本教程通过分析2023年浙江省考生报考的省份,以及不同省份居民对于食物的消费观念,预测在哪个城市摆摊能获得更多收益。教程采用DataV-Note(智能分析)完成对原始高考数据的清洗、查看及分析操作,并将分析结果生成报告,进行查阅分享。
教程简介
背景介绍
通常,大学生作为小吃摊的主要受众群体,有助于带动摆摊经济的增长。我们将运用智能分析,借助2023年浙江省的学校报考数据,探究浙江的学生都流向了哪些地区;同时,对各地区的食品偏好程度进行分析,基于分析结果,针对性地去对应地区摆小吃摊。
分析流程
本教程的分析流程如下图。

数据清洗:首先对获取到的多个高考数据进行整合,生成一张包含所有高校及招生信息的汇总表。后续将基于该表进行查询分析。
数据概览:基于汇总表进行查询,可查看各高校的报考信息概况、录取情况及各城市的教育水平。
数据分析:
基于分析结果,我们可以将获得的“考生报考热度高,且居民食品消费指数较高的地区”视为摆摊收益更为显著的区域。
生成分析报告:您可将分析过程发布为分析报告,导出或分享给他人使用。
分析工具
整个分析过程,将会使用DataV-Note的如下分析单元:
SQL分析:通过SQL语句整合原始数据,以及对结果数据进行查询分析操作。
智能报告:使用自然语言一键分析学生报考的意向省份,以及省份与录取分数的关系,并生成分析报告。
