
本文为您介绍在Hologres中聚簇索引Clustering Key使用的相关内容。
Clustering Key介绍
Hologres会按照聚簇索引在文件内对数据进行排序,建立聚簇索引能够加速在索引列上的范围和过滤查询。设置Clustering Key的语法如下,需要建表时指定。
-- Hologres V2.1版本起支持的语法
CREATE TABLE <table_name> (...) WITH (clustering_key = '[<columnName>[,...]]');
-- 所有版本支持的语法
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'clustering_key', '[<columnName>{:asc} [,...]]');
COMMIT;参数说明:
|
参数 |
说明 |
|
table_name |
设置聚簇索引的表名称。 |
|
columnName |
设置聚簇索引的字段名称。 |
使用建议
-
Clustering Key主要适用于点查以及范围查询的场景,对于过滤操作有比较好的性能提升,即对于
where a = 1或者where a > 1 and a < 5的场景加速效果比较好。可以同时设置Clustering Key和Bitmap Column以达到最佳的点查性能。 -
Clustering Key具备左匹配原则,因此一般不建议设置Clustering Key超过两个字段,否则适用场景受限。Clustering Key是用于排序,所以Clustering Key里的列组合是有先后关系的,即排在前面列的排序优先级高于后面的列。
-
指定Clustering Key字段时,可在字段名后添加
:asc来构建索引时的排序方式。排序方式默认为asc,即升序。Hologres V2.1以前版本不支持设置构建索引时的排序方式为降序(desc),如果设置了降序,无法命中Clustering Key,导致查询性能不佳;从V2.1版本开始,开启如下GUC后支持设置Clustering Key为desc,但仅支持Text、Char、Varchar、Bytea、Int等类型的字段,其余数据类型的字段暂不支持设置Clustering Key为desc。set hg_experimental_optimizer_enable_variable_length_desc_ck_filter = on; -
对于行存表,Clustering Key默认为主键 (Hologres V0.9之前版本默认不设置)。如果设置和主键不同的Clustering Key,那么Hologres会为这张表生成两个排序(Primary Key排序和Clustering Key排序),造成数据冗余。
使用限制
-
如需修改Clustering Key,请重新建表并导入数据。
-
Clustering Key必须为not nullable的列或者列组合。Hologres V1.3.20~1.3.27版本支持Clustering Key为nullable,从V1.3.28版本开始不支持Clustering Key为nullable,为nullable的Clustering Key可能会影响数据正确性,如果业务有强需求设置Clustering Key为null,可以在SQL前添加如下参数。
set hg_experimental_enable_nullable_clustering_key = true; -
不支持将Float、Float4、Float8、Double、Decimal(Numeric)、Json、Jsonb、Bit、Varbit、Money、Time With Time Zone及其他复杂数据类型的字段设置为Clustering Key。
-
Hologres V2.1以前版本不支持设置构建索引时的排序方式为降序(
desc),如果设置了降序,无法命中Clustering Key,导致查询性能不佳;从V2.1版本开始,开启如下GUC后支持设置Clustering Key为desc,但仅支持Text、Char、Varchar、Bytea、Int等类型的字段,其余数据类型的字段暂不支持设置Clustering Key为desc。set hg_experimental_optimizer_enable_variable_length_desc_ck_filter = on; -
对于列存表,Clustering Key默认为空,需要根据业务场景显式指定。
-
在Hologres中,每个表只能设置一组Clustering Key。即建表的时候只能使用
call命令一次,不能执行多次,如下示例:-
V2.1版本起支持的建表语法:
--正确示例 CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a,b' ); --错误示例 CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a', clustering_key = 'b' ); -
所有版本支持的建表语法:
--正确示例 BEGIN; CREATE TABLE tbl (a int NOT NULL, b text NOT NULL); CALL set_table_property('tbl', 'clustering_key', 'a,b'); COMMIT; --错误示例 BEGIN; CREATE TABLE tbl (a int NOT NULL, b text NOT NULL); CALL set_table_property('tbl', 'clustering_key', 'a'); CALL set_table_property('tbl', 'clustering_key', 'b'); COMMIT;
