
为降低模型微调训练成本,您可以使用伸缩组自动调度抢占式实例,同时配置抢占式实例中断回收时自动创建新实例、基于最新Checkpoint恢复训练,保障任务连续性。
方案概览
本方案基于伸缩组实现大模型低成本微调训练,采用抢占式实例优先策略并结合对象存储实现Checkpoint持久化,在训练过程中:
优先使用抢占式实例:伸缩组优先调度抢占式实例执行训练任务,并使用对象存储保存Checkpoint文件。
抢占式实例中断回收时:伸缩组会优先尝试从其他可用区库存中调度抢占式实例,若抢占式库存不足,则自动调度按量实例,从最新的Checkpoint恢复训练任务。
抢占式库存恢复后:自动将按量实例替换为抢占式实例,并从最新的Checkpoint恢复训练。
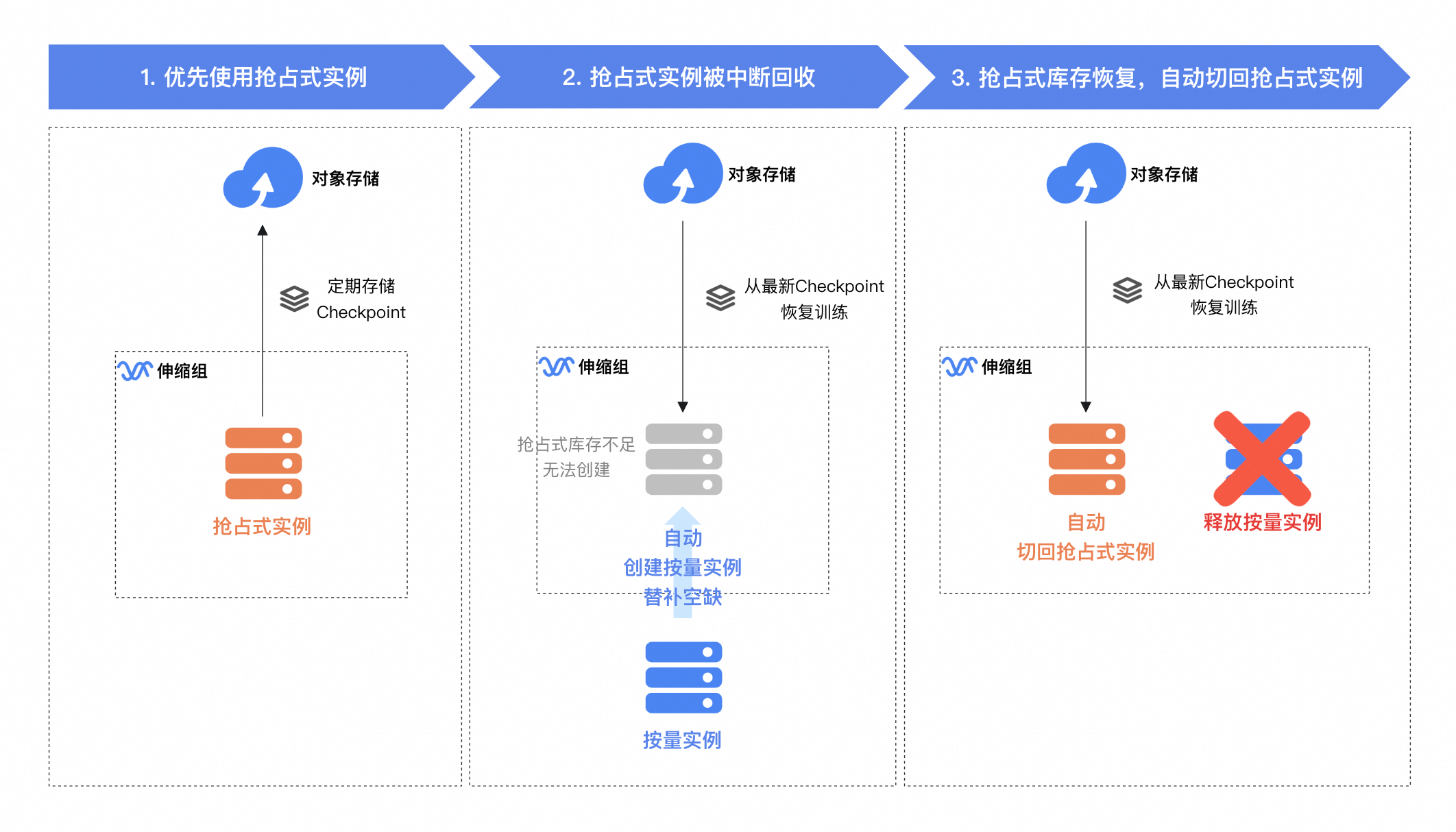
若您对成本敏感且能接受训练结束时间延迟,可配置伸缩组全程使用抢占式实例。在无法使用抢占式实例时暂停训练,库存恢复后继续使用抢占式实例,以极致节省成本。点击了解更多伸缩组与抢占式实例的组合用法。
成本对比
以下成本对比仅供参考,成本节省效果视实际运行情况而定。
假设训练共需12小时,抢占式实例单价为3.5/h,按量实例单价10/h,成本对比如下。
模式 | 全程使用抢占式实例 | 抢占式、按量交替 | 全程使用按量 |
说明 | 当抢占式实例被中断回收时,暂停训练,在库存恢复后自动启动新的抢占式实例继续训练。 | 假设每1小时抢占式实例中断回收一次,然后按需实例使用0.5小时后切回抢占式实例。 | 全部使用按量实例进行训练。 |
成本 | 12h * 3.5/h = 42 | 8h * 3.5/h + 4h * 10/h = 68 | 12h * 10/h = 120 |
相比全程按量成本节省 | 65% | 43.33% | 0% |
搭建流程
构建包含训练基础环境的实例镜像。
该镜像将作为伸缩组实例的启动镜像,内置开机自动训练脚本,确保新实例能够快速恢复训练任务,实现自动化运行。
创建并配置伸缩组。
伸缩组负责在实例中断或回收后,自动创建新的抢占式或按量实例,确保训练任务持续进行。
启动训练任务。
启动伸缩组后自动触发扩容,创建实例以开始训练任务,并按照预先设定的自动化机制工作。
模拟中断回收(验证)。
手动释放实例以模拟中断或资源回收场景,验证是否能启动新实例并自动恢复训练任务,确保任务的稳定性和可靠性。
1. 构建包含训练基础环境的实例镜像
本文将以单机单卡场景下,使用Swift训练框架对DeepSeek-R1-Distill-Qwen-7B模型进行自我认知微调为例,进行步骤说明。
首先需创建包含训练环境及依赖的实例并制作镜像,作为伸缩组实例的启动镜像,以提升任务实例启动效率;镜像内置自动训练脚本和开机自启服务,实现全流程自动化运行。用于制作该镜像的ECS实例架构如图所示。

