
使用RocketMQ时,消息堆积产生时容易导致系统负载过高。为避免服务崩溃,提高系统的可靠性和稳定性,您可以基于RocketMQ消息堆积指标,使用KEDA(Kubernetes Event-driven Autoscaling)为应用的弹性伸缩方案,实现自动化和高效的容器水平伸缩(HPA)。
功能介绍
RocketMQ是一种高性能、高可靠、高扩展性的分布式消息中间件,已被广泛应用于企业级应用中。但使用RocketMQ时,容易产生消息堆积的问题,尤其是在高负载情况下。消息堆积容易导致系统负载过高,甚至导致服务崩溃。
在此场景下,您可以使用Kubernetes事件驱动自动伸缩工具KEDA,根据自定义的RocketMQ消息堆积指标,启动容器水平伸缩应用。此方案可以帮助您实现自动化和高效性的应用程序伸缩,从而提高系统的可靠性和稳定性。如果您采用的是开源的RocketMQ,考虑通过JMX的Prometheus Exporter提供消息对接的数据也可以实现类似的能力。更多信息,请参见RocketMQ开源社区。
本文使用阿里云Prometheus作为数据源,介绍如何实现RocketMQ的消息对接伸缩对象配置。
前提条件
已部署ack-keda组件,请参见事件驱动弹性。
已创建消息队列RocketMQ版5.x系列实例,请参见创建实例。
5.x的Serverless实例能够根据业务负载快速伸缩资源,支持根据实际的使用量分配资源和计算费用,能够有效地节约成本。更多信息,请参见RocketMQ 5.x Serverless实例概述。
已在ARMS中接入阿里云 RocketMQ(5.0) 服务。
步骤一:部署工作负载
本示例创建一个名为sample-app的Nginx示例应用。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在无状态页面,单击使用YAML创建资源,按照页面提示选择示例模板为自定义,使用如下示例代码创建一个名为sample-app的Nginx应用。
apiVersion: apps/v1 kind: Deployment metadata: name: sample-app namespace: default labels: app: sample-app spec: replicas: 1 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: sample-app # 修改为业务真实的RocketMQ的消费者镜像。 image: alibaba-cloud-linux-3-registry.cn-hangzhou.cr.aliyuncs.com/alinux3/nginx_optimized:20240221-1.20.1-2.3.0 resources: limits: cpu: "500m"
步骤二:通过ScaledObject配置伸缩策略
您可以通过ScaledObject YAML文件配置KEDA的伸缩策略,包括扩缩容的对象、最大最小副本数、扩缩容阈值(消息堆积量阈值)等。在配置ScaledObject前,您需要获取RocketMQ实例指标数据的Prometheus地址等信息。
1、在RocketMQ控制台获取RocketMQ实例信息
登录云消息队列 RocketMQ 版控制台,在左侧导航栏单击实例列表。
在顶部菜单栏选择地域,如华东1(杭州),然后在实例列表中,单击目标实例名称。
在左侧导航栏,单击Topic 管理,查看并记录名称的值和右上方实例 ID,例如:keda、mq-cn-uax33****。
2、在Prometheus控制台获取RocketMQ实例的Prometheus数据源
登录ARMS控制台。
在左侧导航栏选择,进入可观测监控 Prometheus 版的实例列表页面。
单击目标实例云服务-{{RegionId}},在左侧导航栏,单击设置,记录HTTP API地址(Grafana 读取地址)。

3、创建ScaledObject YAML文件
使用如下内容,创建ScaledObject.yaml,配置伸缩策略。
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: prometheus-scaledobject namespace: default spec: scaleTargetRef: name: sample-app maxReplicaCount: 10 minReplicaCount: 2 triggers: - type: prometheus metadata: serverAddress: http://cn-beijing.arms.aliyuncs.com:9090/api/v1/prometheus/8cba801fff65546a3012e9a684****/****538168824185/cloud-product-rocketmq/cn-beijing metricName: rocketmq_consumer_inflight_messages query: sum({__name__=~"rocketmq_consumer_ready_messages|rocketmq_consumer_inflight_messages",instance_id="rmq-cn-uax3xxxxxx",topic=~"keda"}) by (consumer_group) threshold: '30'参数说明如下。
参数
说明
scaleTargetRef.name配置扩缩容的对象,这里配置步骤一:部署工作负载创建好的应用sample-app。
maxReplicaCount扩容的最大副本数。
minReplicaCount缩容的最小副本数。
serverAddress配置存储RocketMQ指标数据的Prometheus地址,即上文记录的HTTP API地址(Grafana 读取地址)。
metricNamePromQL请求数据。
query对metricName中PromQL请求的数据做聚合操作,此处聚合方式为消息堆积量的PromQL。
threshold扩缩容的阈值。本示例将消息堆积量30作为阈值,超过30时会触发扩容。
执行如下命令,部署文件并查看创建的资源。
