
准备工作
本文介绍数据迁移之前的准备工作。
步骤一:上传列表文件
HTTP/HTTPS列表文件包括两类文件,一个manifest.json文件和多个example.csv.gz文件。example.csv.gz为压缩后的CSV列表文件,单个example.csv.gz文件大小不超过100 MB,manifest.json文件定义了清单的schema信息以及一系列CSV文件。
创建CSV列表文件
在本地创建CSV格式的列表文件。每行表示一个文件,行与行之间用\n分割。每个文件有多个属性项,项与项之间用英文逗号(,)分割。
重要Key和Url为必填项,其余项可以不填写。
每行必须要以换行符结束,否则会因为CSV解析失败导致任务异常中断。
必填项
名称
是否必填
描述
说明
Url
是
在线迁移服务使用该链接的Get请求下载文件内容,Head请求获取文件元数据。
说明Url需确保可以直接使用[curl --HEAD "$Url"]、[curl --GET "$Url"]等命令正常访问。在线迁移服务不支持重定向的$Url。
Url和Key项必须要做编码处理,不做编码处理、包含特殊字符可能会导致文件迁移失败。
Url项的编码原则:在
curl等命令行工具(非重定向)可正常访问的基础上,再进行一次Url编码。Key项的编码原则:在您期望该文件在OSS上的ObjectName基础之上,再进行一次Url编码。
重要Url和Key项做编码处理后,请务必进行以下内容确认,否则可能会导致文件迁移失败,或迁移到目的端的文件路径与您的预期不符。
原字符串中的加号(+)已被编码成%2B。
原字符串中的百分号(%)已被编码成%25。
原字符串中的半角逗号(,)已被编码成%2C。
例如,原字符串为
a+b%c,d.file,编码后的字符串应该是a%2Bb%25c%2Cd.file。Key
是
迁移后的Object Name为prefix+文件名。
假设您已生成未进行url编码的CSV文件,名称为plain_example.csv,该文件仅有两列,第一列为Url,这些Url可直接使用curl命令进行访问;第二列为Key,这些Key即为您期望该文件在OSS上的ObjectName。如下:
https://help-static-aliyun-doc.aliyuncs.com/assets/img/zh-CN/1354977961/p486238.jpg,assets/img/zh-CN/1354977961/p486238.jpg https://www.example-fake1.com/%E7%BC%96%E7%A0%81%E5%90%8E%E6%89%8D%E8%83%BD%E8%AE%BF%E9%97%AE%E7%9A%84url/123.png,编码后才能访问的url/123.png https://www.example-fake2.com/无需编码即可访问的url/123.png,无需编码即可访问的url/123.png https://www.example-fake3.com/汉语/日本語にほんご/한국어/123.png,汉语/日本語にほんご/한국어/123.png重要请勿在Windows系统下使用自带的记事本软件编辑manifest.json或plain_example.csv,因为该软件可能会在文件内容起始3个字节添加特殊标记(0xefbbbf),从而可能引发在线迁移服务的解析异常。您可以在Linux或macOS下执行
od -c plain_example.csv | less确认文件内容的起始3字节是否包含特殊标记。Windows系统下建议您使用Notepad++、Visual Studio Code等软件创建或编辑文件。如下Python编码示例代码将会按行读取plain_example.csv,并将编码后的结果输出到example.csv。代码仅供您参考,请根据实际需要进行适当修改。