关键点说明如下:
训练环境基础依赖:包含GPU驱动、CUDA以及相关Python依赖(根据训练框架而定)。
自动训练脚本:此脚本需能够自动判断是否从最新的Checkpoint恢复训练,并判断训练是否已完成。
开机自动挂载Bucket:训练脚本启动时会从对象存储Bucket中读取模型权重、数据集以及训练生成的Checkpoint文件。
开机自启动服务:该服务确保实例开机后,自动启动训练脚本,读取Bucket中的相关文件,开始或继续训练。
在了解以上内容后,您可以参考以下步骤完成该镜像的构建。
1.1 创建实例并构建基础环境
该实例会作为模板实例,产出镜像,后续伸缩组会自动以该镜像创建新实例。
前往ECS控制台创建GPU实例。
首先需要创建一个按量的GPU实例用于基础环境的搭建。本文以在杭州地域的可用区J创建规格为
ecs.gn7i-c8g1.2xlarge的实例为例。配置步骤如图所示:①:付费类型。按量付费。
②:地域。华东1(杭州)。
③④:网络及可用区。选择专有网络和交换机,若没有可按照界面提示创建。

⑤⑥:选择实例规格。
ecs.gn7i-c8g1.2xlarge。
⑦⑧⑨:镜像。Ubuntu 22.04 64位。
⑩:安装GPU驱动。版本:CUDA版本 12.4.1、Driver版本 550.127.08、CUDNN版本 9.2.0.82。

⑪:。60GiB。
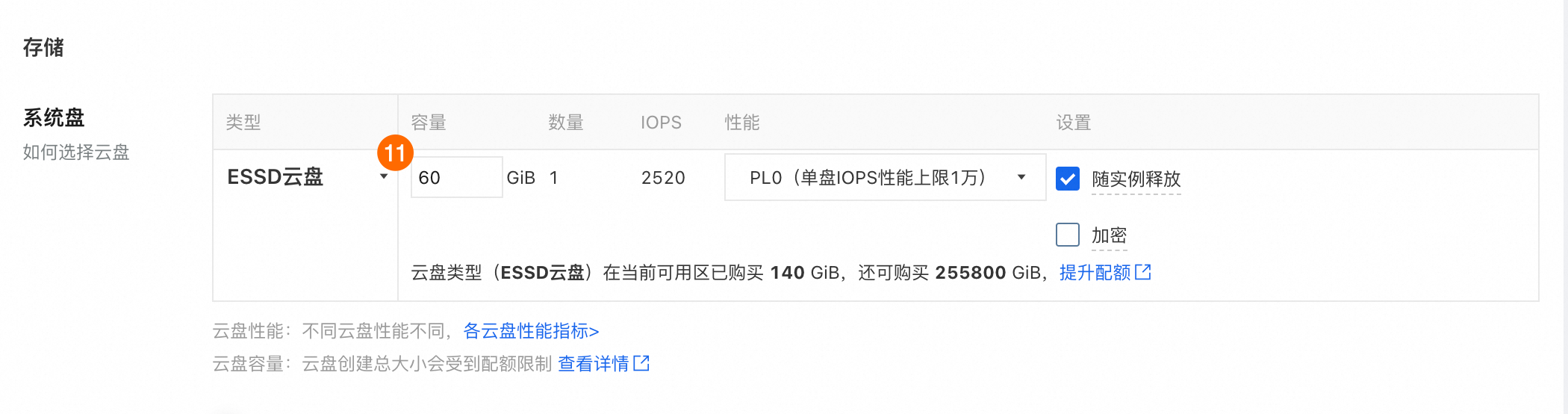
⑫⑬⑭:分配公网IPv4地址使实例可以访问公网,下载模型文件。带宽计费模式选择按使用流量。带宽峰值选择100Mbps。
⑮⑯⑰:新建普通安全组,端口至少放开SSH(TCP:22)和ICMP(IPv4),便于后续远程连接实例。

⑱⑲⑳:登录凭证。用于后续登录实例。可根据需求选择密钥对或密码。根据界面提示完成设置。
㉑:实例名称。设置便于记忆的实例名称,便于查找。本文以
ess-lora-deepseek7b-template为例。
完成配置后单击确认下单,等待实例创建完成。
在实例创建完成后,连接实例并等待GPU驱动安装完成。
访问ECS控制台-实例。
找到上一步创建的实例,单击操作列下的远程连接,通过Workbench连接实例,并根据界面提示完成登录操作。
若未找到实例,可能是当前地域与实例地域不符,可以在左上角切换地域。
若实例处于停止状态,请刷新页面并等待实例启动。

连接实例后,等待GPU驱动安装完成。安装完成后,会提示您重新连接实例。
若界面卡住,您可以尝试刷新页面,重新连接实例。
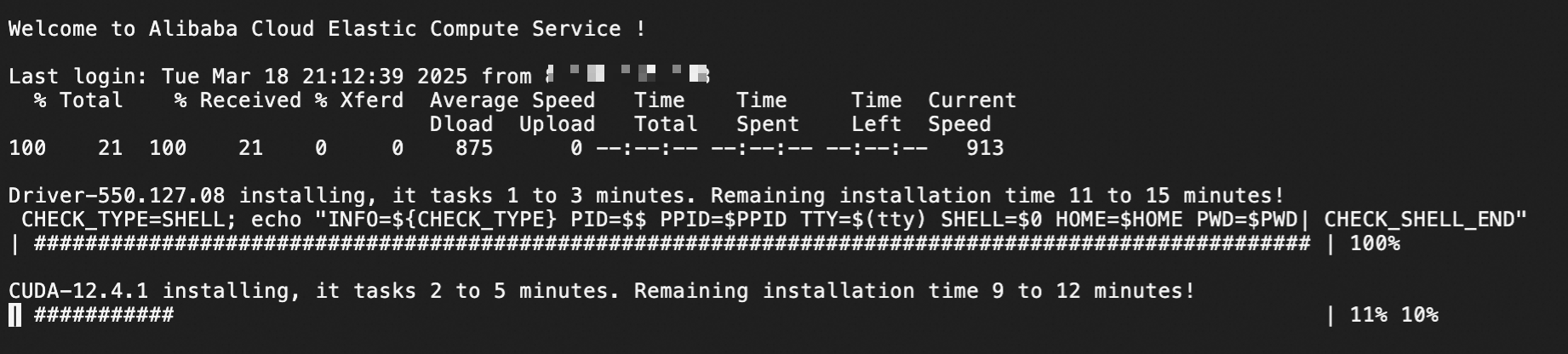
在连接实例后没有出现该界面,可能是由于您的实例已经完成驱动安装操作。您可以通过使用以下命令确认是否已安装驱动。
nvidia-smi若出现如下界面,则代表已经完成安装。