-
技术原理
Clustering Key在物理存储上是指在文件内进行排序,默认为升序(asc)。以下介绍Clustering Key的布局概念。
-
逻辑布局。
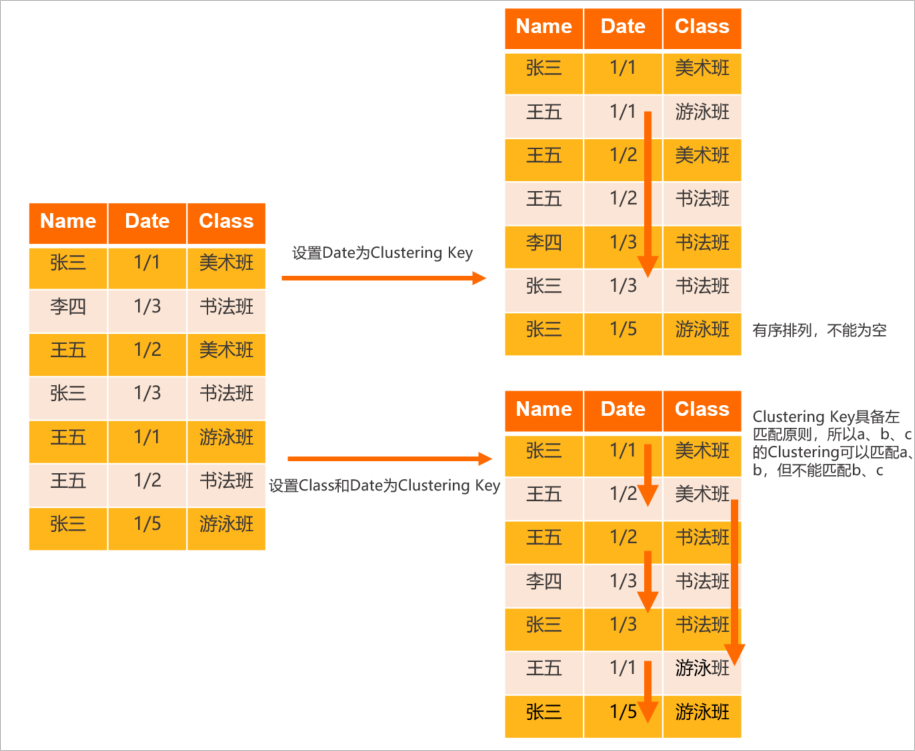
Clustering Key查询具备左匹配原则,不匹配则无法使用Clustering Key查询加速。如下场景示例将为您说明Hologres中Clustering Key的逻辑布局。
准备一张表,其字段分别包括Name、Date、Class。
-
设置Date为Clustering Key,会将表内的数据按照Date进行排序。
-
设置Class和Date为Clustering Key,会对表先按照Class排序后再按照Date进行排序。
设置不同的字段为Clustering Key,其最终的呈现结果也不同,具体如下图所示。
-
-
物理存储布局。
Clustering Key的物理存储布局如下图所示。
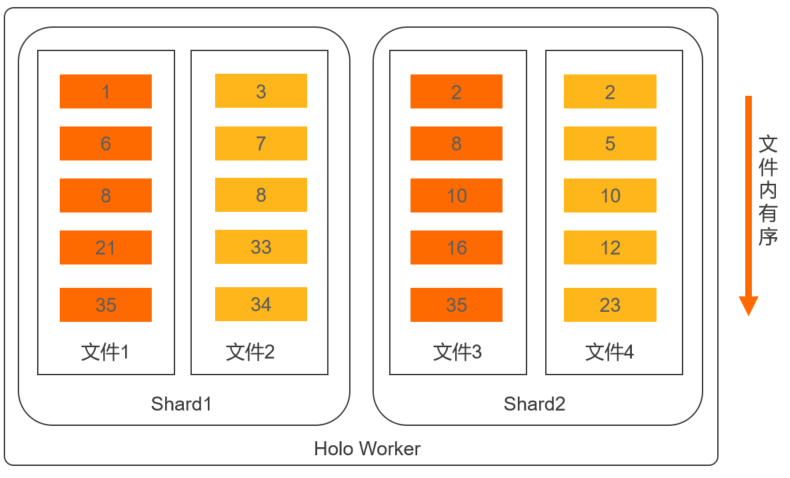
通过Clustering Key的布局原理可以看出:
-
Clustering Key适合范围过滤的场景。比如
where date= 1/1或者where a > 1/1 and a < 1/5的场景加速效果比较好。 -
Clustering Key查询具备左匹配原则,不匹配则无法利用上Clustering Key查询加速。即假设设置
a,b,c三列为Clustering Key,如果是查a,b,c或者查a,b可以命中Clustering Key;如果查a,c只有a可以命中Clustering Key;如果查b,c则无法命中Clustering Key。
如下示例,设置uid,class,date三列为Clustering Key。
-
V2.1版本起支持的语法:
CREATE TABLE clustering_test ( uid int NOT NULL, name text NOT NULL, class text NOT NULL, date text NOT NULL, PRIMARY KEY (uid) ) WITH ( clustering_key = 'uid,class,date' ); INSERT INTO clustering_test VALUES (1,'张三','1','2022-10-19'), (2,'李四','3','2022-10-19'), (3,'王五','2','2022-10-20'), (4,'赵六','2','2022-10-20'), (5,'孙七','2','2022-10-18'), (6,'周八','3','2022-10-17'), (7,'吴九','3','2022-10-20'); -
所有版本支持的语法:
BEGIN; CREATE TABLE clustering_test ( uid int NOT NULL, name text NOT NULL, class text NOT NULL, date text NOT NULL, PRIMARY KEY (uid) ); CALL set_table_property('clustering_test', 'clustering_key', 'uid,class,date'); COMMIT; INSERT INTO clustering_test VALUES (1,'张三','1','2022-10-19'), (2,'李四','3','2022-10-19'), (3,'王五','2','2022-10-20'), (4,'赵六','2','2022-10-20'), (5,'孙七','2','2022-10-18'), (6,'周八','3','2022-10-17'), (7,'吴九','3','2022-10-20');
-
只查
uid列,可以命中Clustering Key。SELECT * FROM clustering_test WHERE uid > '3';通过查看执行计划(explain SQL),如下所示执行计划中有
Cluster Filter算子,表明命中了Clustering Key,查询加速。explain SELECT * FROM clustering_test WHERE uid > '3'; QUERY PLAN Gather (cost=0.00..1.10 rows=4 width=24) -> Exchange (Gather Exchange) (cost=0.00..1.10 rows=4 width=24) -> Decode (cost=0.00..1.10 rows=4 width=24) -> Index Scan using holo_index:[1] on clustering_test (cost=0.00..1.00 rows=4 width=24) Cluster Filter: (uid > 3) Optimizer: HQO version 1.3.0 -
查
uid,class列,可以命中Clustering Key。SELECT * FROM clustering_test WHERE uid = '3' AND class >'1' ;通过查看执行计划(explain SQL),如下所示执行计划中有
