
本文介绍如何使用阿里云AMD CPU云服务器(g8a)和龙蜥容器镜像,基于通义千问Qwen-VL-Chat搭建个人版视觉AI服务助手。
背景信息
Qwen-VL是阿里云研发的大规模视觉语言模型(Large Vision Language Model)。Qwen-VL可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。在Qwen-VL的基础上,利用对齐机制打造出基于大语言模型的视觉AI助手Qwen-VL-Chat,它支持更灵活的交互方式,包括多图、多轮问答、创作等能力,天然支持英文、中文等多语言对话,支持多图输入和比较,指定图片问答,多图文学创作等。
创建ECS实例
前往实例创建页。
按照界面提示完成参数配置,创建一台ECS实例。
需要注意的参数如下,其他参数的配置,请参见自定义购买实例。
实例:Qwen-VL-Chat模型的推理过程需要耗费大量的计算资源,运行时占用大量内存,为了保证模型运行的稳定,实例规格至少需要选择ecs.g8a.4xlarge(64 GiB内存)。
镜像:Alibaba Cloud Linux 3.2104 LTS 64位。
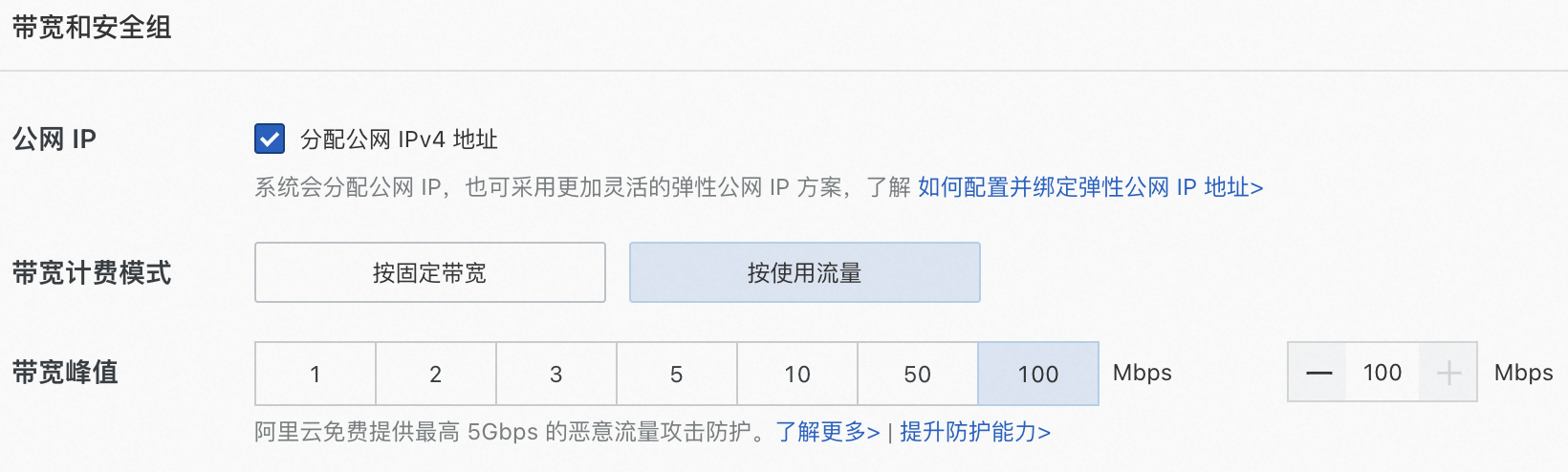
公网IP:选中分配公网IPv4地址,带宽计费模式选择按使用流量,带宽峰值设置为100 Mbps。以加快模型下载速度。
系统盘:Qwen-VL-Chat的运行需要下载多个模型文件,会占用大量存储空间,为了保证模型顺利运行,建议系统盘设置为100 GiB。
添加安全组规则。
在ECS实例安全组的入方向添加安全组规则并放行22、443、7860端口(用于访问WebUI服务)。具体操作,请参见添加安全组规则。
创建完成后,在ECS实例页面,获取公网IP地址。
说明公网IP地址用于进行AI对话时访问WebUI服务。

创建Docker运行环境
远程连接该ECS实例。
具体操作,请参见使用Workbench工具以SSH协议登录Linux实例。
安装Docker。
具体操作,请参见在Alibaba Cloud Linux 3实例中安装Docker。
创建并运行PyTorch AI容器。
龙蜥社区提供了丰富的基于Anolis OS的容器镜像,包括针对AMD优化过的PyTorch镜像,您可以直接使用该镜像创建一个PyTorch运行环境。
以下命令首先拉取容器镜像,随后使用该镜像创建一个以分离模式运行的、名为
pytorch-amd的容器,并将用户的家目录映射到容器中,以保留开发内容。sudo docker pull registry.openanolis.cn/openanolis/pytorch-amd:1.13.1-23-zendnn4.1 sudo docker run -d -it --name pytorch-amd --net host -v $HOME:/root registry.openanolis.cn/openanolis/pytorch-amd:1.13.1-23-zendnn4.1