如果未出现该界面,代表启动驱动未安装或存在问题,建议您重新创建新实例,并勾选安装 GPU 驱动。
如需手动安装驱动,请参见在GPU计算型实例中手动安装Tesla驱动(Linux)。
安装相关Python依赖。
使用以下命令,安装训练相关依赖。
本示例所选择的镜像为Ubuntu 22.04 64位,已经包含Python 3.10环境,因此不需要安装Python。
# ubuntu 22.04镜像自带python 3.10,无需额外安装 python3 -m pip install --upgrade pip # 切换为阿里云内网镜像源 pip config set global.index-url http://mirrors.cloud.aliyuncs.com/pypi/simple/ pip install modelscope==1.22.3 pip install openai==1.61.0 pip install tqdm==4.67.1 pip install "vllm>=0.5.1" -U pip install "lmdeploy>=0.5,<0.6.5" -U --no-deps pip install autoawq -U --no-deps pip install auto_gptq optimum bitsandbytes -U pip install ms-swift[all] pip install timm -U pip install deepspeed==0.14.* -U pip install qwen_vl_utils decord librosa pyav icecream -U
在等待依赖安装时,可以点击右上角开启多屏终端,同时进行步骤1.2的操作。
1.2 创建对象存储的存储空间并挂载到实例
本步骤需要先在对象存储创建存储空间(Bucket),并将该存储空间作为额外的数据盘挂载到ECS实例,负责存储后续步骤下载的模型权重文件、训练数据集以及训练过程中产生的Checkpoint。
前往对象存储控制台创建Bucket。
关键配置项说明如下,未提及配置项保持默认。
②:Bucket 名称。该Bucket名称在后续挂载存储空间时会用到。
③:地域。选择有地域属性,地域需与ECS实例所在地域保持一致,本示例为华东1(杭州)。
ECS实例支持通过内网访问同地域的对象存储Bucket,内网访问不会产生流量费用,具体说明,请参见ECS实例通过OSS内网地址访问OSS资源。

创建并绑定实例RAM角色。
实例RAM角色用于授权ECS实例访问您创建的对象存储Bucket。创建并绑定实例RAM角色的操作流程如下:
在控制台创建实例RAM角色。关键配置项说明如下。

②:信任主体类型。选择云服务。
③:信任主体名称。选择云服务器 ECS,代表该角色需要授权给ECS实例。
④:单击确定后,根据界面提示设置实例RAM角色的名称。

在控制台创建以下自定义权限策略。


③:该策略代表某个Bucket的全部权限。权限策略脚本内容如下。
重要设置以下自定义策略时,请将
<bucket_name>替换为您所创建的存储空间的Bucket 名称。{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": "oss:*", "Resource": [ "acs:oss:*:*:<bucket_name>", "acs:oss:*:*:<bucket_name>/*" ] } ] }完成配置后单击确定,根据界面提示设置权限策略名称。
在控制台为实例RAM角色授权。
⑥:授权主体。选择之前创建的实例RAM角色。
⑦:权限策略。选择之前创建的自定义权限策略。

完成配置后单击确认新增授权。
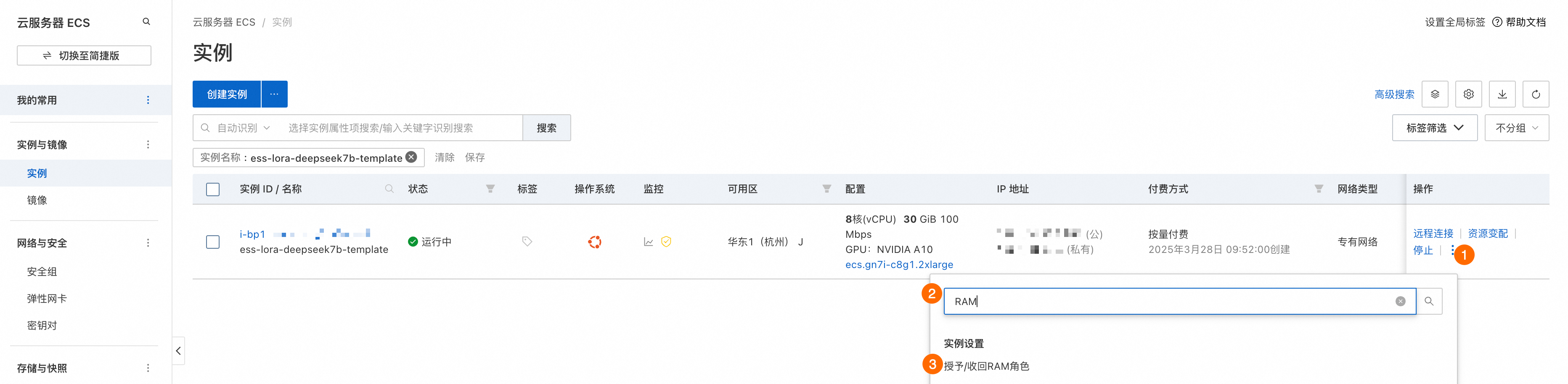
前往ECS控制台,将实例RAM角色授予给实例。
若未找到实例,可能是当前地域与实例地域不符,可以在左上角切换地域。
将存储空间挂载到ECS实例。
连接步骤1.1创建的实例,执行以下命令,安装ossfs工具。
wget https://gosspublic.alicdn.com/ossfs/ossfs_1.91.5_ubuntu22.04_amd64.deb apt-get update DEBIAN_FRONTEND=noninteractive apt-get install gdebi-core DEBIAN_FRONTEND=noninteractive gdebi -n ossfs_1.91.5_ubuntu22.04_amd64.deb执行以下命令完成挂载操作。需注意替换命令中的以下内容:
<bucket_name>:替换为您所创建的存储空间的Bucket 名称。<ecs_ram_role>:替换为您所创建的实例RAM角色名称。前往ECS控制台,找到绑定了实例RAM角色的实例,根据如图所示步骤进入授予/收回RAM角色页面
。在该页面可以查看实例已经绑定的实例RAM角色。
若未找到实例,可能是当前地域与实例地域不符,可以在左上角切换地域。
<internal_endpoint>:替换为oss-cn-hangzhou-internal.aliyuncs.com。重要本示例所创建的Bucket地域为华东1(杭州),故使用
oss-cn-hangzhou-internal.aliyuncs.com作为VPC内网Endpoint。若您创建对象存储Bucket地域不在杭州,请获取VPC内网Endpoint地址后,替换
<internal_endpoint>的值。
# 需替换对应的Bucket名称、内网接入点、实例RAM角色 BUCKET_NAME="<bucket_name>" ECS_RAM_ROLE="<ecs_ram_role>" INTERNAL_ENDPOINT="<internal_endpoint>" # Bucket挂载目录 BUCKET_MOUNT_PATH="/mnt/oss-data" # 1. 挂载前备份fstab文件 cp /etc/fstab /etc/fstab.bak # 2. 创建被挂载的目录 mkdir $BUCKET_MOUNT_PATH # 3. 挂载Bucket到实例 ossfs $BUCKET_NAME $BUCKET_MOUNT_PATH -ourl=$INTERNAL_ENDPOINT -oram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE # 4. 设置开机自动挂载 echo "ossfs#$BUCKET_NAME $BUCKET_MOUNT_PATH fuse _netdev,url=http://$INTERNAL_ENDPOINT,ram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE,allow_other 0 0" | sudo tee -a /etc/fstab
(验证)测试存储空间是否可用。
在对象存储的Bucket中上传任意文件。