# -*- coding: utf-8 -*- import sys if sys.version_info.major == 3: from urllib.parse import quote_plus else: from urllib import quote_plus reload(sys) sys.setdefaultencoding("utf-8") # Source CSV file path. src_path = "plain_example.csv" # URL-encoded file path. out_path = "example.csv" # The sample CSV contains only two columns: url and key. with open(src_path) as fin, open(out_path, "w") as fout: for line in fin: items = line.strip().split(",") url, key = items[0], items[1] enc_url = quote_plus(url.encode("utf-8")) enc_key = quote_plus(key.encode("utf-8")) # The enc_url and enc_key vars are encoded format. fout.write(enc_url + "," + enc_key + "\n")运行上述代码,输出后的example.csv内容为:
https%3A%2F%2Fhelp-static-aliyun-doc.aliyuncs.com%2Fassets%2Fimg%2Fzh-CN%2F1354977961%2Fp486238.jpg,assets%2Fimg%2Fzh-CN%2F1354977961%2Fp486238.jpg https%3A%2F%2Fwww.example-fake1.com%2F%25E7%25BC%2596%25E7%25A0%2581%25E5%2590%258E%25E6%2589%258D%25E8%2583%25BD%25E8%25AE%25BF%25E9%2597%25AE%25E7%259A%2584url%2F123.png,%E7%BC%96%E7%A0%81%E5%90%8E%E6%89%8D%E8%83%BD%E8%AE%BF%E9%97%AE%E7%9A%84url%2F123.png https%3A%2F%2Fwww.example-fake2.com%2F%E6%97%A0%E9%9C%80%E7%BC%96%E7%A0%81%E5%8D%B3%E5%8F%AF%E8%AE%BF%E9%97%AE%E7%9A%84url%2F123.png,%E6%97%A0%E9%9C%80%E7%BC%96%E7%A0%81%E5%8D%B3%E5%8F%AF%E8%AE%BF%E9%97%AE%E7%9A%84url%2F123.png https%3A%2F%2Fwww.example-fake3.com%2F%E6%B1%89%E8%AF%AD%2F%E6%97%A5%E6%9C%AC%E8%AA%9E%E3%81%AB%E3%81%BB%E3%82%93%E3%81%94%2F%ED%95%9C%EA%B5%AD%EC%96%B4%2F123.png,%E6%B1%89%E8%AF%AD%2F%E6%97%A5%E6%9C%AC%E8%AA%9E%E3%81%AB%E3%81%BB%E3%82%93%E3%81%94%2F%ED%95%9C%EA%B5%AD%EC%96%B4%2F123.png全部项
名称
是否必填
说明
Key
是
迁移后的Object Name为prefix+文件名。