# 下发伸缩配置。 kubectl apply -f ScaledObject.yaml scaledobject.keda.sh/prometheus-scaledobject created # 获取伸缩配置状态。 kubectl get ScaledObject NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE prometheus-scaledobject apps/v1.Deployment sample-app 2 10 prometheus True False False 105s # 检查HPA的生成情况。 kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-prometheus-scaledobject Deployment/sample-app 0/30 (avg) 2 10 2 28m(可选)使用Prometheus Token以提高数据读取的安全性,并配置Prometheus Token的验证。
按照页面提示,生成Prometheus Token。
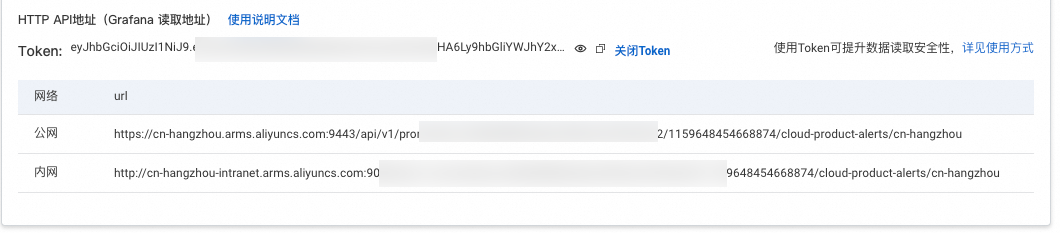
创建一个Secret,其中需对
customAuthHeader: "Authorization"、customAuthValue这两个字段的Value值进行Base64编码。apiVersion: v1 kind: Secret metadata: name: keda-prom-secret namespace: default data: customAuthHeader: "QXV0Xxxxxxxlvbg==" customAuthValue: "kR2tpT2lJeFpXSmxaVFV6WlMTxxxxxxxxRMVFE0TUdRdE9USXpaQzFqWkRZd09EZ3dOVFV5WWpZaWZRLjlDaFBYU0Q2dEhWc1dQaFlyMGh3ZU5FQjZQZWVETXFjTlYydVNqOU82TTQ="参见下方示例代码,创建KEDA请求数据的凭证,并部署到集群中。
apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-prom-creds namespace: default spec: secretTargetRef: - parameter: customAuthHeader name: keda-prom-secret key: customAuthHeader - parameter: customAuthValue name: keda-prom-secret key: customAuthValue在ScaledObject YAML文件中,配置
authenticationRef字段,填写创建的凭证名称。apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: prometheus-scaledobject namespace: default spec: scaleTargetRef: name: sample-app maxReplicaCount: 10 minReplicaCount: 2 triggers: - type: prometheus metadata: serverAddress: http://cn-beijing.arms.aliyuncs.com:9090/api/v1/prometheus/8cba801fff65546a3012e9a684****/****538168824185/cloud-product-rocketmq/cn-beijing metricName: rocketmq_consumer_inflight_messages query: sum({__name__=~"rocketmq_consumer_ready_messages|rocketmq_consumer_inflight_messages",instance_id="rmq-cn-uax3xxxxxx",topic=~"keda"}) by (consumer_group) threshold: '30' authModes: "custom" authenticationRef: # 配置字段。 name: keda-prom-creds # 填写凭证名称。说明本示例使用Custom authentication的认证类型。您可以参见KEDA社区文档选择其他认证方式。
步骤三:生产和消费数据
本示例使用rocketmq-keda-sample项目生产和消费数据,请在项目代码中配置步骤二中记录的RocketMQ实例的地址、用户名、密码。
步骤四:使用生产和消费数据实现扩缩容
登录云消息队列 RocketMQ 版控制台,在左侧导航栏单击实例列表。
在顶部菜单栏选择地域,如华东1(杭州),然后在实例列表中,单击目标实例名称,查看并记录接入点和网络信息。
在左侧导航栏,单击访问控制,然后单击智能身份识别页签,查看并记录实例用户名和实例密码。
运行Producer程序生产数据,然后执行如下命令,查看HPA伸缩情况。
kubectl get hpa预期输出:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-prometheus-scaledobject Deployment/sample-app 32700m/30 (avg) 2 10 10 47m预期输出表明,sample-app应用已经扩容到KEDA组件设置的最大副本数。
关闭Producer程序,运行Consumer程序,然后执行如下命令,查看HPA伸缩情况。
kubectl get hpa -w预期输出:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-prometheus-scaledobject Deployment/sample-app 222500m/30 (avg) 2 10 10 50m keda-hpa-prometheus-scaledobject Deployment/sample-app 232400m/30 (avg) 2 10 10 51m keda-hpa-prometheus-scaledobject Deployment/sample-app 0/30 (avg) 2 10 10 52m keda-hpa-prometheus-scaledobject Deployment/sample-app 0/30 (avg) 2 10 2 57m预期输出表明,在数据消费结束一段时间后,sample-app应用缩容至KEDA组件设置的最小副本数。
相关文档
您也可以实现基于RabbitMQ指标的KEDA,监控队列长度和消息速率指标,请参见基于RabbitMQ指标的容器水平伸缩。