Python分析:通过Python语句进行线性回归分析,探索省份与平均分数线是否存在线性趋势。
可视化分析:通过图表可视化展示分析结果。
文本分析:使用Markdown文本分析单元,编写报告相关介绍,辅助理解分析过程。
效果展示
完成本教程后,您将输出类似如下样式的分析报告。
准备数据
请下载如下数据至本地,后续需将该数据上传至DataV-Note,进行相关查询分析操作。
原始数据 | 作用 |
存放浙江省2023年普通类高校招生投档分数线数据,以及高校信息数据(例如,所在省份、城市等)。 用于分析各省份的分数线及招生计划。 | |
用于分析各个城市的人均消费支出。 | |
用于分析各个城市的食品平均消费量。 |
该数据为样例数据,仅用于学习和交流。
创建项目并上传数据
数据清洗:整合高校信息
由于获取到的三个原始文件数据(招生一段线、招生二段线、高校信息)均包含高校相关信息,且存在信息重合情况,为避免多次查询导致分析过程繁琐,在进行数据分析前,需先对这些数据进行整合。
创建SQL分析单元。
在报告编辑区域,单击
 图标,创建SQL分析单元。
图标,创建SQL分析单元。进行数据整合。
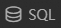
选择文件数据集(上传的招生表存放于此),运行如下SQL语句。合并两个招生表数据,通过学校名称与高校信息表进行连接,生成一张包含高校信息及招生数据的汇总表,并将汇总表重命名为school。
生成的汇总表将展示在左侧导航栏的查询结果集中,后续会基于该查询结果集进行查询分析。
数据概览:查看高校信息概况
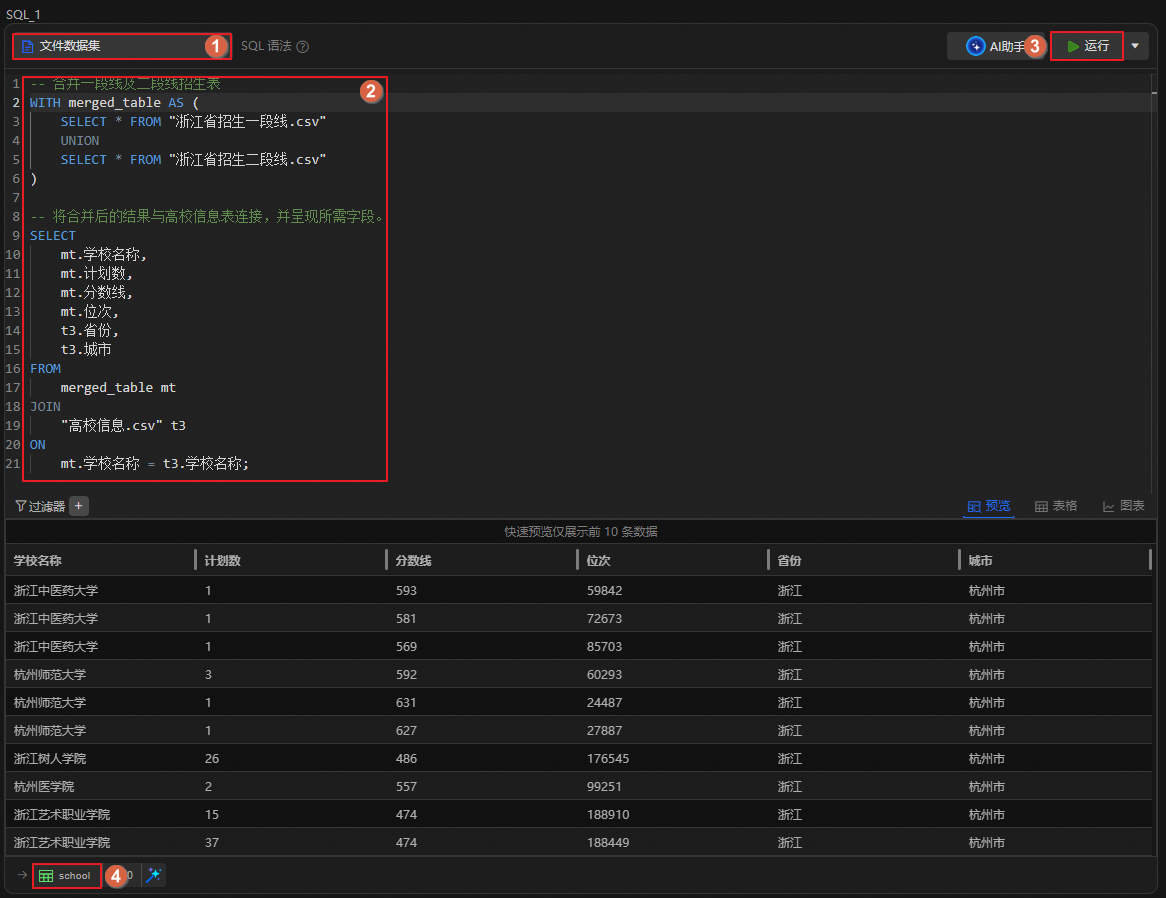
在该步骤,可使用SQL查看相关数据详情,了解高校信息概况。您可参考如下语句进行查询,也可自行编写SQL查询语句。
查看高校汇总表概况
单击
图标,创建SQL分析单元。运行如下语句,查看汇总表数据详情。
查看各高校的录取情况
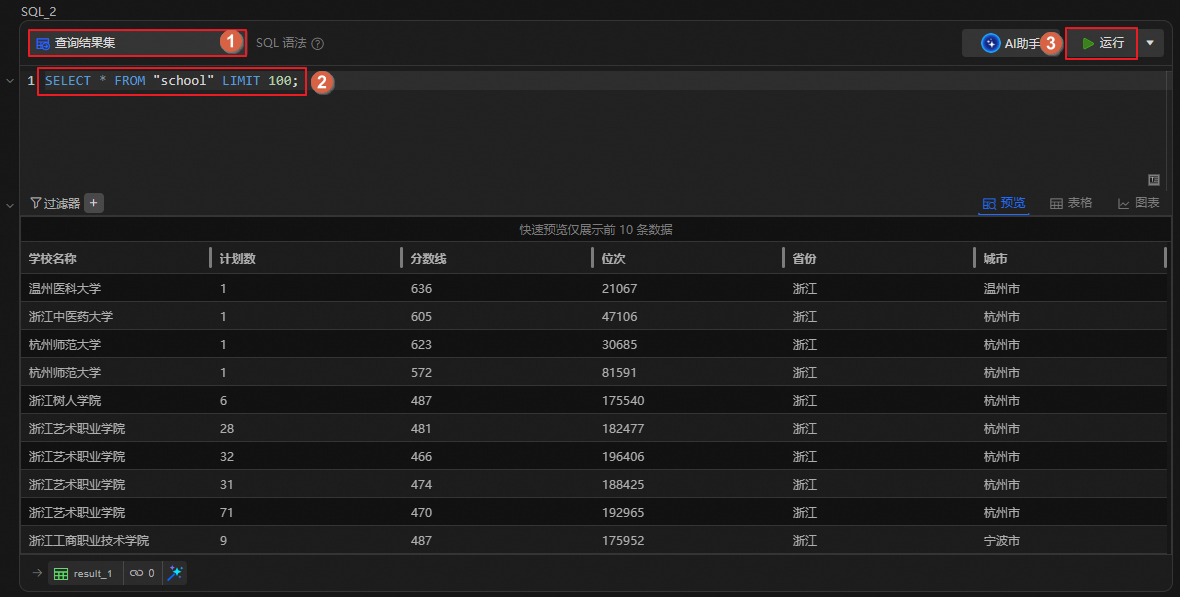
基于高校汇总表,统计每个学校的计划数、分数线及位次,并按分数线降序排列,以便了解不同学校的录取分数和表现。
单击
图标,创建SQL分析单元。运行如下语句,查看各个学校的录取情况。
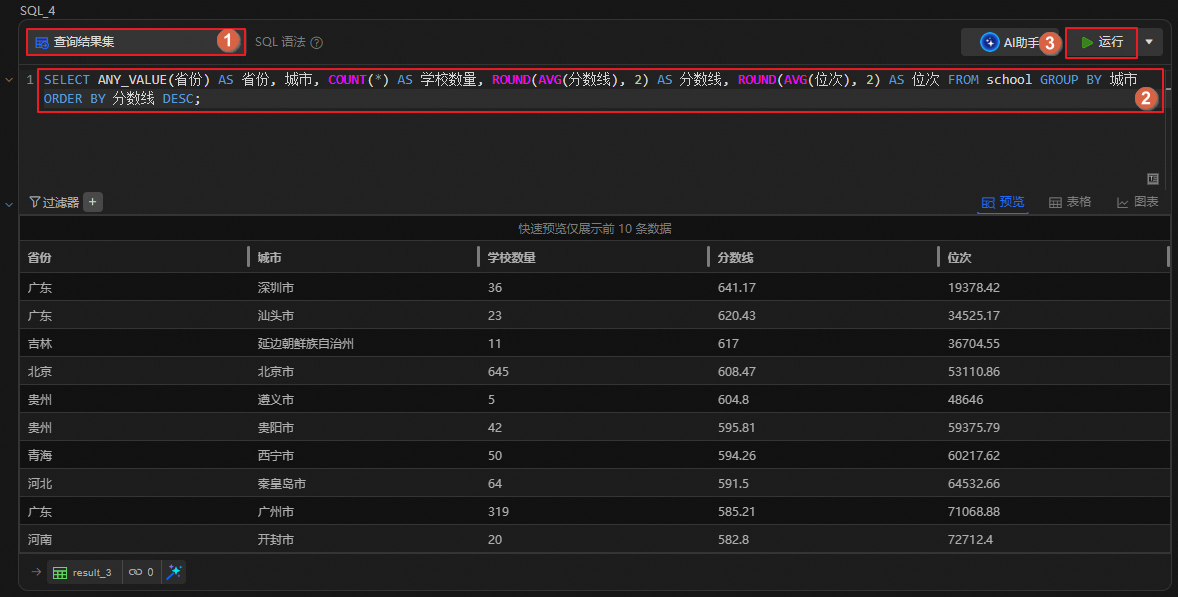
查看各城市的教育水平
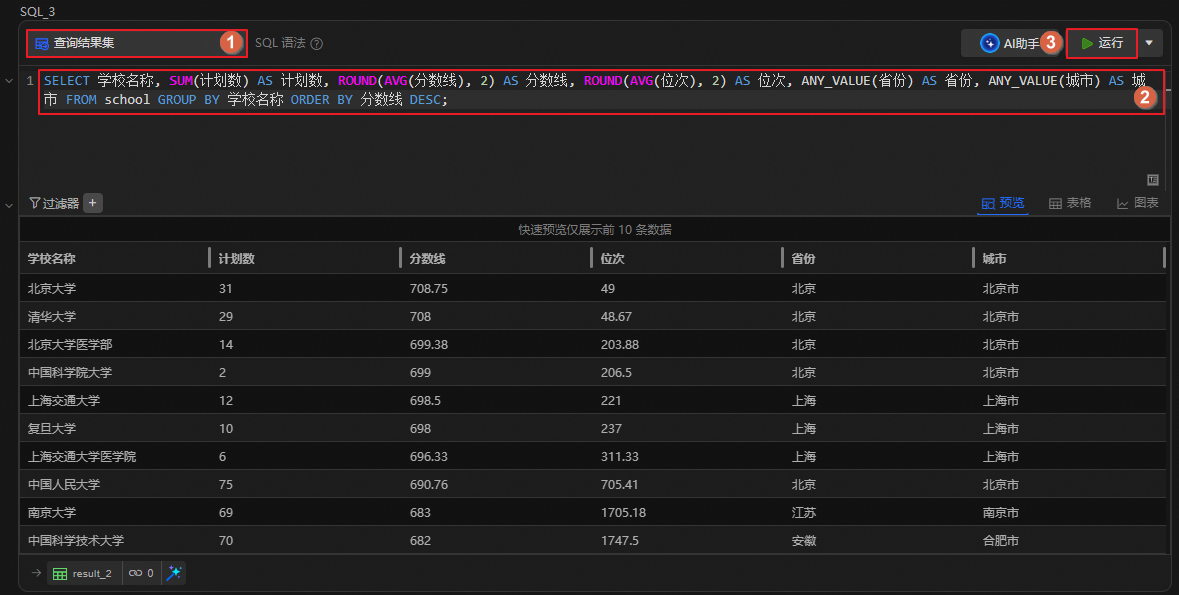
统计每个城市中学校的数量,以及分数线和位次的平均值,并按分数线降序排序,以便了解不同城市的教育水平。