在实例中输入以下命令,测试是否可以在目录看到对象存储中的文件。
ls /mnt/oss-data/如果可以看到,则代表挂载成功。

1.3 准备模型与数据集
本文使用的模型权重文件与数据集均从魔搭社区下载,连接实例后,按照以下步骤操作。将模型与数据集下载到对象存储Bucket所挂载的目录,并等待所有文件下载完成。
下载数据集
# Bucket挂载目录 BUCKET_MOUNT_PATH="/mnt/oss-data" # 从魔搭社区下载微调数据集 # 使用步骤1.1中安装的modelscope工具 modelscope download --dataset swift/self-cognition --local_dir $BUCKET_MOUNT_PATH/self-cognition modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-zh --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-zh modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-en --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-en若进度卡住可以多次点击回车。
下载模型权重文件
重要由于模型权重文件过大,若下载失败,或提示
please try again,请重试该命令恢复下载。# Bucket挂载目录 BUCKET_MOUNT_PATH="/mnt/oss-data" # 从魔搭社区下载DeepSeek-R1-Distill-Qwen-7B模型 modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B若进度卡住可以多次点击回车。
测试模型权重文件是否有效
在下载完成后,您可以在命令行执行以下命令,使用模型进行推理测试,测试模型权重文件是否完整。
# Bucket挂载目录 BUCKET_MOUNT_PATH="/mnt/oss-data" CUDA_VISIBLE_DEVICES=0 swift infer \ --model $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B \ --stream true \ --infer_backend pt \ --max_new_tokens 2048如图所示,模型加载完成后,您可以与大模型进行对话。如果模型权重文件加载失败,请重新下载模型权重文件。

测试完成后可输入
exit退出对话。
1.4 编写自动训练脚本
编写自动训练脚本。
输入以下命令创建自动训练脚本,并授予可执行权限。本脚本包含自动从最新Checkpoint恢复训练的以及判断训练完成的功能。
# 创建自动训练脚本 cat <<EOF > /root/train.sh #!/bin/bash # Bucket挂载目录 BUCKET_MONTH_PATH="/mnt/oss-data" # 模型权重文件及数据集存储目录 MODEL_PATH="\$BUCKET_MONTH_PATH/DeepSeek-R1-Distill-Qwen-7B" DATASET_PATH="\$BUCKET_MONTH_PATH/alpaca-gpt4-data-zh#500 \$BUCKET_MONTH_PATH/alpaca-gpt4-data-en#500 \$BUCKET_MONTH_PATH/self-cognition#500" # 设置输出目录 OUTPUT_DIR="\$BUCKET_MONTH_PATH/output" mkdir -p "\$OUTPUT_DIR" # 判断已经完成训练,无需操作的逻辑 if [ -f "\$OUTPUT_DIR/logging.jsonl" ]; then last_line=\$(tail -n 1 "\$OUTPUT_DIR/logging.jsonl") if echo "\$last_line" | grep -q "last_model_checkpoint" && echo "\$last_line" | grep -q "best_model_checkpoint"; then echo "Training already completed. Exiting." exit 0 fi fi # 初始化恢复参数 RESUME_ARG="" # 查找最新检查点 LATEST_CHECKPOINT=\$(ls -dt \$OUTPUT_DIR/checkpoint-* 2>/dev/null | head -1) if [ -n "\$LATEST_CHECKPOINT" ]; then RESUME_ARG="--resume_from_checkpoint \$LATEST_CHECKPOINT" echo "Resume training from: \$LATEST_CHECKPOINT" else echo "No checkpoint found. Starting new training." fi # 启动训练命令 CUDA_VISIBLE_DEVICES=0 swift sft \\ --model \$MODEL_PATH \\ --train_type lora \\ --dataset \$DATASET_PATH \\ --torch_dtype bfloat16 \\ --num_train_epochs 1 \\ --per_device_train_batch_size 1 \\ --per_device_eval_batch_size 1 \\ --learning_rate 1e-4 \\ --lora_rank 8 \\ --lora_alpha 32 \\ --target_modules all-linear \\ --gradient_accumulation_steps 16 \\ --eval_steps 50 \\ --save_steps 10 \\ --save_total_limit 5 \\ --logging_steps 5 \\ --max_length 2048 \\ --output_dir "\$OUTPUT_DIR" \\ --add_version False \\ --overwrite_output_dir True \\ --system 'You are a helpful assistant.' \\ --warmup_ratio 0.05 \\ --dataloader_num_workers 4 \\ --model_author swift \\ --model_name swift-robot \\ \$RESUME_ARG EOF # 授予可执行权限 chmod +x /root/train.sh使用以下命令测试该脚本是否可以正常运行。
./train.sh如图所示,若执行命令后,模型可以正常加载,并正常开始训练,证明模型文件正确且依赖完整,按
CTRL + C退出训练即可。
若不能正常执行,请重新安装步骤1.1中的Python依赖,并重新下载步骤1.3中的权重以及数据集文件。
创建Linux服务,并配置开机自启动。
输入以下命令创建服务,并配置训练脚本开机自启动。
# 创建日志存储目录 mkdir -p /root/train-service-log # 编写Service配置文件 cat <<EOF > /etc/systemd/system/train.service [Unit] Description=Train AI Model Script After=network.target local-fs.target remote-fs.target Requires=local-fs.target remote-fs.target [Service] ExecStart=/root/train.sh WorkingDirectory=/root/ User=root Environment="PATH=/usr/bin:/usr/local/bin" Environment="CUDA_VISIBLE_DEVICES=0" StandardOutput=append:/root/train-service-log/train.log StandardError=append:/root/train-service-log/train_error.log [Install] WantedBy=multi-user.target EOF # 重新加载systemd配置 systemctl daemon-reload # 配置train.service服务开机自启动 systemctl enable train.service命令执行完成返回如下内容:

1.5 构建镜像
在完成前面所有步骤后,需要从完成配置的实例构建自定义镜像,后续在扩容时,可以直接使用该镜像作为实例的启动镜像,无需重新安装相关依赖等操作。


镜像创建完成后,可释放步骤1.1中创建的实例。
2. 创建伸缩组
配置伸缩组以实现对实例的自动化管理。伸缩组主要负责确保实例在中断回收后,可以自动创建新的抢占式实例或按量实例,继续训练任务。在可以创建抢占式实例时,自动使用抢占式实例替换按量实例以节省成本。
2.1 创建伸缩组
首先需要创建伸缩组,操作步骤如下。

根据以下步骤,完成伸缩组的配置。如需了解配置项详细说明,请参见配置项说明。
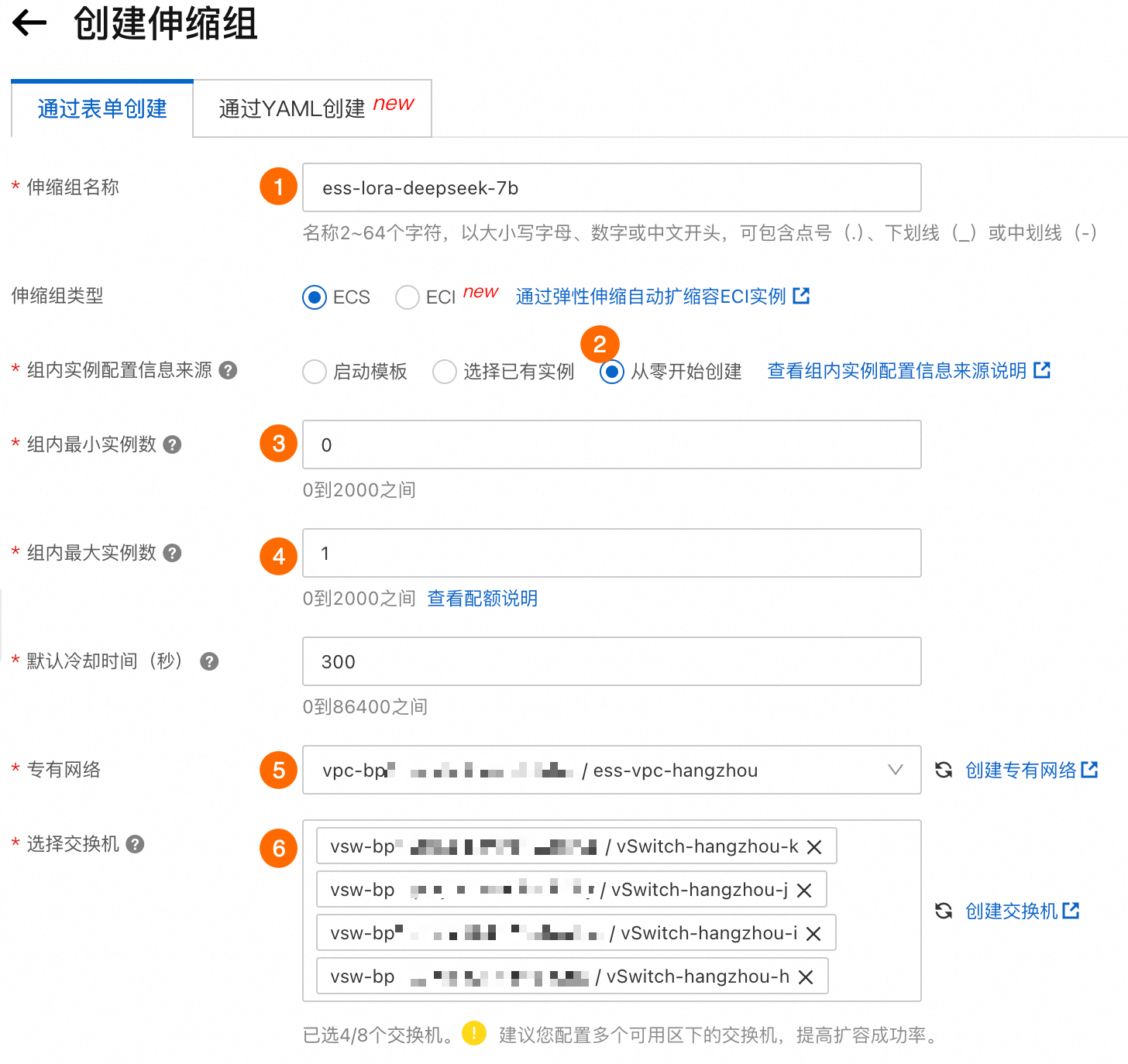 重要
重要在⑤⑥选择专有网络和交换机时,建议选择多个可用区的交换机,使伸缩组可以跨可用区调度库存,提高抢占式实例的使用概率。