Cluster Filter算子,表明命中了Clustering Key,查询加速。explain SELECT * FROM clustering_test WHERE uid = '3' AND class >'1' ; QUERY PLAN Exchange (Gather Exchange) (cost=0.00..1.10 rows=1 width=24) -> Decode (cost=0.00..1.10 rows=1 width=24) -> Index Scan using holo_index:[1] on clustering_test (cost=0.00..1.00 rows=1 width=24) Cluster Filter: ((uid = 3) AND (class > '1'::text)) Shard Selector(Eagerly): ->: l0 [3] Optimizer: HQO version 1.3.0 -
查
uid,class,date三列可以命中Clustering Key。SELECT * FROM clustering_test WHERE uid = '3' AND class ='2' AND date > '2022-10-17';通过查看执行计划(explain SQL),执行计划中有
Cluster Filter算子,表明命中了Clustering Key,查询加速。执行计划结果显示采用Index Scan using holo_index:[1] on clustering_test,其中Cluster Filter条件为((uid = 3) AND (class = '2'::text) AND (date > '2022-10-17'::text)),表明聚簇索引已被正确命中。 -
查
uid,date两列,不符合左匹配原则,因此只有uid可以命中Clustering Key,date则是走普通过滤。SELECT * FROM clustering_test WHERE uid = '3' AND date > '2022-10-17';通过查看执行计划(explain SQL),如下所示执行计划中只有uid列有
Cluster Filter算子。explain SELECT * FROM clustering_test WHERE uid = '3' AND date > '2022-10-17'; QUERY PLAN Exchange (Gather Exchange) (cost=0.00..1.10 rows=1 width=24) -> Decode (cost=0.00..1.10 rows=1 width=24) -> Index Scan using holo_index:[1] on clustering_test (cost=0.00..1.00 rows=1 width=24) Filter: (date > '2022-10-17'::text) Cluster Filter: (uid = 3) Shard Selector(Eagerly): ->: I0 [3] Optimizer: HQO version 1.3.0 -
只查
class,date两列,不符合左匹配原则,都无法命中Clustering Key。SELECT * FROM clustering_test WHERE class ='2' AND date > '2022-10-17';通过查看执行计划(explain SQL),执行计划中没有
Cluster Filter算子,表明未命中Clustering Key。执行 EXPLAIN 后,查询计划显示使用Index Scan,其中date列走Filter,class列走Bitmap Filter,均未通过 Clustering Key 加速。
使用示例
示例1:命中Clustering Key的场景。
-
V2.1版本起支持的语法:
CREATE TABLE table1 ( col1 int NOT NULL, col2 text NOT NULL, col3 text NOT NULL, col4 text NOT NULL ) WITH ( clustering_key = 'col1,col2' ); --如上的建表sql,query可以被加速的情况如下: -- 可加速 select * from table1 where col1='abc'; -- 可加速 select * from table1 where col1>'xxx' and col1<'abc'; -- 可加速 select * from table1 where col1 in ('abc','def'); -- 可加速 select * from table1 where col1='abc' and col2='def'; -- 不可加速 select col1,col4 from table1 where col2='def'; -
所有版本支持的语法:
begin; create table table1 ( col1 int not null, col2 text not null, col3 text not null, col4 text not null ); call set_table_property('table1', 'clustering_key', 'col1,col2'); commit; --如上的建表sql,query可以被加速的情况如下: -- 可加速 select * from table1 where col1='abc'; -- 可加速 select * from table1 where col1>'xxx' and col1<'abc'; -- 可加速 select * from table1 where col1 in ('abc','def'); -- 可加速 select * from table1 where col1='abc' and col2='def'; -- 不可加速 select col1,col4 from table1 where col2='def';