Url
是
在线迁移服务使用该链接的Get请求下载文件内容,Head请求获取文件元数据。
Size
否
迁移文件的大小,单位为字节(Byte)。
说明该字段用于统计迁移文件的存储量,缺失该字段会导致控制台展示的存储量图表不可用。
说明以上示例中各项的顺序并非固定顺序,只需与manifest.json文件中fileSchema项顺序保持一致即可。
压缩CSV文件
需要将CSV文件压缩为csv.gz文件,压缩方法如下:
压缩单个文件
例如dir目录下有一个文件example.csv,需执行如下压缩命令:
gzip -c example.csv > example.csv.gz说明执行以上
gzip命令压缩文件,不会保留源文件,如需保留源文件压缩,请执行命令gzip -c 源文件 > 源文件.gz。压缩后得到
.csv.gz文件。压缩多个文件
例如dir目录下有三个文件example1.csv、example2.csv和 example3.csv,需执行如下压缩命令:
gzip -r dir说明gzip命令不会打包目录,而是将指定目录下所有子文件分别进行压缩,且不会保留对应的源文件。压缩后在dir目录下得到三个文件example1.csv.gz、example2.csv.gz和example3.csv.gz。
创建manifest.json文件
支持配置多个CSV文件,具体内容如下。
fileFormat:指定列表文件格式为CSV
fileSchema:对应CSV中文件项,请注意顺序。
说明请确保CSV文件中的列数目与该配置中字段数目保持一致,迁移服务会校验两者是否一致。
files:
key:CSV文件在Bucket中的位置。
MD5checksum:16进制的MD5字符串,不区分大小写。例如:91A76757B25C8BE78BC321DEEBA6A5AD,如果不填写该值,则不会做校验。
size:列表文件大小。
如下示例仅供您参考。
{ "fileFormat":"CSV", "fileSchema":"Url, Key", "files":[{ "key":"dir/example1.csv.gz", "MD5checksum":"", "size":0 },{ "key":"dir/example2.csv.gz", "MD5checksum":"", "size":0 }] }将创建的清单文件上传到OSS或AWS S3。
上传manifest.json文件和压缩后的CSV列表文件,CSV列表文件名需要与manifest.json中的CSV文件名匹配。
记录mainifest.json文件路径,后续创建源数据地址时需填写清单所在的位置信息。
步骤二:创建目标存储空间
创建目标存储空间,用于存放迁移的数据。具体操作,请参见创建存储空间。
步骤三:创建RAM用户并添加权限
该RAM用户用于迁移使用。在创建角色和进行迁移实施操作时,需要在该用户下进行操作。请尽量在源Bucket或者目的Bucket所在的主账号下创建该RAM用户。
如果没有创建RAM用户,可以创建RAM用户并授权。
登录主账号所在的RAM控制台,在用户页面,单击刚创建的RAM用户操作列的添加权限。
系统策略:管理在线迁移服务的权限(AliyunOSSImportFullAccess)。
自定义权限策略:该策略必须包含
ram:CreateRole、ram:CreatePolicy、ram:AttachPolicyToRole、ram:ListRoles权限。可参考创建自定义权限策略进行权限管理,以下是相关的权限策略脚本代码:
{ "Version":"1", "Statement":[ { "Effect":"Allow", "Action":[ "ram:CreateRole", "ram:CreatePolicy", "ram:AttachPolicyToRole", "ram:ListRoles" ], "Resource":"*" } ] }