单击
图标,创建SQL分析单元。运行如下语句,查看各个城市的教育水平。
数据分析:报考热度及差异
至此,将正式进入报告的分析及编写阶段。在该步骤,我们将借助Data-Note的AI能力,输出分析思路及分析过程,了解各地区的学校招生情况、录取标准及报考热度,并评估地域是否会影响录取分数线。
智能分析是系统根据您输入的需求,自动分析并匹配相应算法,输出合适结果。因此,即使每次输入的描述相同,生成的分析过程也可能存在差异,但不会影响最终的结论导向,具体请以实际界面为准。
智能分析生成的报告您可直接使用,也可基于该报告进行二次编辑。为保障报考热度及差异分析与后文饮食消费指数分析的关联性,本文示例使用智能分析体验生成分析思路,并通过手动操作体验核心分析过程。
智能分析操作指引
分析操作
在报告编辑区域单击智能报告,选择数据源为查询结果集中的school(高校信息汇总表),使用自然语言描述您的需求并运行。
示例输入“分析下学生都被招到了哪些省份,以及地域是否影响高校的最低录取分数线”。
分析过程预计需要3~5分钟,请耐心等待。

分析过程
智能分析接收到需求后,将自动为您设计报告结构、生成分析思路、执行分析操作、并总结分析结果。
示例生成的报告结构如下。生成的报告您可直接使用,也可基于该报告进行二次编辑。单击报考热度及差异.pdf,可查看完整的示例报告内容。

各地区学生报考热度排名
在智能分析的指引下,我们将通过如下步骤手动体验核心分析操作。
根据每所学校的所在省份及该省所有院校的总报名人数(即“计划数”之和),计算出各省内高校的整体受欢迎排序。
查看各省的招生计划。
单击
图标,创建SQL分析单元,运行如下语句。查看各省的总计划数,并按总计划数降序排序,将结果表重命名为enrollment_plan。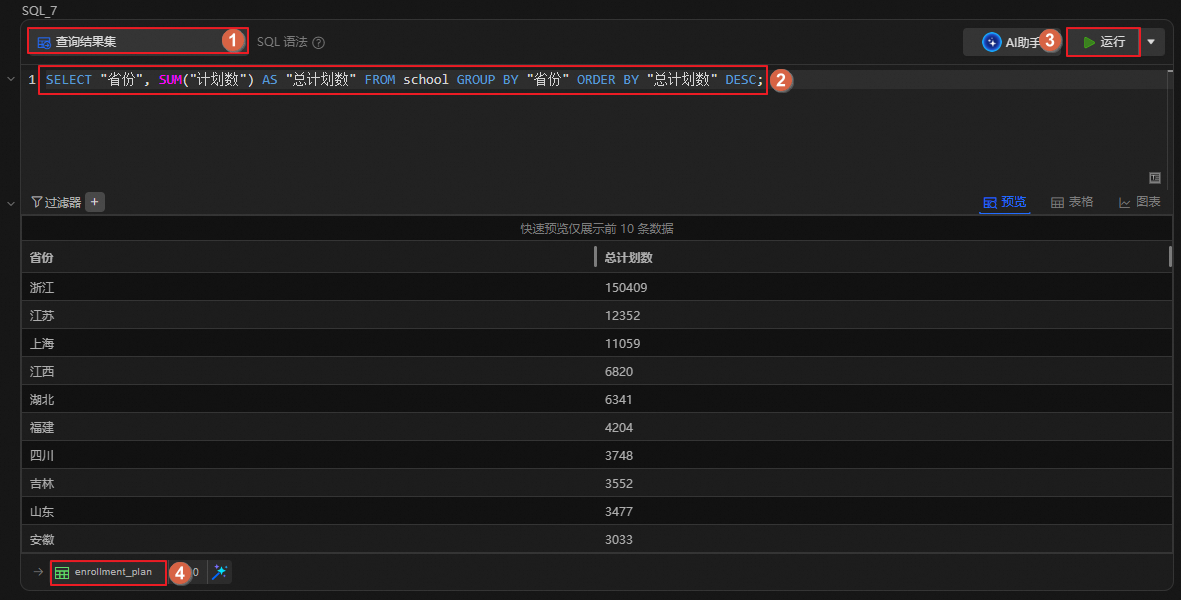
通过图表展示省份分布,观测主导地位占比。
单击,创建图表分析单元,使用饼图展示各省份的总计划数占比。
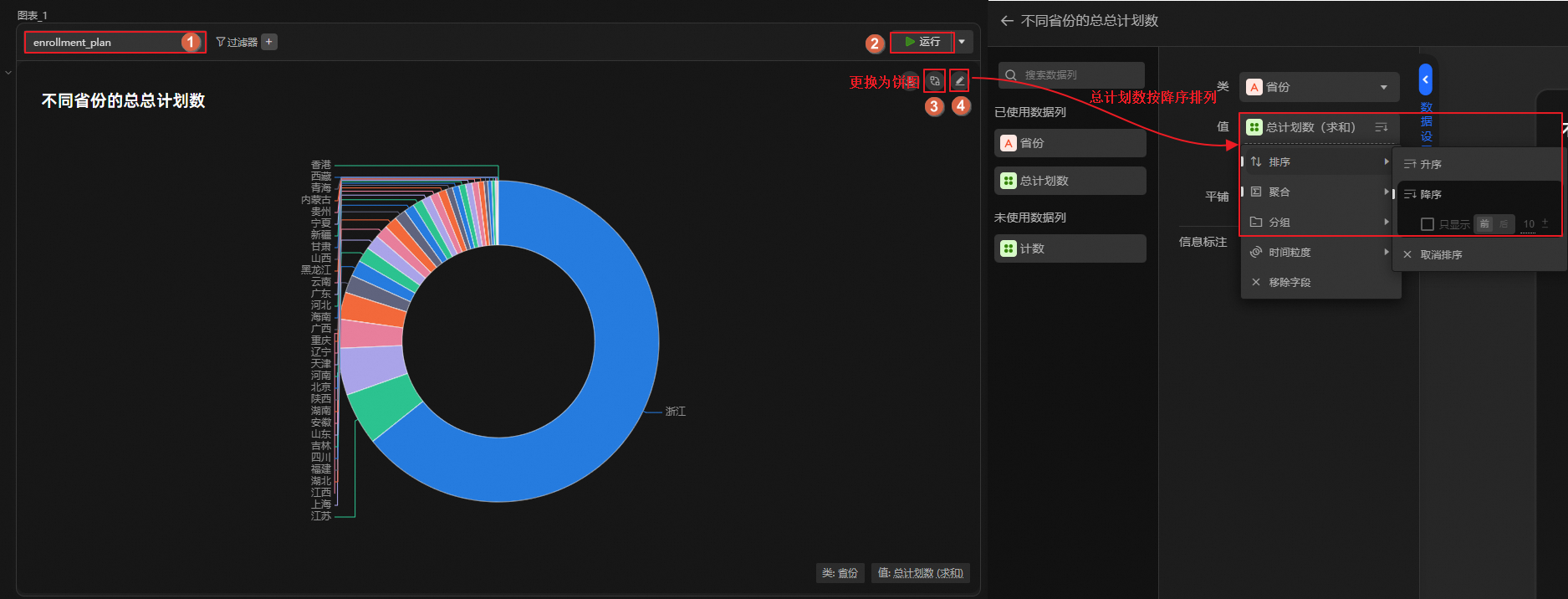
根据上述分析可看出,参与统计的省份中,浙江、江苏、上海、江西、湖北等地对浙江考生的欢迎程度更高。
地域对录取分数线的影响评估
在该步骤,将按照省份分组后求取平均分数线,探索省份与平均分数线是否存在线性趋势,以此衡量地域是否会影响高校的录取分数线。分析过程使用SQL、Python,并结合图表进行可视化展示。
查看各省份总平均分数线。
单击
图标,创建SQL分析单元,运行如下语句。查看各省份的总平均分数线,并按总平均分数线降序排序,将结果表重命名为score_line。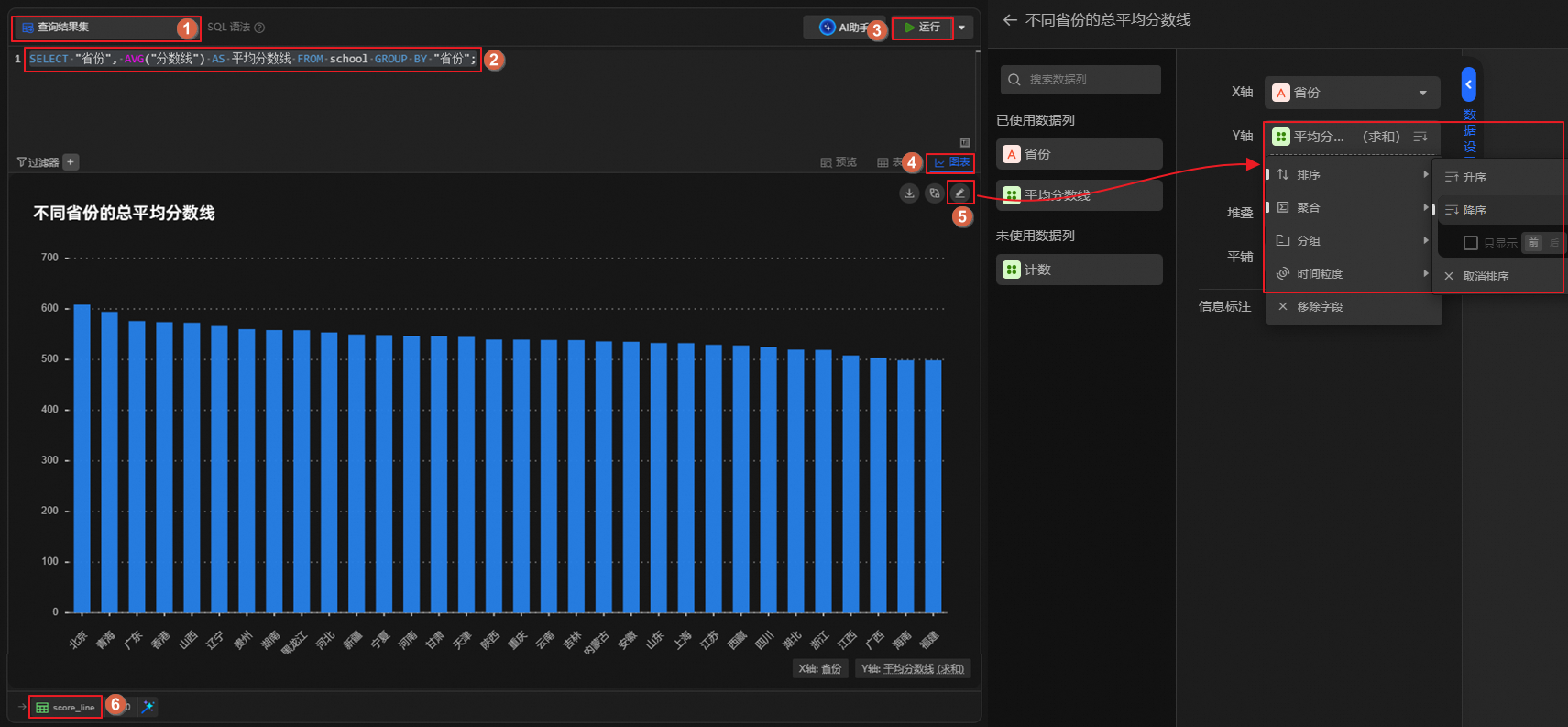