部署Qwen-VL-Chat
手动部署
步骤一:安装配置模型所需软件
进入容器环境。
sudo docker exec -it -w /root pytorch-amd /bin/bash重要后续命令需在容器环境中执行,如意外退出,请使用以上命令重新进入容器环境。如需查看当前环境是否为容器,可以执行
cat /proc/1/cgroup | grep docker查询(有回显信息则为容器环境)。安装部署Qwen-VL-Chat所需的软件。
yum install -y git git-lfs wget tmux gperftools-libs anolis-epao-release which启用Git LFS。
下载预训练模型需要Git LFS的支持。
git lfs install
步骤二:下载源码与模型
创建一个tmux session。
tmux说明下载预训练模型耗时较长,且成功率受网络情况影响较大,建议在tmux session中下载,以免ECS断开连接导致下载模型中断。
下载Qwen-VL-Chat项目源码。
git clone https://github.com/QwenLM/Qwen-VL.git下载预训练模型。
git clone https://www.modelscope.cn/qwen/Qwen-VL-Chat.git qwen-vl-chat说明由于预训练模型仓库中包含较大文件,因此下载时间较长,请您耐心等待。
查看当前目录。
ls -l下载完成后,当前目录显示如下。

步骤三:部署运行环境
更换pip下载源。
在安装依赖包之前,建议您更换pip下载源以加速安装。
创建pip文件夹。
mkdir -p ~/.config/pip配置pip安装镜像源。
cat > ~/.config/pip/pip.conf <<EOF [global] index-url=http://mirrors.cloud.aliyuncs.com/pypi/simple/ [install] trusted-host=mirrors.cloud.aliyuncs.com EOF
安装Python运行依赖。
pip install tiktoken transformers_stream_generator accelerate gradio transformers modelscope einops "pillow==9.*" torchvision matplotlib设置环境变量
OMP_NUM_THREADS和GOMP_CPU_AFFINITY。ZenDNN运行库需要针对硬件平台显式设置环境变量
OMP_NUM_THREADS和GOMP_CPU_AFFINITY。cat > /etc/profile.d/env.sh <<EOF export OMP_NUM_THREADS=\$(nproc --all) export GOMP_CPU_AFFINITY=0-\$(( \$(nproc --all) - 1 )) EOF source /etc/profile
步骤四:进行AI对话
执行如下命令,开启WebUI服务。
cd ~/Qwen-VL export LD_PRELOAD=/usr/lib64/libtcmalloc.so.4 python3 web_demo_mm.py -c=${HOME}/qwen-vl-chat/ --cpu-only --server-name=0.0.0.0 --server-port=7860当出现如下信息时,表示WebUI服务启动成功。

在浏览器地址栏输入
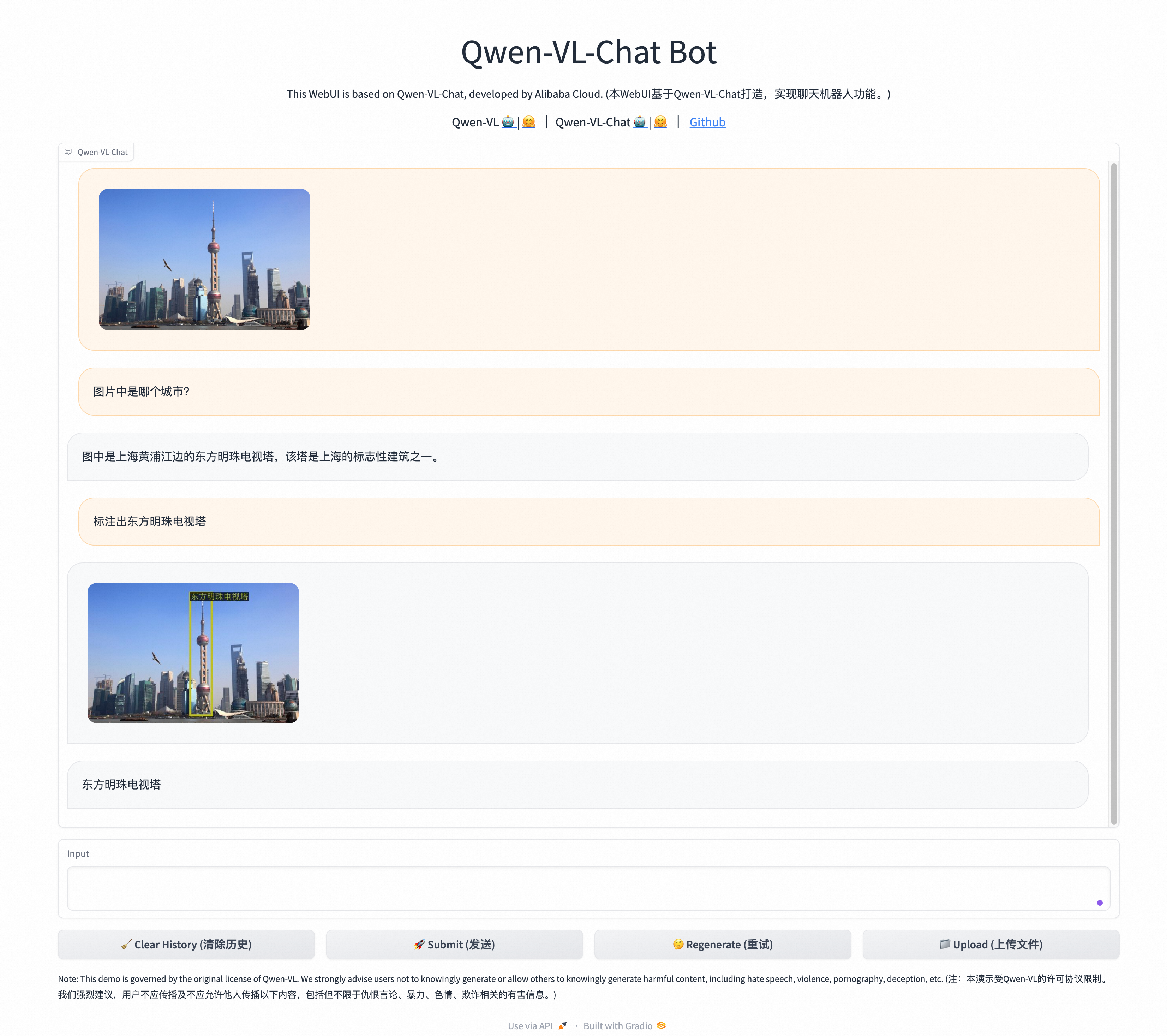
http://<ECS公网IP地址>:7860,进入Web页面。单击Upload(上传文件)上传图片,然后在Input对话框中,输入对话内容,单击Submit(发送),即可开始图片问答、图片检测框标注等。
说明以下示例远非Qwen-VL-Chat能力的极限,您可以通过更换不同的输入图像和提示词(Prompt),来进一步挖掘Qwen-VL-Chat的能力。
自动化部署
阿里云提供了自动部署脚本,可以一键部署运行Qwen-VL-Chat模型。
下载自动部署脚本。
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/en-US/20231213/owpj/deploy_qwen-vl-chat_amd-docker.sh进入容器环境。
sudo docker exec -it -w /root pytorch-amd /bin/bash重要后续命令需在容器环境中执行,如意外退出,请使用以上命令重新进入容器环境。如需查看当前环境是否为容器,可以执行
cat /proc/1/cgroup | grep docker查询(有回显信息则为容器环境)。下载tmux并创建一个tmux session。
yum install -y tmux tmux说明该脚本运行中会下载模型文件,耗时较长,建议在tmux session中启动部署,以免ECS断开连接导致部署中断。
为自动化部署脚本添加执行权限。
chmod +x deploy_qwen-vl-chat_amd-docker.sh运行自动化部署脚本。
./deploy_qwen-vl-chat_amd-docker.sh当显示结果如下所示时,说明自动部署脚本已完成。
 说明
说明该脚本运行时间较长,在tmux session中进行部署的过程中,如果断开了ECS连接,重新登录ECS实例后执行
tmux attach命令即可恢复tmux session,查看脚本运行进度。在浏览器地址栏输入
http://<ECS公网IP地址>:7860,进入Web页面。单击Upload(上传文件),然后在Input对话框中,输入对话内容,单击Submit(发送),即可开始图片问答、图片检测框标注等操作。
说明以下示例远非Qwen-VL-Chat能力的极限,您可以通过更换不同的输入图像和提示词(Prompt),来进一步挖掘Qwen-VL-Chat的能力。