步骤四:清单Bucket授权
请根据清单Bucket是否归属于本账号,完成相应的操作。
清单Bucket归属于本账号
一键自动授权:
强烈建议您使用迁移控制台授权角色进行一键授权操作,该操作请在迁移实施 > 步骤二 > 列表授权角色 中实施。
手动授权:
清单Bucket授权
在角色页面,单击刚创建的RAM角色 操作 列的 新增授权。
自定义权限策略:该策略必须包含
oss:List*、oss:Get*权限。
可参考创建自定义权限策略进行权限管理,以下是相关的权限策略脚本代码:
说明以下权限策略仅供您参考,其中<myInvBucket>为本账号下的清单Bucket名称,请根据实际值替换。
关于OSS权限策略的更多信息,请参见RAM Policy常见示例。
重要如果清单Bucket中有KMS加密的Object,您还需要为角色授予AliyunKMSFullAccess系统策略。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "oss:List*", "oss:Get*" ], "Resource": [ "acs:oss:*:*:<myInvBucket>", "acs:oss:*:*:<myInvBucket>/*" ] } ] }
清单Bucket不归属于本账号
清单Bucket授权
使用清单Bucket所属账号登录OSS管理控制台。
在左侧导航栏,单击 Bucket 列表,选择对应Bucket。
在左侧导航栏,选择权限控制 > Bucket 授权策略。
在语法策略添加中,增加以下Bucket Policy,然后点击 编辑并保存。
自定义策略:
授予RAM角色列举并读取该Bucket下所有资源的权限
说明以下权限策略仅供您参考,其中<otherInvBucket>为 清单Bucket名称,<myuid>为 迁移控制台主账号UID,<otherUid>为 清单Bucket归属的主账号UID,<roleName>为上文创建的角色名称,请根据实际值替换。关于OSS权限策略的更多信息,请参见RAM Policy常见示例。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "oss:List*", "oss:Get*" ], "Principal": [ "arn:sts::<myUid>:assumed-role/<roleName>/*" ], "Resource": [ "acs:oss:*:<otherUid>:<otherInvBucket>", "acs:oss:*:<otherUid>:<othereInvBucket>/*" ] } ] }
2 . KMS授权
如果清单Bucket中有KMS加密的Object,您还需要为角色授予AliyunKMSFullAccess系统策略。
如果清单Bucket中有Object使用的是自定义的KMS密钥,您还需要对该KMS密钥授权角色的访问,具体步骤为:
登录密钥管理服务控制台,找到对应的密钥。
设置密钥策略,选择其它账号使用者,填写授权主体ARN。具体步骤,请参见设置密钥策略。

步骤五:目的Bucket授权
请根据目的Bucket是否归属于本账号,完成相应的操作。
目的Bucket归属于本账号
一键自动授权:
强烈建议您使用迁移控制台自动授权角色进行一键授权操作,该操作请在迁移实施 > 步骤三 > 授权角色 中实施。
手动授权:
说明手动授权适用于具有特定需求的场景,例如:
为了有效管理多个源Bucket,期望通过一个角色实现对多个Bucket的批量授权。
当前账户现有的角色数量即将达到上限,因此不希望再创建过多额外的RAM角色。
其他不适合或无法使用一键自动授权的场景。
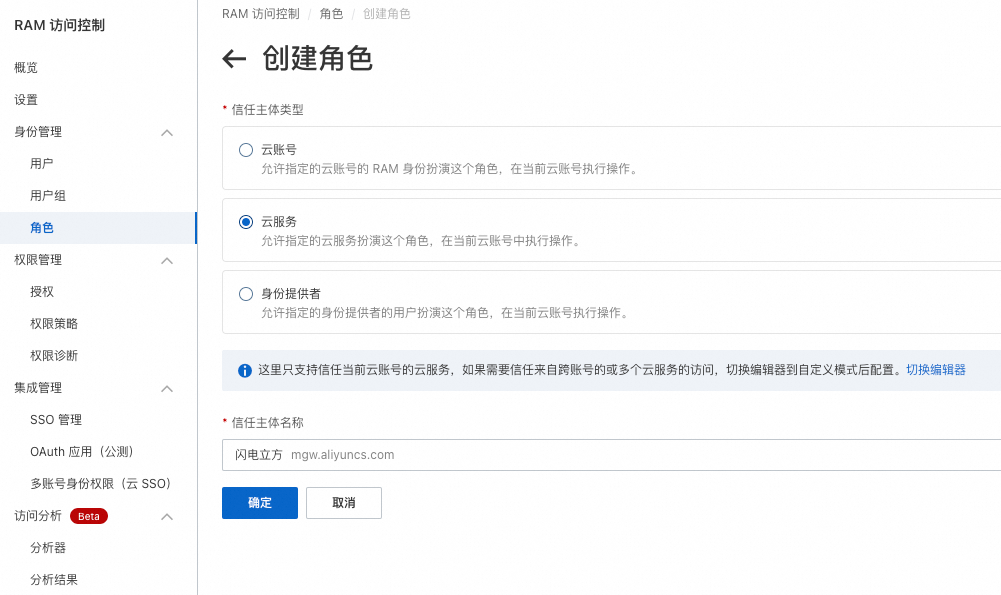