利用数学拟合趋势线,分析省份与招生标准的关联性。
单击,创建Python分析单元,通过如下语句进行线性回归分析,探索省份与平均分数线是否存在线性趋势。
说明nb_toolkit:是一个Python工具库(例如,Notebook管理、版本控制、数据可视化),可在GitHub搜索。
Pandas:是一个Python数据分析库,主要用于数据操作和分析。
Numpy:提供了支持大型多维数组和矩阵的对象,主要用于高效的数值计算和数据分析。
scipy.stats.linregress:用于执行线性回归分析。
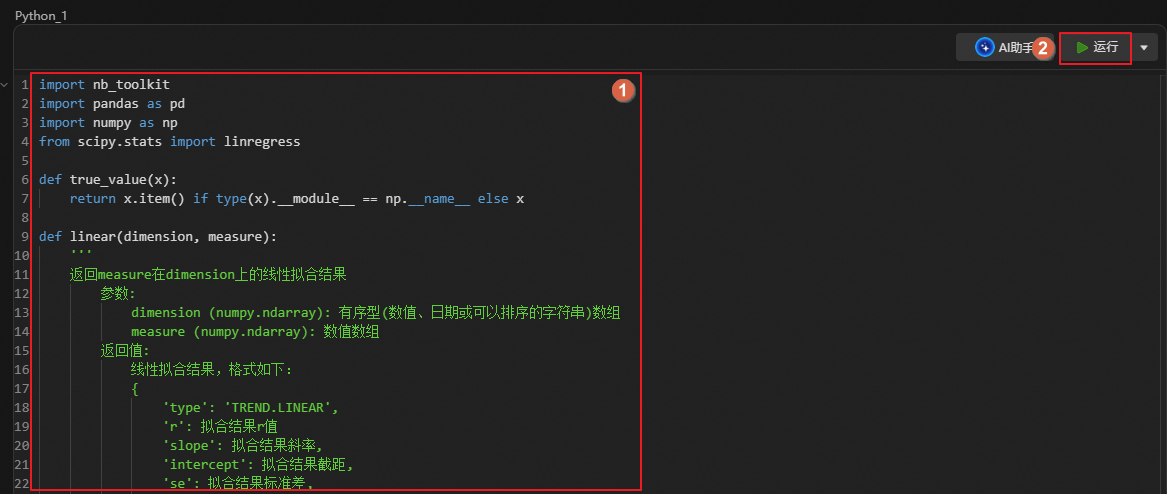
根据上述分析可看出,福建、海南、广西、江西、浙江等省份的总平均分数线相对较低,且地域对学生升学的影响不大。
分析结论
数据分析:饮食消费指数
在该步骤,我们将通过分析各地区居民对食品的偏好指数,预测在哪个地区摆摊会获得更高的收益。分析过程使用SQL,并结合图表进行可视化展示,结合Markdown进行辅助描述。
各地区人均消费支出
编写分析操作介绍。
单击,创建Markdown分析单元,输入如下内容。
计算各地区人均消费支出。
单击
