
本文介绍向量索引的原理,以及在日志服务Project中配置和使用向量索引。
向量索引概述
向量:向量是信息检索和机器学习中的一种技术,旨在高效地存储和检索高维数据(如文本、图像、音频等)。通过将数据(如文本)映射到高维空间的一个点,使得语义相似的文本在高维空间中距离相近。在高维空间中,每一个数据点用一个高维向量表示,每个维度代表一个特征。
向量嵌入(Embedding):embedding指的是把文本或者图片等多模块数据映射到高维向量空间的过程。
距离度量:使用距离度量(如欧氏距离、余弦相似度等)来量化向量之间的相似性。
向量索引:使用数据结构(如树形结构、哈希表等)构建索引,以提高搜索效率。例如,常见的向量索引包括HNSW,IVF等。
SLS向量索引的优势
日志服务是一个一站式日志数据分析平台,解决日志数据的采集、处理、存储、检索分析的需求。大语言模型的兴起,对自然语言的搜索需求陡增。例如对用户问答数据,Agent和LLM的交互日志,有审计、检索、分析的需求。 为了解决大语言模型领域的语义搜索需求,日志服务推出了向量索引功能。
日志服务SLS向量索引的优势:
一站式的向量嵌入 - 索引构建:在传统的解决方案中,用户需要维护向量嵌入和向量数据库两个系统。SLS合二为一,用户无需维护复杂的架构,只需要选择嵌入模型即可。
低成本:基于SLS托管的向量模型。
简单的搜索语法SPL:业界普遍采用JSON方式来描述搜索语法;SLS自研similarity和topk语法,在搜素框输入即可完成查询,无需填写复杂的JSON和一大堆参数。
管道语法无缝对接rerank和SQL计算:搜索出来的结果,经过管道,可以使用SPL语言调用rerank模型进行rerank;也可以对接SQL计算,对搜索出来的结果进行统计操作。
支持地域
向量索引仅限于中国内地使用,不适用于海外区域。
配置向量索引
前提条件
已创建Project、标准型Logstore并完成日志采集配置。具体操作,请参见管理Project、创建基础Logstore和数据采集概述。
已创建全文索引和字段索引,更多信息,请参见创建索引。
操作步骤
登录日志服务控制台。在Project列表区域,单击目标Project。
在页签中,单击目标Logstore。
单击。在查询分析面板中,向量索引默认不开启,选择对应的embedding模型后,自动开启向量索引。
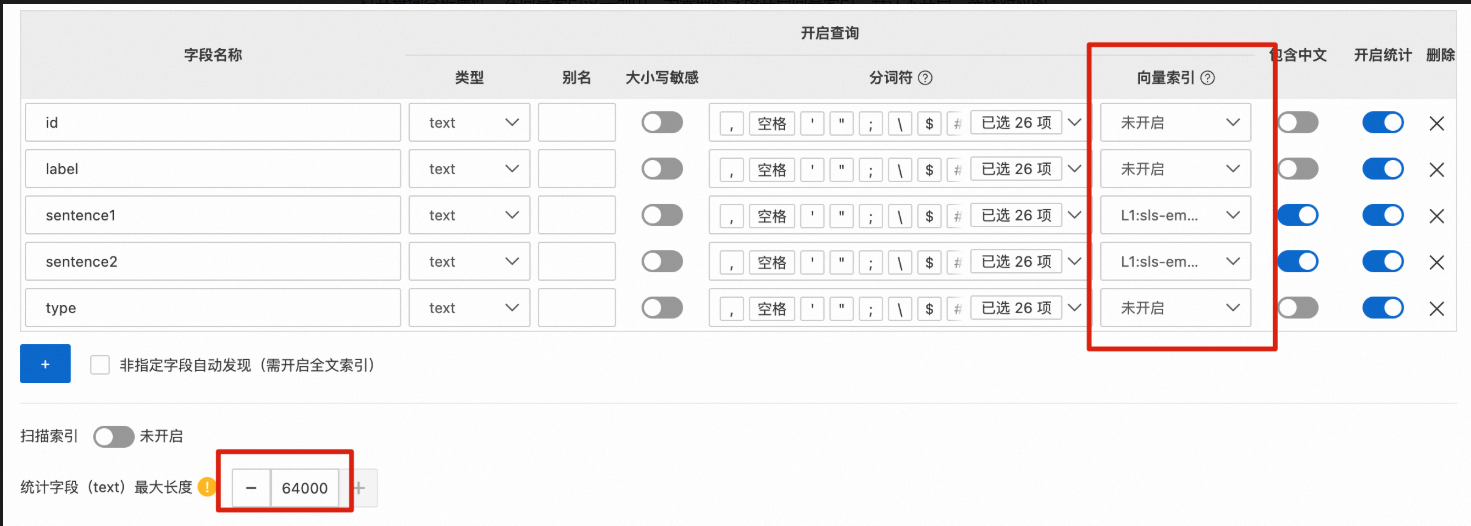
查询注意事项
开启向量索引后,只对新数据生效。
向量索引不支持重建索引。
由于构建向量索引有延迟,新数据写入5分钟后才可以查询。请注意该时间限制。
由于缓存作用,若遇到查询结果不准确,可在查询条件前加上
not abcdefg and规避缓存。中间的可为任意随机数。向量索引依赖于统计功能,请开启右侧的统计开关。由于自然语言一般是长文本,请把统计字段最大值调整到最大(控制台可调整到16KB,使用SDK可调整到64KB)。
模型参数解析
L1:sls-embed-i512-o512-q4-1:该模型代表日志服务托管的模型,输入最大token为512(长度超过512token会自动chunking),输出为512维向量。采用q4量化。embedding模型召回率如下:
数据集
TopK
召回率
MedicalRetrieval
1
46.2