1. 创建用于迁移数据的RAM角色
登录上文创建的RAM用户所在的RAM控制台,在角色详情页面单击创建角色。
信任主体类型选择云服务。
信任主体名称选择闪电立方。
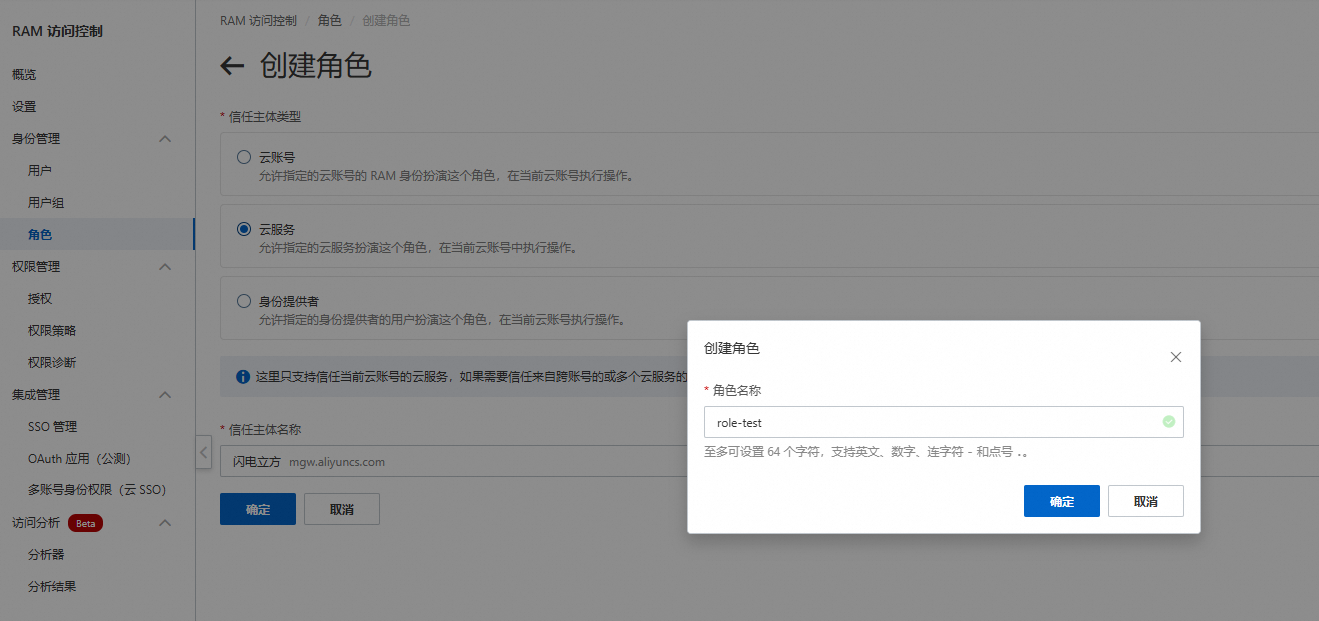
输入角色名称(角色名称务必全部小写)。
2. 目的Bucket授权
在角色页面,单击刚创建的RAM角色 操作 列的 新增授权。
自定义策略:该策略必须包含
oss:List*、oss:Get*、oss:Put*、oss:AbortMultipartUpload*权限。
可参考创建自定义权限策略 进行权限管理,以下是相关的权限策略脚本代码:
说明以下权限策略仅供您参考,其中<myDestBucket>为 本账号下的目的Bucket名称,请根据实际值替换。
关于OSS权限策略的更多信息,请参见RAM Policy常见示例。
重要如果目的Bucket配置了服务端KMS加密,您还需要为角色授予AliyunKMSFullAccess系统策略。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "oss:List*", "oss:Get*", "oss:Put*", "oss:AbortMultipartUpload" ], "Resource": [ "acs:oss:*:*:<myDestBucket>", "acs:oss:*:*:<myDestBucket>/*" ] } ] }
目的Bucket不归属于本账号
1. 创建用于迁移数据的RAM角色
登录上文创建的RAM用户所在的RAM控制台,在角色详情页面单击创建角色。
信任主体类型选择云服务。
信任主体名称选择闪电立方。
输入角色名称(角色名称务必全部小写)。
2. 目的Bucket授权
在使用Bucket Policy按语法策略进行授权时,新添加的策略会覆盖已有的策略。请确保新添加的策略包含已有策略的内容,否则可能导致关联已有策略的操作失败。
使用目的Bucket所属账号登录OSS管理控制台,
在左侧导航栏,单击 Bucket 列表,选择对应Bucket。
在左侧导航栏,选择 权限控制 > Bucket 授权策略。
在按语法策略添加 页签,点击编辑,增加自定义Bucket Policy。
授予RAM角色列举、读取、删除和写入该Bucket下所有资源的权限。
以下权限策略仅供您参考,其中<otherDestBucket>填写 目的Bucket名称,<otherUid>填写 目的Bucket归属的主账号UID,<myUid>填写 迁移控制台主账号UID,<roleName>填写 上文创建的角色名称,请根据实际值替换。关于OSS权限策略的更多信息,请参见RAM Policy常见示例。
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": [
"oss:List*",
"oss:Get*",
"oss:Put*",
"oss:AbortMultipartUpload"
],
"Principal": [
"arn:sts::<myUid>:assumed-role/<roleName>/*"
],
"Resource": [
"acs:oss:*:<otherUid>:<otherDestBucket>",
"acs:oss:*:<otherUid>:<otherDestBucket>/*"
]
}
]
}3. KMS授权
如果目的Bucket配置了服务端KMS加密,您还需要为角色授予AliyunKMSFullAccess系统策略。
如果目的Bucket服务端加密使用自定义KMS密钥,您还需要对该KMS密钥授权角色的访问,具体步骤为:
登录密钥管理服务控制台,找到对应的密钥。
设置密钥策略,选择其它账号使用者,填写授权主体ARN。具体步骤,请参见设置密钥策略。