图标,创建SQL分析单元,运行如下语句,计算各地区的居民人均消费支出,按照人均消费支出降序排序,并将结果表重命名为cost。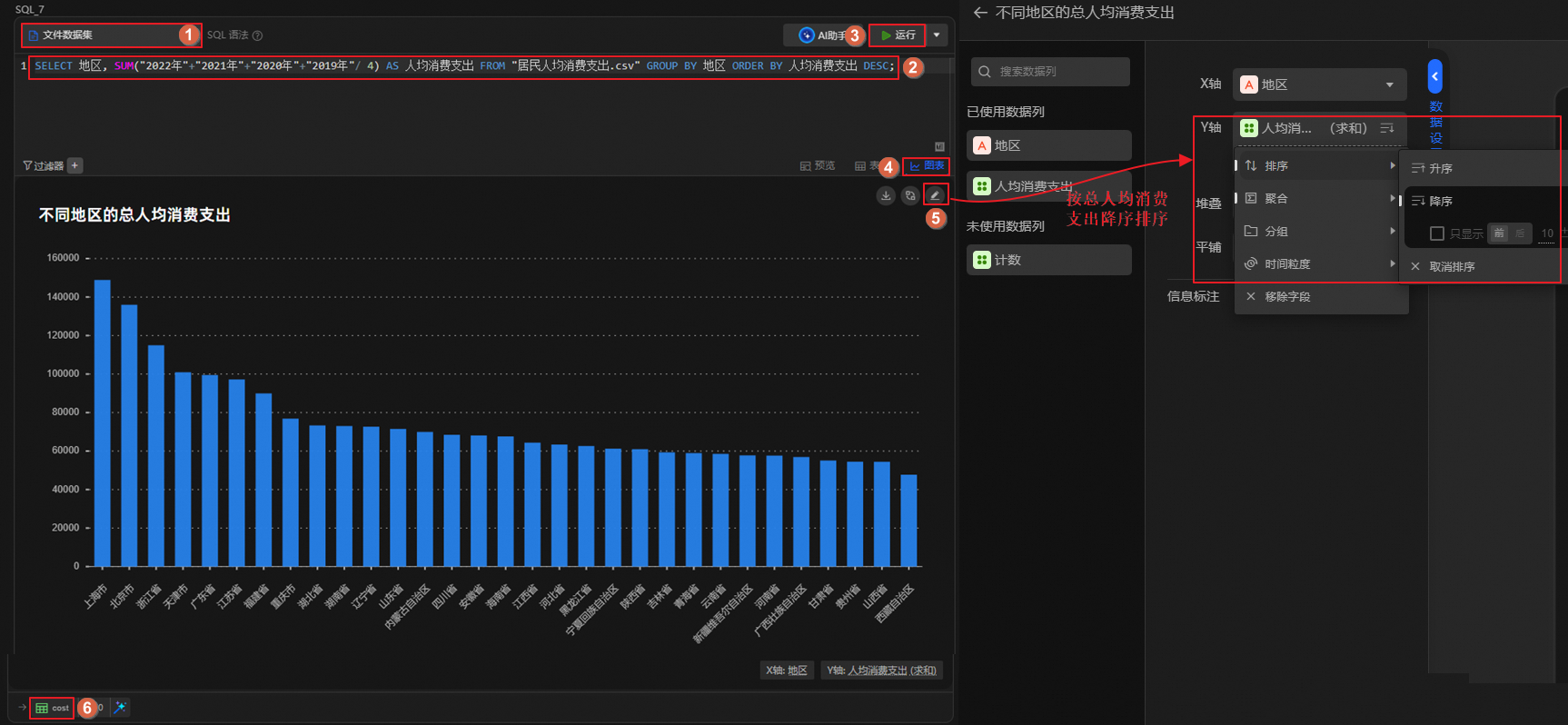
各地区总食品消费量
编写分析操作介绍。
单击,创建Markdown分析单元,输入如下内容。
计算各地区总食品平均消费量。
单击
图标,创建SQL分析单元,运行如下语句。计算各地区居民的总食品平均消费量,按照消费量降序排序,并将结果表重命名为food_like。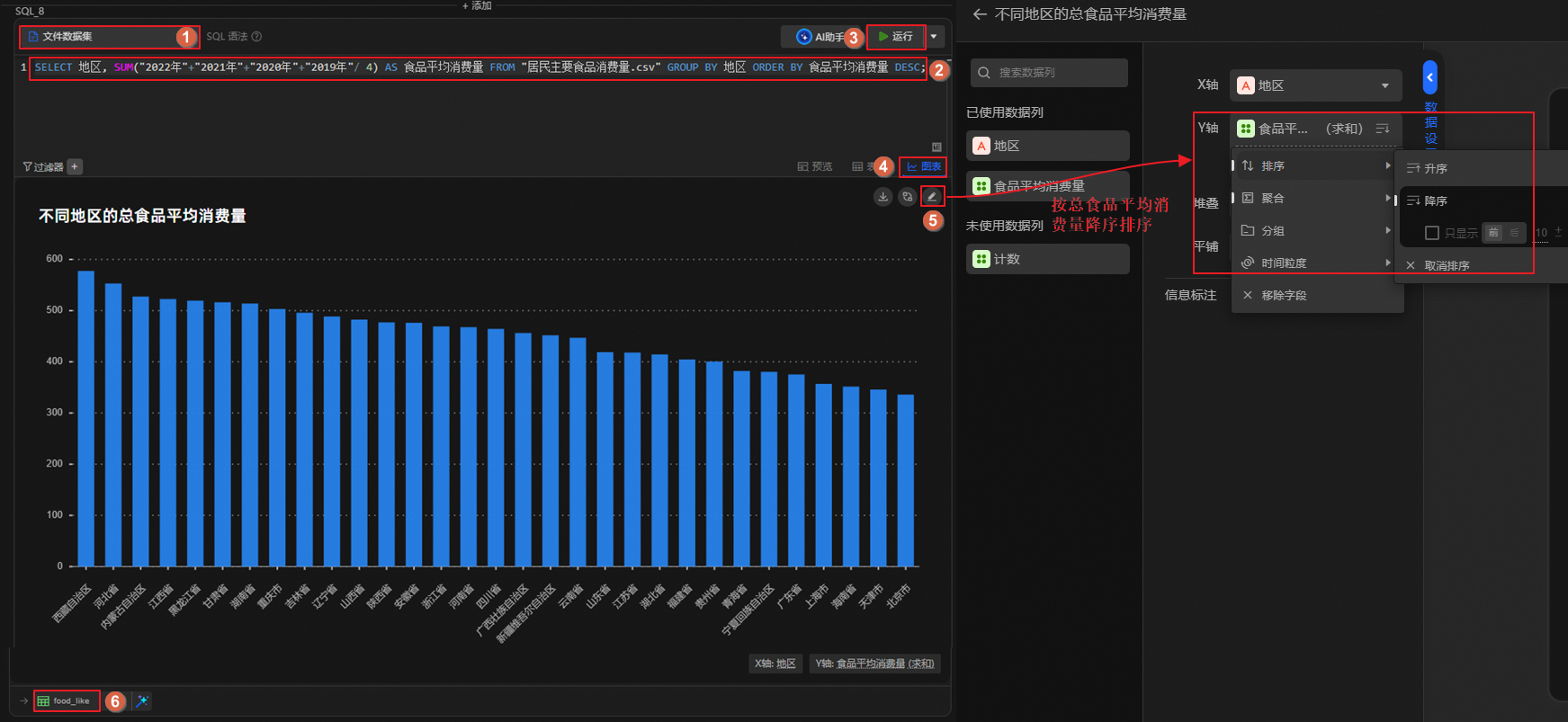
计算食品偏好指数并得出结论
至此,您将结合学生报考热度及差异分析,和居民的食品消费情况,计算出地区的食品偏好指数,并基于分析结果预测收益更高的摆摊地区。
计算食品偏好指数。
单击
图标,创建SQL分析单元,运行如下语句,计算各地区居民的食品偏好指数。说明您可通过如下计算公式,预估各地区的销售利润,利润较高的地区将被视为食品偏好指数较高。
利润 = 小吃单位利润 * 销量 - 自身固定生活开支
= (各省消费水平 / 2000) * (各省计划招生人数 / 10) * 食品平均消费量 / 500 - 消费水平 / 150
各省消费水平 / 2000:预估的小吃单位利润。各省计划招生人数 / 10:预估的购买人数。食品平均消费量 / 500:预估的人均购买量。消费水平 / 150:预估的各省固定生活开支。
计算公式中的各个数值,是基于本文分析情况预估的较为合理的数值,您也可按需调整数值大小。
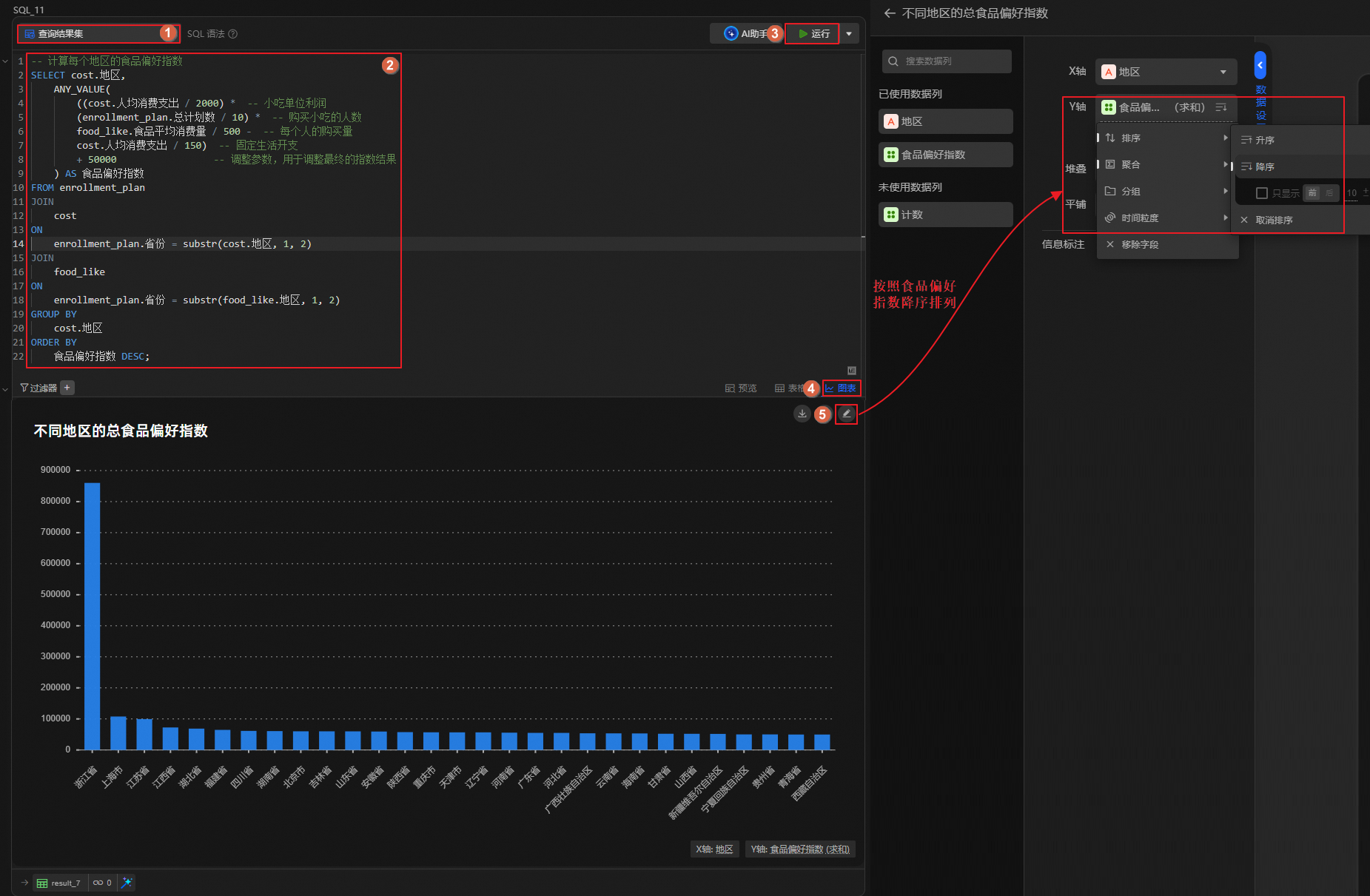
输出结论。
单击,创建Markdown分析单元,输出分析结果。
# 结论与价值 基于计算出的地区食品偏好指数,我们可以看出,浙江、上海、江苏等省份均适合摆小吃摊。 当然,本案例获取的仅是浙江省学生去其他省份的招生数据,未包含其他省份报考相应地区的人数及消费能力,相关结论存在一定局限性。仅供体验功能及参考。
生成分析报告
分析操作执行完成后,您可将分析过程发布为分析报告,并导出或分享给他人查阅。
单击分析界面右上角的预览&发布,将分析结果生成可视化报告。
在报告界面右上角,单击
 图标,即可将该报告导出为指定格式或分享至所需应用。说明
图标,即可将该报告导出为指定格式或分享至所需应用。说明您也可按需进行相关发布设置,调整报告样式。
相关文档
更多分析单元(图表、文本、控件等)的介绍,请参见分析单元使用。
更多核心操作介绍,请参见操作指引。
更多AI体验案例,请参见使用AI一键生成分析报告、AI助力SQL分析:宜居小区案例。