示例2:Clustering Key设置为asc/desc。
-
V2.1版本起支持的语法:
CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a:desc,b:asc' ); -
所有版本支持的语法:
BEGIN; CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ); CALL set_table_property('tbl', 'clustering_key', 'a:desc,b:asc'); COMMIT;
高级调优手段
和传统数据库(MySQL或SQLServer)中的聚簇索引不同,Hologres的排序仅做到了文件内的排序,并非是全表数据的排序,因此在Clustering Key上做order by操作仍然有一定的代价。
Hologres从V1.3版本开始针对Clustering Key的场景使用做了较多的性能优化,实现在使用Clustering Key时有更好的性能,主要包含如下两个场景优化。如果您的版本低于1.3版本,请您使用常见升级准备失败报错或加入Hologres钉钉交流群反馈,详情请参见如何获取更多的在线支持?。
-
针对Clustering Keys做Order By场景
在Hologres中,文件内是按照Clustering Keys定义排序的,但在V1.3版本之前,优化器无法利用文件内的Clustering Keys有序性生成最优执行计划;同时经过Shuffle节点时也无法保障数据有序输出(多路归并),这就容易导致实际的计算量更大,耗时较久。在Hologres V1.3版本针对上面的情况进行优化,保证了生成的执行计划能够利用Clustering Keys的有序性,并能保障跨Shuffle保序,从而提高查询性能。但要注意:
-
当表没有对Clustering Keys做过滤时,默认走的是SeqScan,而不是IndexScan(只有IndexScan才会利用Clustering Keys的有序属性)。
-
优化器并不保障总是生成基于Clustering Keys有序的执行计划,因为利用Clustering Keys有序性是有些代价的(文件内有序但内存中需要额外排序的)。
示例如下。
-
V2.1版本起支持的语法:
DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys; CREATE TABLE test_use_sort_info_of_clustering_keys ( a int NOT NULL, b int NOT NULL, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys SELECT i%500, i%100, i::text FROM generate_series(1, 1000) as s(i); ANALYZE test_use_sort_info_of_clustering_keys;所有版本支持的语法:
DROP TABLE if exists test_use_sort_info_of_clustering_keys; BEGIN; CREATE TABLE test_use_sort_info_of_clustering_keys ( a int NOT NULL, b int NOT NULL, c text ); CALL set_table_property('test_use_sort_info_of_clustering_keys', 'distribution_key', 'a'); CALL set_table_property('test_use_sort_info_of_clustering_keys', 'clustering_key', 'a,b'); COMMIT; INSERT INTO test_use_sort_info_of_clustering_keys SELECT i%500, i%100, i::text FROM generate_series(1, 1000) as s(i); ANALYZE test_use_sort_info_of_clustering_keys; -
查询语句。
explain select * from test_use_sort_info_of_clustering_keys where a > 100 order by a, b; -
执行计划对比
-
V1.3之前版本(V1.1)的执行计划(执行
explainSQL)如下。Sort (cost=0.00..0.00 rows=797 width=11) -> Gather (cost=0.00..2.48 rows=797 width=11) Sort Key: a, b -> Sort (cost=0.00..2.44 rows=797 width=11) Sort Key: a, b -> Exchange (Gather Exchange) (cost=0.00..1.11 rows=797 width=11) -> Decode (cost=0.00..1.11 rows=797 width=11) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys (cost=0.00..1.00 rows=797 width=11) Cluster Filter: (a > 100) -