MedicalRetrieval
5
58
MedicalRetrieval
10
63.1
MedicalRetrieval
100
81
VideoRetrieval
1
37.1
VideoRetrieval
5
56.1
VideoRetrieval
10
62.5
VideoRetrieval
100
77.5
CovidRetrieval
1
66.39
CovidRetrieval
5
84.51
CovidRetrieval
10
88.41
CovidRetrieval
100
96.94
sts-sohu2021
1
70.59
sts-sohu2021
5
94.41
sts-sohu2021
10
97.06
sts-sohu2021
100
99.71
DuRetrieval
1
87.05
DuRetrieval
5
92.95
DuRetrieval
10
94.6
DuRetrieval
100
98.7
T2Retrieval
1
91.2
T2Retrieval
5
95.1
T2Retrieval
10
97.1
T2Retrieval
100
99
MMarcoRetrieval
1
60.03
MMarcoRetrieval
5
74.87
MMarcoRetrieval
10
79.2
MMarcoRetrieval
100
87.35
CmedqaRetrieval
1
34.46
CmedqaRetrieval
5
53.41
CmedqaRetrieval
10
61.59
CmedqaRetrieval
100
86.27
EcomRetrieval
1
44.9
EcomRetrieval
5
50.1
EcomRetrieval
10
50.2
EcomRetrieval
100
50.3
向量搜索语法
日志服务SLS 搜索向量,支持的是一种召回语法,返回满足条件的数据,结果数据按照日志时间顺序排序,而不是按照相似度排序,这种方式大大降低了搜索成本,但不影响最终的准确率。因为一般而言,向量的搜索结果需要使用rerank模型进行二次rerank,以提升准确率,所以我们推荐客户对搜索的结果进行二次rerank。
SLS的向量召回语法支持两种模式过滤:按照距离过滤和按照topk过滤。
按照距离过滤
语法
similarity(字段名, "搜索文本") < 距离
字段名:要搜索的字段,例如msg。
搜索文本:要搜索目标文本,例如"番茄鸡蛋"。
距离:距离范围从0到1,距离越小表示越相似。0表示最相似,1表示最不相似。
使用示例
similarity("input_semantic.topic","教育") < 0.1表示搜索input_semantic.topic字段中跟“教育”相关,距离在0.1以内的数据。
按照topk过滤
语法
topk(字段名, "搜索文本") = $k
topk中的$k表示每个文件的topk。多个文件不会进行合并。因此最终搜出来的结果条数可能大于要求的$k。用户需要把搜索结果进行二次rerank。
字段名:要搜索的字段,例如msg。
搜索文本:要搜索的目标文本,例如“番茄鸡蛋”。
返回的数量$k: 大于等于1的整数,表示在一个文件内搜索多少个最相似的内容。
使用示例
topk("input_semantic.topic","教育") = 2表示搜索最相似的2个数据。
多向量检索
向量检索支持在一个查询中指定多个向量检索条件,使用or、and、not等逻辑运算连接起来。
在使用多向量搜索时,not算子不可以放在最前边。
使用示例
搜索教育或文化主题的内容:
topk(topic,"教育") = 2 or topk(topic,"文化") =2。搜索教育主题且包含上海市的内容:
topk(topic,"教育") =2 and topk(summary,"上海市") =2。搜索教育主题且不包含上海市的内容:
topk(topic,"教育") =2 not topk(summary,"上海市") =2。
混合检索
SLS支持向量检索和关键字检索混合检索。关键字检索和向量检索可以分别是复杂的查询语句。两者可以通过and、or、not连接起来。
混合检索要求查询语句的一部分是关键字检索,一部分是向量检索,只能包含两部分内容。
两部分内容必须分别用括号括起来。
使用示例
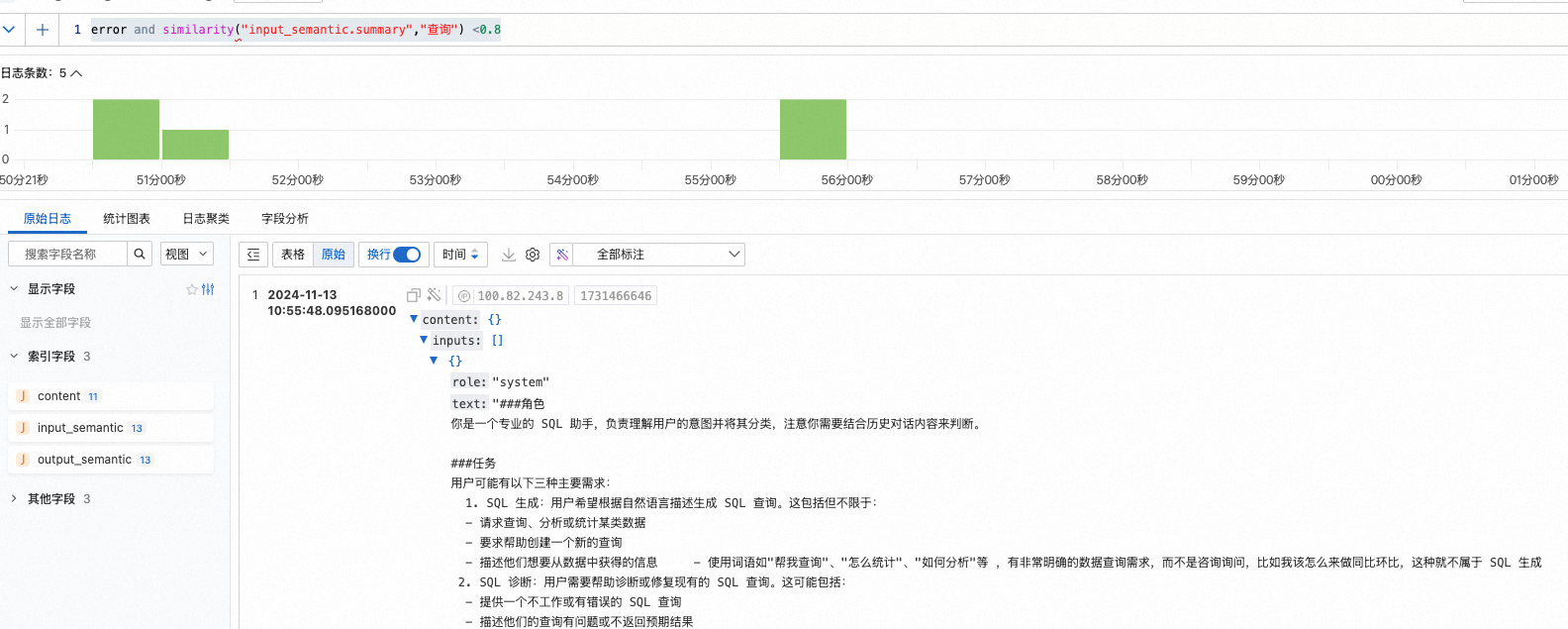
error and similarity("input_semantic.summary","查询") <0.8
( (hello world) and topic:教育) AND (topk(topic,"教育") = 2 or topk(topic,"文化") =2 )
向量聚类
当开启向量索引后,可以基于向量完成聚类,把长文本分成不同的类别。当一个字段开启向量索引后,在SQL/SPL中会增加一个隐藏字段,隐藏字段在原始字段名后增加了__embedding__后缀。例如原始字段是topic,那么新增的向量隐藏字段为topic__embedding__。在SQL中可以使用该字段,该字段的类型为array(float)类型。可以对该字段进行聚类计算。
使用示例
*| set session enable_remote_functions=true;
with t1 as (select sentence1 as x, "sentence1__embedding__" as embd from log having embd is not null limit 1000 ),
t2 as (select cluster(array_agg(embd),'dbscan','{
"n_clusters": "${{cluster_num|5}}",
"max_iter": "100",
"tol": "0.0001",
"metric":"cosine",
"init_mode": "dbscan"
}') as cluster_res, array_agg(x) as xs from t1),
t3 as (select label,x from t2,unnest(cluster_res.assignments,xs) as t(label,x) )
select cast(label as bigint) as "聚类id",array_join(slice((array_agg(x)),1,3),concat(chr(10),'----',chr(10))) as "主题",count(1) as pv from t3 group by label order by pv desc