.attr_5') as varchar) as attr_5, sum(cast(json_extract(metrics, '$.m') as double)) as metric FROM log group by time, attr_1, attr_2, attr_3, attr_4, attr_5 limit 100000参数
说明
地域
展示您所选择的Project的所在地域,选择Project后显示。
Project
选择日志库或时序库所在的Project。
日志库类型
根据多维指标数据的存储位置,选择日志库类型。
如果您的多维指标数据存储在日志库中,则选中日志库。
如果您的多维指标数据存储在时序库中,则选中时序库。
源日志库
当日志库类型设置为日志库时,需选择目标源日志库,即设置为您的多维指标数据所在的日志库。
时序库
当日志库类型设置为时序库时,需选择目标时序库,即设置为您的多维指标数据所在的时序库。
时间
源数据中表示时间列的字段。建议至少以分钟级别以上的粒度对数据进行聚合。
粒度
拉取源数据的时间间隔,单位为秒。建议是数据聚合粒度的整倍数。
维度
源数据中表示数据维度的字段。
指标
源数据中表示数据指标的字段。
聚合
当添加了多个指标时,需设置聚合操作的表达式。
(可选)在事件数据配置区域,单击添加事件配置。
事件数据的配置用于抽取事件序列。
说明您可以单击添加事件配置,添加多个事件数据配置。
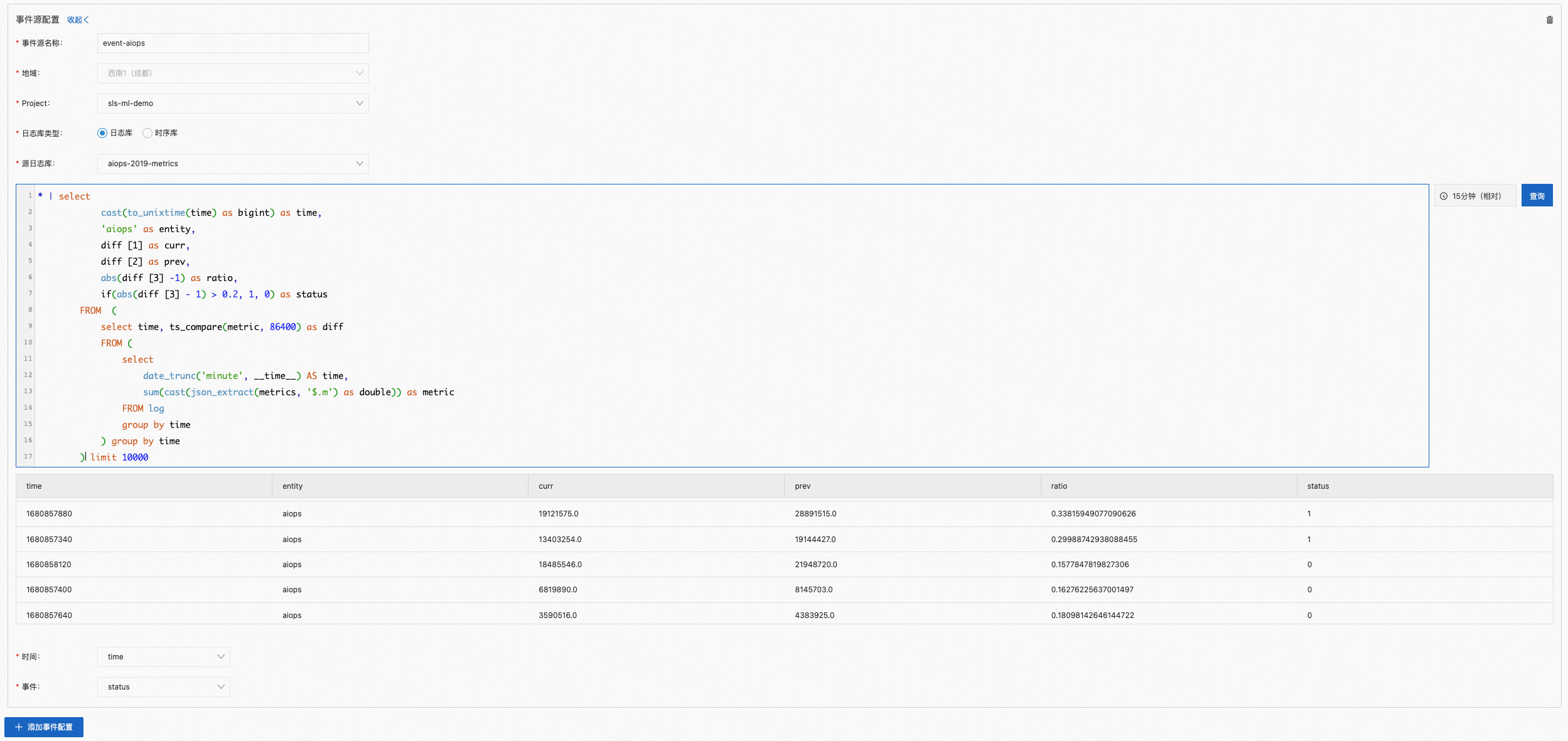
对应的查询和分析语句示例如下所示。更多信息,请参见查询概述、分析概述。
* | select cast(to_unixtime(time) as bigint) as time, 'aiops' as entity, diff [1] as curr, diff [2] as prev, abs(diff [3] -1) as ratio, if(abs(diff [3] - 1) > 0.2, 1, 0) as status FROM ( select time, ts_compare(metric, 86400) as diff FROM ( select date_trunc('minute', __time__) AS time, sum(cast(json_extract(metrics, '$.m') as double)) as metric FROM log group by time ) group by time ) limit 10000参数
说明
事件源名称
设置事件源名称。
地域
展示您所选择的Project的所在地域,选择Project后显示。
Project
选择日志库或时序库所在的Project。
日志库类型
根据事件数据存储的位置选择日志库类型。
如果您的事件数据存储在日志库中,则选中日志库。
如果您的事件数据存储在时序库中,则选中时序库。
源日志库
当日志库类型设置为日志库时,需选择目标源日志库,即设置为您的事件数据所在的日志库。
时序库
当日志库类型设置为时序库时,需选择目标时序库,即设置为您的事件数据所在的时序库。
时间
源数据中表示时间的字段。
事件
源数据中表示事件的字段。
当事件列的值为正数或者true时,表示触发异常事件。
单击下一步。
在创建下探分析作业配置向导的算法配置步骤中,配置下探分析算法参数和作业的调度时间,然后单击完成。

参数
说明
观测长度
表示最近时序数据点的个数。下探分析作业将根据您所设置的观测长度去预测下一个时序数据点的值,即期望值。例如设置为5,则表示通过最近5个时序数据点预测下一个时序数据点的值。
下探分析作业会根据每一种维度组合对应的指标值与期望值的偏离程度,判断该维度组合是否是异常事件的根因。
置信度
一般情况下,设置的置信度越高,作业分析的数据将越多,找到的根因越准确,但是算法运行的时间也会越长。
数据延迟
数据写入到日志库的最大延迟,一般情况下,设置为30秒或者60秒。
时间范围
设置下探分析作业的开始时间。
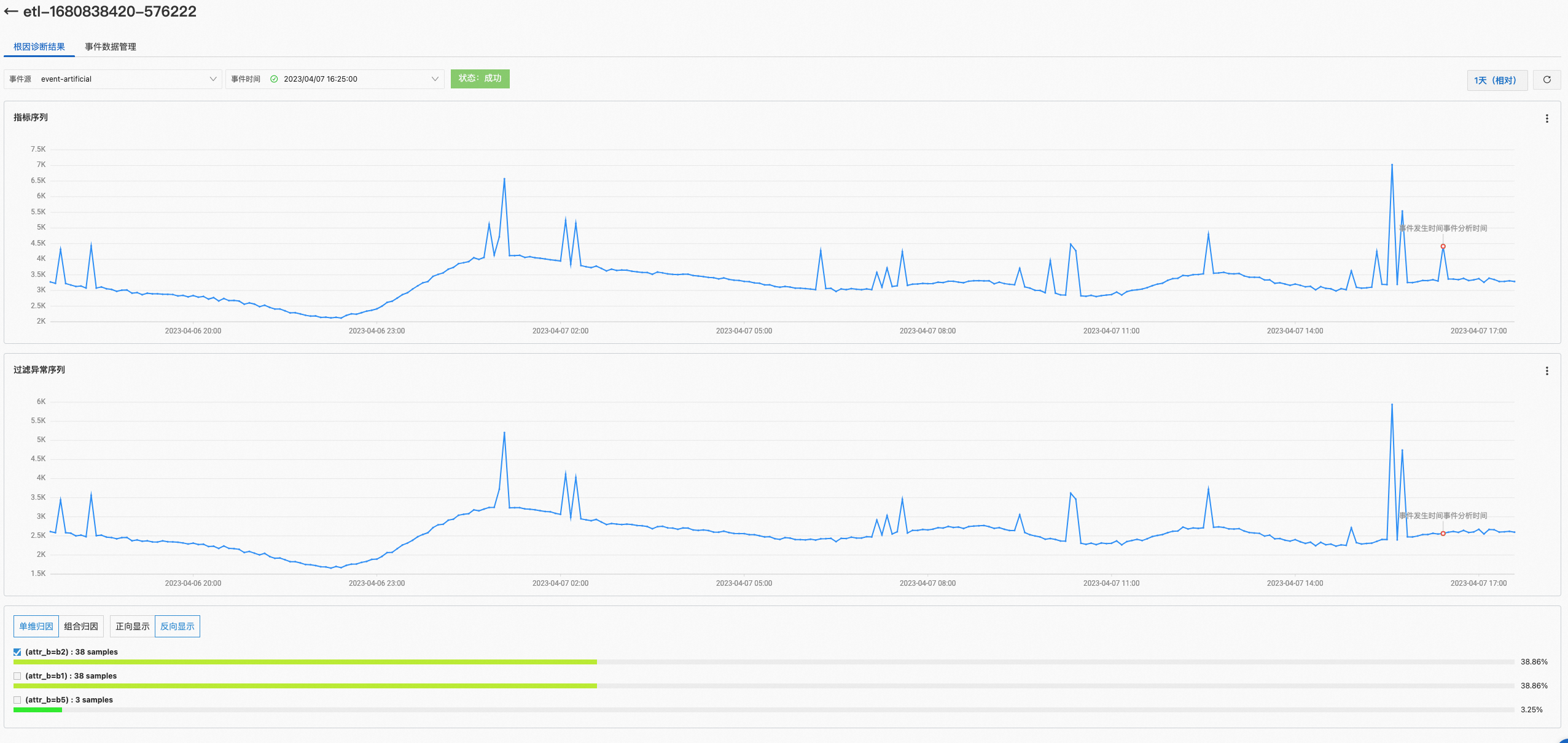
分析结果
创建下探分析作业后,您可以在作业列表中,单击目标作业,查看下探分析作业详情。您可以通过事件源、事件时间和时间筛选,查看目标事件的根因分析结果。
筛选条件 | 说明 |
时间 | 通过时间筛选,您可以查看下探分析作业在对应时间段的分析结果。 |
事件源 | 通过事件源筛选对应的事件。 |
事件时间 | 通过事件发生的时间,查看对应的事件。 |
确定要查看的事件后,下方会展示对应事件可能的根因候选项,您可以通过勾选这些候选项,查看这个候选项对于指标序列的影响。
相关操作
修改下探分析作业
创建下探分析作业后,您可以在下探分析作业列表中,找到目标下探分析作业,单击对应的
 图标,修改该作业。
图标,修改该作业。删除下探分析作业
创建下探分析作业后,您可以在下探分析作业列表中,找到目标下探分析作业,单击对应的
 图标,删除该作业。警告
图标,删除该作业。警告下探分析作业被删除后,不可恢复,请谨慎操作。
管理事件源
创建下探分析作业后,您可以在下探分析作业列表中,单击下探分析作业,然后在事件数据管理页面,新增、删除或者更新事件源。