V1.3版本的执行计划如下。
Gather (cost=0.00..1.15 rows=797 width=11) Merge Key: a, b -> Exchange (Gather Exchange) (cost=0.00..1.11 rows=797 width=11) Merge Key: a, b -> Decode (cost=0.00..1.11 rows=797 width=11) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys (cost=0.00..1.01 rows=797 width=11) Order by: a, b Cluster Filter: (a > 100)
V1.3版本的执行计划相较于之前版本,利用表Clustering Keys的有序性直接做归并输出,整个执行可Pipeline起来,不用再担心数据量大的时候排序慢的问题。从执行计划对比中可以看到,V1.3版本生成的是Groupagg,相比Hashagg,处理复杂度更低,性能会更好。
-
-
-
针对Clustering Keys做Join的场景(Beta)
Hologres在V1.3版本新增了SortMergeJoin类型,以保证生成的执行计划能够利用Clustering Keys的有序性,减少计算量,从而提高性能。但需要注意:
-
当前该功能还处于Beta版本,默认不开启,需要在Query前添加如下参数开启。
-- 开启merge join set hg_experimental_enable_sort_merge_join=on; -
当表没有对Clustering Keys做过滤时,默认走的是SeqScan,而不是IndexScan(只有IndexScan才会利用Clustering Keys的有序属性)。
-
优化器并不保障总是生成基于Clustering Keys有序的执行,因为利用Clustering Keys有序性是有些代价的(文件内有序但内存中需要额外排序)。
示例如下。
-
V2.1版本起支持的语法:
DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys1; CREATE TABLE test_use_sort_info_of_clustering_keys1 ( a int, b int, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys1 SELECT i % 500, i % 100, i::text FROM generate_series(1, 10000) AS s(i); ANALYZE test_use_sort_info_of_clustering_keys1; DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys2; CREATE TABLE test_use_sort_info_of_clustering_keys2 ( a int, b int, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys2 SELECT i % 600, i % 200, i::text FROM generate_series(1, 10000) AS s(i); ANALYZE test_use_sort_info_of_clustering_keys2;所有版本支持的语法:
drop table if exists test_use_sort_info_of_clustering_keys1; begin; create table test_use_sort_info_of_clustering_keys1 ( a int, b int, c text ); call set_table_property('test_use_sort_info_of_clustering_keys1', 'distribution_key', 'a'); call set_table_property('test_use_sort_info_of_clustering_keys1', 'clustering_key', 'a,b'); commit; insert into test_use_sort_info_of_clustering_keys1 select i%500, i%100, i::text from generate_series(1, 10000) as s(i); analyze test_use_sort_info_of_clustering_keys1; drop table if exists test_use_sort_info_of_clustering_keys2; begin; create table test_use_sort_info_of_clustering_keys2 ( a int, b int, c text ); call set_table_property('test_use_sort_info_of_clustering_keys2', 'distribution_key', 'a'); call set_table_property('test_use_sort_info_of_clustering_keys2', 'clustering_key', 'a,b'); commit; insert into test_use_sort_info_of_clustering_keys2 select i%600, i%200, i::text from generate_series(1, 10000) as s(i); analyze test_use_sort_info_of_clustering_keys2; -