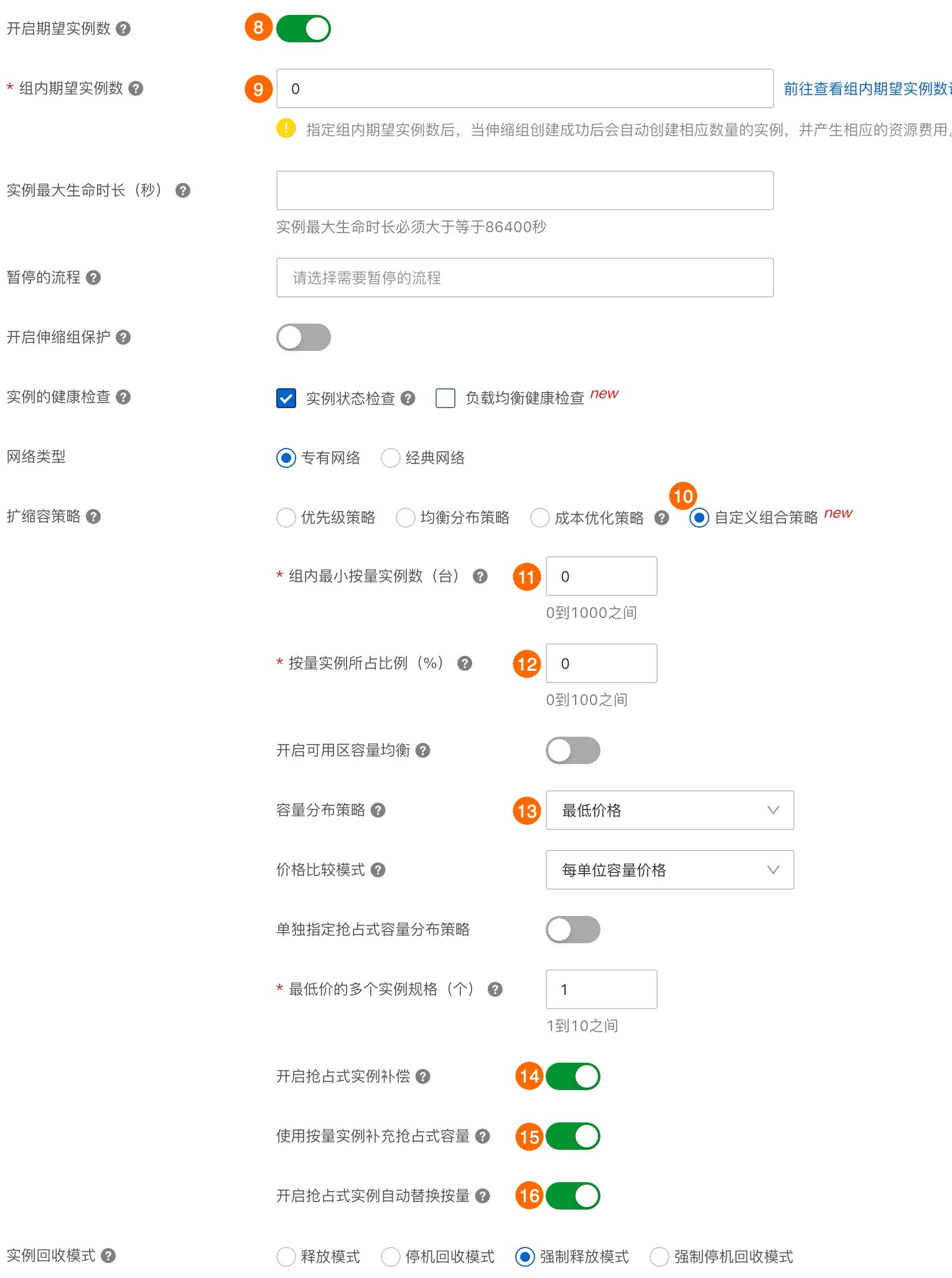 重要
重要如果您希望仅使用抢占式实例进行训练,以极致节省成本,需关闭⑮使用按量实例补充抢占式容量和⑯抢占式实例自动替换按量两个配置项。
完成配置后单击创建。可根据界面提示继续创建伸缩配置。

2.2 创建伸缩配置
伸缩配置主要用于定义伸缩组中实例的规格、镜像等信息。完成该配置后,伸缩组会自动按照该配置定义的实例信息,创建新实例。在创建伸缩配置页面,完成以下配置:

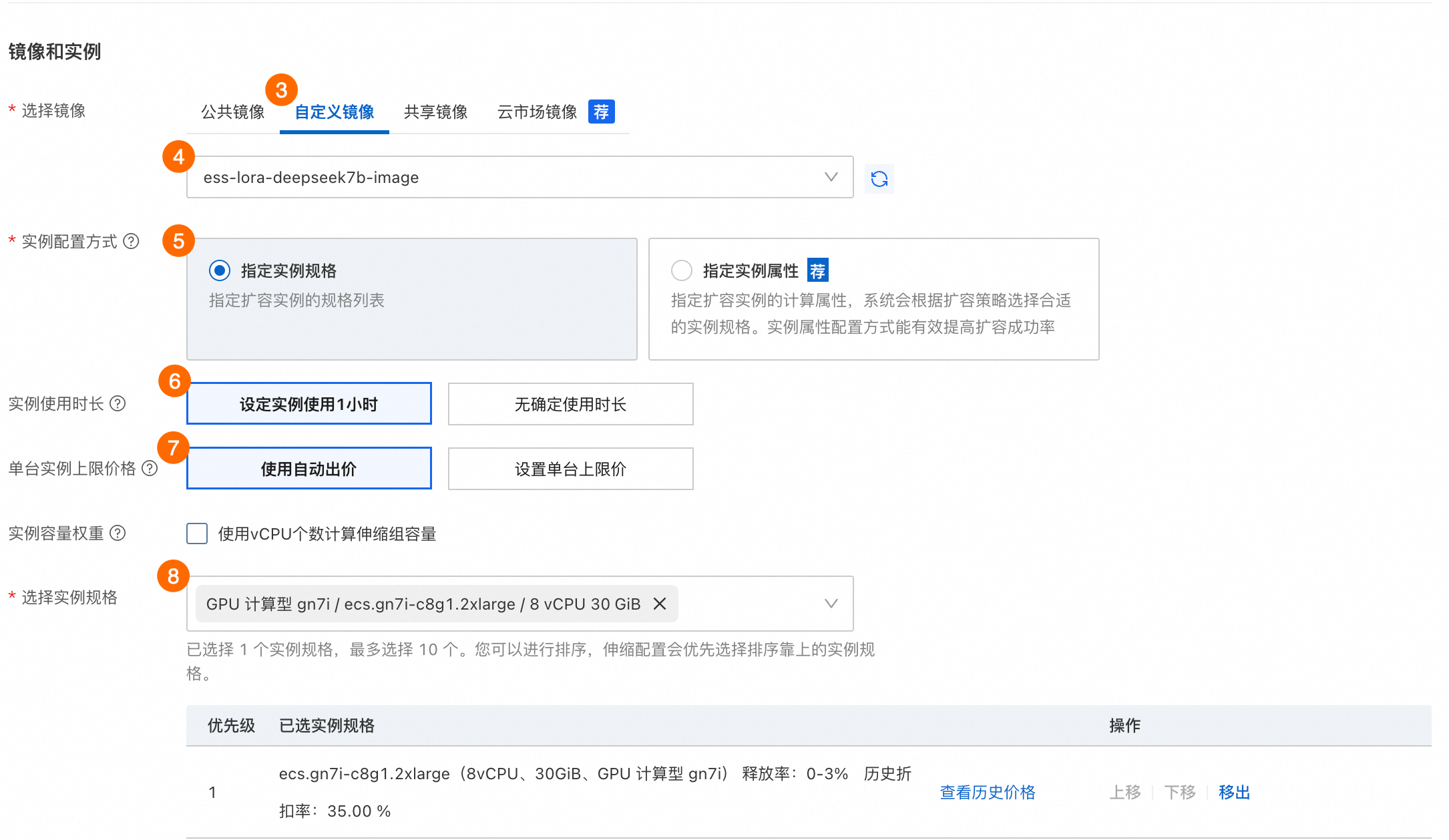
①:伸缩配置名称。 ②:付费模式。抢占式实例。
|
③④:选择镜像。选择自定义镜像,然后选择步骤1.5中构建的自定义镜像。 ⑤:实例配置方式。选择指定实例规格。 ⑥:实例使用时长。选择设定实例使用1小时,使用该选项,在实例运行一小时后,开始检测是否中断回收实例。 如果选择无确定使用时长,虽然能以更低的成本使用按量实例,但由于其中断回收的概率更高,可能实例被回收前不能产生有效的Checkpoint,导致训练进度缓慢。该配置项两个选项之间的区别,请参见在伸缩组使用抢占式实例降低成本。 ⑦:单台实例上限价格。选择使用自动出价,自动跟随市场价进行出价。 ⑧:选择实例规格。选择步骤1.1中创建实例时设置的实例规格,即
|
⑨:安全组。选择步骤1.1中创建实例时设置的安全组。 本示例为离线训练方案,无需分配公网IP。
|
⑩:登录凭证。选择使用镜像预设密码。
|
⑪⑫⑬:。选择步骤1.2中创建的实例RAM角色。后续在伸缩组自动创建实例时,将自动为新实例设置该实例RAM角色。
|



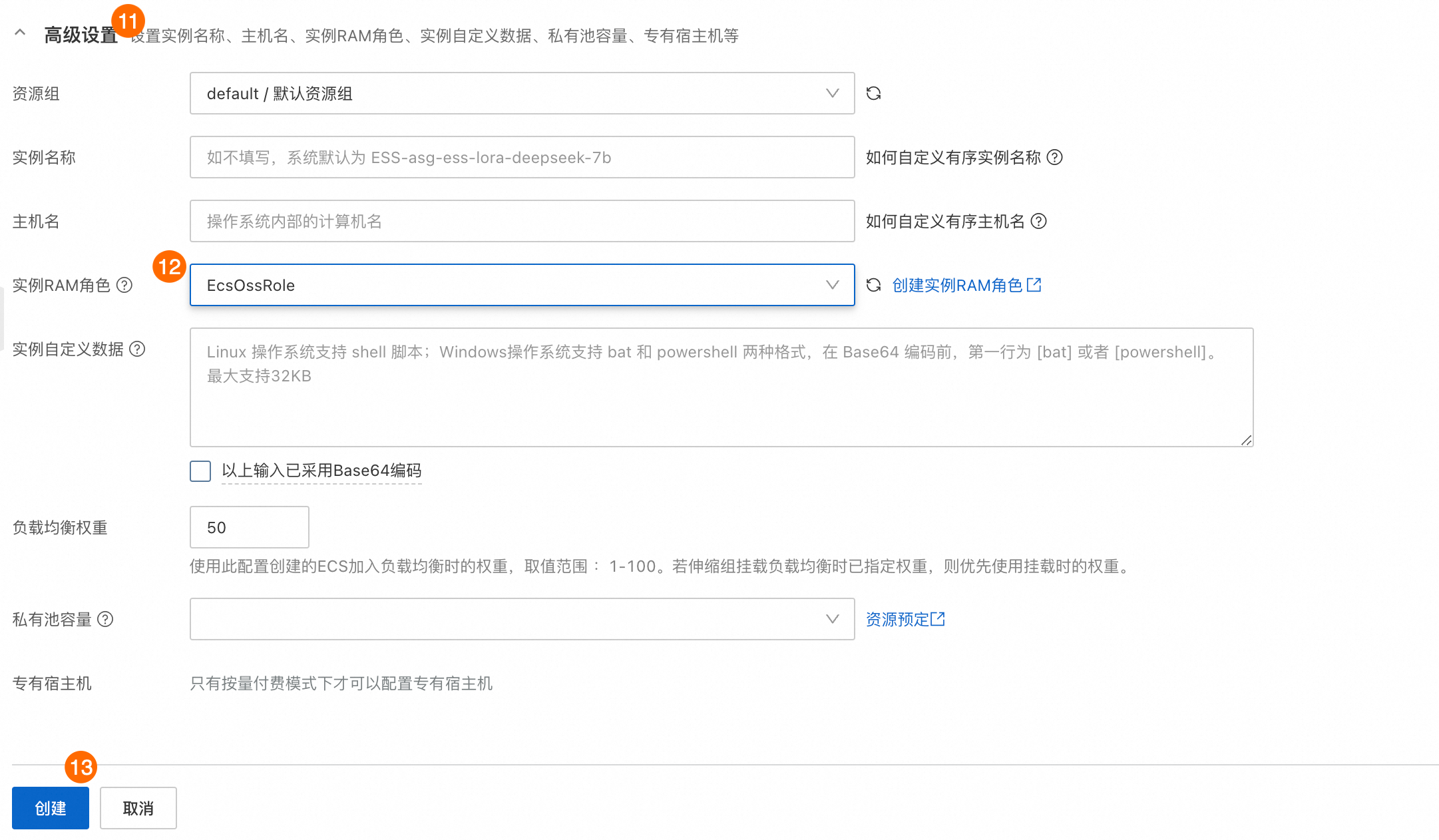
单击创建后,可能会提示伸缩配置强度不足,点击继续即可。
创建伸缩配置后,根据界面提示启用伸缩配置并启动伸缩组。
|
|
|



3. 开始训练任务
在伸缩组配置完成后,需调整伸缩组的期望实例数为1,操作步骤如图所示。
|
|


完成后,伸缩组会自动创建一台新的实例并开始训练任务。
伸缩组会定期检测伸缩组中的实例数量是否满足期望实例数。当前伸缩组中实例数为0,将自动触发扩容,创建新实例。
调整期望实例数后,创建实例的操作可能会有延迟。您可以在伸缩活动页签下,查看伸缩组中正在进行的伸缩活动。
实例创建并启动完成后,您可以在对象存储中找到
output文件夹,该文件夹用于存储训练过程中产生的Checkpoint文件。
4. 模拟中断回收(验证)
在实例开始执行训练任务后,可以观察对象存储的Bucket中output目录下是否已经产生类似checkpoint-10的文件夹,当产生Checkpoint后,您可以手动释放正在训练的实例,模拟实例的中断回收,手动释放实例的操作如下:
手动释放实例。
首先进入伸缩组的实例列表,单击云服务器ID进入对应的实例管理页。
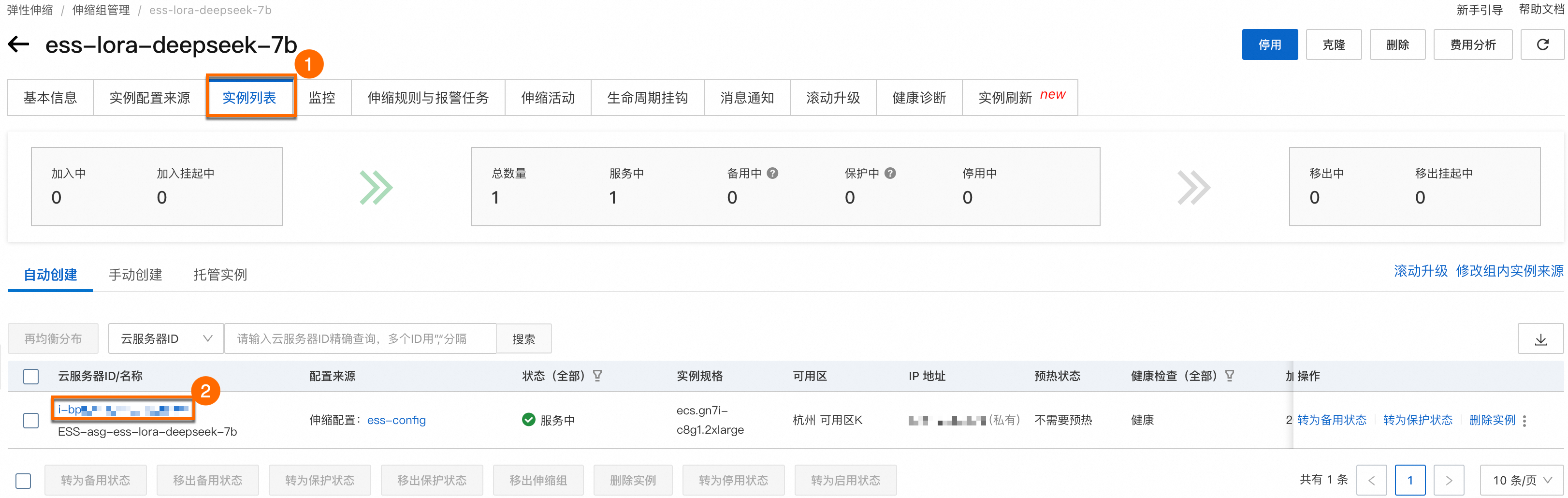
在实例管理页,单击右上角的,根据界面提示完成实例的释放操作。

检查是否从最新的Checkpoint恢复训练。
等待伸缩组创建新实例,实例创建完成后,连接该实例,查看任务日志。
进入伸缩组的实例列表,单击云服务器ID进入对应的实例管理页。
单击右上角的远程连接,根据界面提示连接实例。
执行以下命令查看模型训练日志,该日志输出路径是您在步骤1.4中设置的开机自启动服务的日志输出路径。
cat /root/train-service-log/train.log可以看到,训练任务从最新的Checkpoint继续训练。

后续步骤
使用微调完成后的模型进行推理
该微调训练任务完成后,会在对象存储Bucket的output目录下生成一个checkpoint-93文件夹,此时您可以远程连接实例,通过以下命令,与微调后的模型进行对话。
# Bucket挂载目录
BUCKET_MOUNT_PATH="/mnt/oss-data"
# 设置输出目录
OUTPUT_DIR="$BUCKET_MOUNT_PATH/output"
# 查找最新检查点
LATEST_CHECKPOINT=$(ls -dt $OUTPUT_DIR/checkpoint-* 2>/dev/null | head -1)
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters $LATEST_CHECKPOINT \
--stream true \
--temperature 0 \
--max_new_tokens 2048
释放本文涉及资源
在生产环境应用本方案的建议
在将本方案应用于生产环境前,您需要根据实际业务情况,并参考以下建议,改进方案。
接入云监控,感知中断回收并响应
在生产环境中应用该方案,建议在训练代码中接入云监控,感知并响应抢占式实例中断事件,在中断回收前5分钟保存Checkpoint文件,以减少恢复训练时的进度损失。改良后的架构如下:

建立完善的任务恢复机制
本文示例中恢复训练时,会自动从最新的Checkpoint恢复,但不会检测其有效性。在实际应用中,建议建立异常检测机制,以排除无效Checkpoint,并自动从最新的有效Checkpoint恢复训练。
完善训练任务执行结束的操作
您可以在训练代码中补充训练结束的判断逻辑,在训练结束时使用CLI或SDK等方式调用伸缩组的API,将期望实例数修改为0,伸缩组会自动根据期望实例数释放多余实例,避免资源浪费造成的额外开支。
此外,还可以在任务完成时,向云监控上报自定义事件,将训练执行结果以邮件、短信、钉钉机器人等方式通知到您。
使用效率更高的OSFS存储模型与Checkpoint文件
训练大参数量模型时,对象存储可能成为系统瓶颈,建议使用高吞吐、低延迟的CPFS替代对象存储作为文件系统挂载,以提高系统整体效率。
配置多可用区交换机,提高抢占式实例的使用概率
仅配置单个可用区交换机时,伸缩组仅能从一个可用区创建实例,容易因库存不足导致扩容失败。建议配置多个可用区的交换机,在抢占式实例被回收时,系统会自动尝试从其他可用区创建新的抢占式实例,有效提高抢占式实例的使用概率。