查询语句如下。
explain select * from test_use_sort_info_of_clustering_keys1 a join test_use_sort_info_of_clustering_keys2 b on a.a = b.a and a.b=b.b where a.a > 100 and b.a < 300; -
执行计划对比
-
V1.3之前版本(V1.1)的执行计划如下。
Gather (cost=0.00..3.09 rows=4762 width=24) -> Hash Join (cost=0.00..2.67 rows=4762 width=24) Hash Cond: ((test_use_sort_info_of_clustering_keys1.a = test_use_sort_info_of_clustering_keys2.a) AND (test_use_sort_info_of_clustering_keys1.b = test_use_sort_info_of_clustering_keys2.b)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3993 width=12) -> Decode (cost=0.00..1.14 rows=3993 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys1 (cost=0.00..1.01 rows=3993 width=12) Cluster Filter: ((a > 100) AND (a < 300)) -> Hash (cost=1.13..1.13 rows=3386 width=12) -> Exchange (Gather Exchange) (cost=0.00..1.13 rows=3386 width=12) -> Decode (cost=0.00..1.13 rows=3386 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys2 (cost=0.00..1.01 rows=3386 width=12) Cluster Filter: ((a > 100) AND (a < 300)) -
V1.3版本的执行计划如下。
Gather (cost=0.00..2.88 rows=4762 width=24) -> Merge Join (cost=0.00..2.46 rows=4762 width=24) Merge Cond: ((test_use_sort_info_of_clustering_keys2.a = test_use_sort_info_of_clustering_keys1.a) AND (test_use_sort_info_of_clustering_keys2.b = test_use_sort_info_of_clustering_keys1.b)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3386 width=12) Merge Key: test_use_sort_info_of_clustering_keys2.a, test_use_sort_info_of_clustering_keys2.b -> Decode (cost=0.00..1.14 rows=3386 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys2 (cost=0.00..1.01 rows=3386 width=12) Order by: test_use_sort_info_of_clustering_keys2.a, test_use_sort_info_of_clustering_keys2.b Cluster Filter: ((a > 100) AND (a < 300)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3993 width=12) Merge Key: test_use_sort_info_of_clustering_keys1.a, test_use_sort_info_of_clustering_keys1.b -> Decode (cost=0.00..1.14 rows=3993 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys1 (cost=0.00..1.01 rows=3993 width=12) Order by: test_use_sort_info_of_clustering_keys1.a, test_use_sort_info_of_clustering_keys1.b Cluster Filter: ((a > 100) AND (a < 300))
V1.3版本的执行计划相较于之前版本的执行计划,利用Clustering Index的有序性,在Shard内做归并排序后直接进行SortMergeJoin,让整个执行Pipeline起来;可规避数据量较大时,HashJoin需将Hash Side填充至内存而导致的OOM问题。
-
-
相关文档
关于Hologres内部表DDL语句的介绍详情,请参见: