
Range Clustering作为一种新的数据切分方式,提供了一个全局有序的数据分布,一是可以避免Hash Clustering可能造成的数据倾斜问题;二是在数据有序分布的前提下,创建两级索引(Index),支持对Clustering Key的区域查询以及多键的组合查询等场景。本文为您介绍如何在MaxCompute中使用Range Clustering。
背景信息
哈希聚簇(Hash Clustering)表有以下优点:
对于等值的列条件查询,可以利用Hash算法直接定位到对应的哈希桶(Bucket Pruning),如果桶内数据排序存储,还可以进一步利用索引定位,从而减少数据扫描量,提高查询效率。
如果对不同表某一列上做Join,其中一张表因为已经对其中一列做Hash分布,可以省掉Shuffle的步骤(称之为Shuffle Remove),进而节省计算资源。
关于Hash Clustering功能的详细介绍请参见Hash Clustering。
但是Hash Clustering也有一些局限性:
使用Hash算法分桶,有可能产生Data Skew的问题。和Join Skew一样,这是Hash算法本身固有的局限性,输入数据存在某些特定的数据分布时,可能造成倾斜,进而导致各个哈希桶之间数据量差异较大。因为Hash Clustering之后,并发处理单位往往是一个桶,如果哈希桶数据量不一致,往往容易造成长尾现象。
Bucket Pruning只支持等值查询。因为使用哈希分桶方法,对于区间查询比如使用某列值大于0这样的条件,无法在哈希桶级别定位,只能把查询下发到所有桶内进行。
对于多个Cluster Key的组合查询,只有所有Cluster Key都出现并且都为等值条件,才能达到优化效果。
比如,对于下表只有查询条件包含
C1=x AND C2=y才可以优化。单独的C1=x或者C2=y查询条件皆无法利用Hash Clustering特性加速。这是因为对于组合键的情况做了Combine Hash,要求查询的时候一定要成对出现,否则无法定位哈希桶,也无法做Bucket Pruning。CREATE TABLE T2 (C1 int, C2 int, C3 string) CLUSTERED BY (C1, C2) SORTED by (C1, C2) INTO 1024 BUCKETS;
针对这些局限性,MaxCompute推出了新的Clustering方法,即Range Clustering。
功能简介
Range Clustering在对Cluster Key全排序的基础上,将其值域空间切分成若干个不连续值域(Disjointed Range),每个Range作为一个Bucket,并且满足如下条件:
相同数值存在于同一个Bucket里面。
每个Bucket包含数值个数尽可能接近。
举一个简单的例子:假设有表T,定义如下。
CREATE TABLE T (C1 int)
RANGE CLUSTERED BY (C1)
SORTED BY (c1)
INTO 3 BUCKETS;同时,C1列取值为{ 1, 8, -3, 2, 4, 1, 1, 3, 8, 20, -8, 9 }。
在Range Clustering之后,得到如下3个Bucket:
Bucket 0 : { -8, -3, 1, 1, 1 }
Bucket 1 : { 2, 3, 4 }
Bucket 2 : { 8, 8, 9, 20 }
每个Bucket所代表的Range可能是不连续的(Disjointed)。例如Bucket 1的Range是
[2, 4],而Bucket 2的Range是[8, 20],(4, 8)这个区间是没有数值的。Range切分的目标是让每个桶的大小尽量接近,而不是Range大小接近。在运算的时候,每个桶是一个并发的单位,桶的大小一致保证了数据没有长尾。但是由于数据在各个区间分布密度不一致,桶的大小一致并不代表Range大小一致。
Range的切分过程是MaxCompute自动完成的,不需要手动指定每一个Range。因为在大数据场景下手动指定Range不高效,往往也不现实。MaxCompute内部会自动对数据进行排序、采样,对各个区间的数据密度建立直方图,最后通过合并计算各个区间直方图,来实现最终理想的Range切分。
此外RANGE CLUSTERED BY可以和SORTED BY结合,从而保证了数据全局有序,在这个基础上,MaxCompute将自动创建两级索引:Global Index和File Index,用于快速定位和查找键值,如下图所示: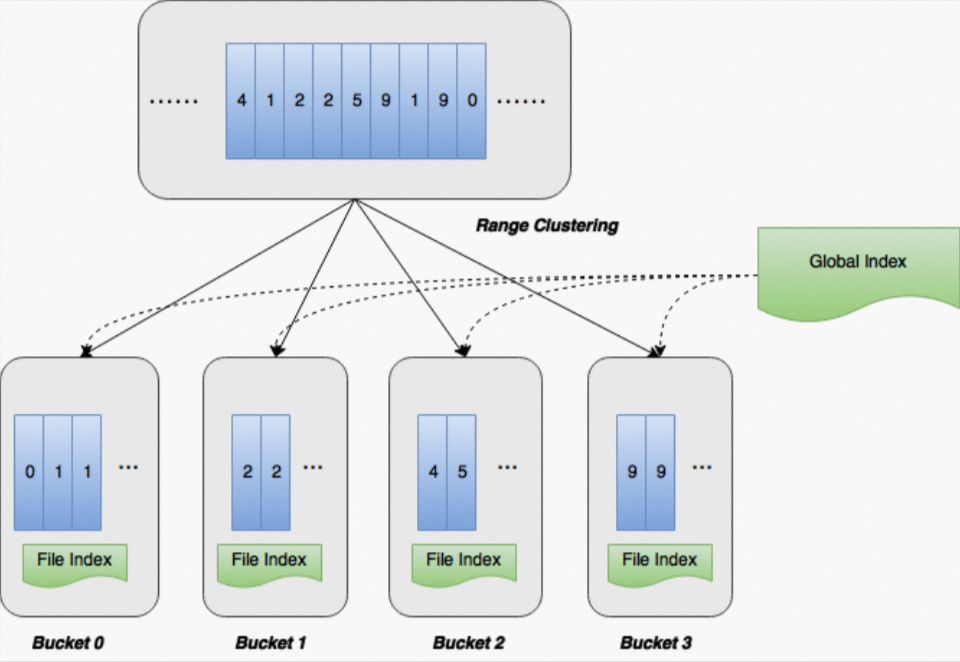
和Hash Clustering相比,Range Clustering优势如下:
支持区间查询。
假设有查询条件
c < 3,则可以根据Global Index快速排除掉Bucket 2和Bucket 3,从而只在Bucket 0和Bucket 1中查找。Hash Clustering只能对等值查询做Bucket Pruning。支持多个Cluster列的组合查找。
假设使用
RANGE CLUSTERED BY (c1, c2, c3) SORTED BY (c1, c2, c3),那么在Range切分和数据存储都是按照c1、c2、c3排序,这就可以允许做更复杂的组合查询,比如c1 = 100 AND c2 > 0或者c1 = 100 AND c2 = 50 AND c3 < 5,这个也是Hash Clustering无法支持的。重要在多键组合查询时,条件需要按顺序列出排序键,并且只有最后一个Key允许使用区间条件。
Range Clustering提供了一个高效的全局ORDER BY实现。
在没有Range Clustering之前为了保证全局有序,MaxCompute只能通过一个Instance进行ORDER BY排序,效率很低。使用Range Clustering之后做Range切分之后,各个Range可以并发分别排序,最后在组合到一起,效率极大提高。
使用说明
Range Clustering的语法和Hash Clustering类似,比较大的区别是RANGE关键字以及Bucket数目对于Range Clustering是可以省略的。
创建Range Clustering表
您可以使用以下语句创建Range Clustering表。您需要指定Range Cluster Key、Bucket数目(可选)。Sort是可选项,但在大多数情况下,建议和Range Cluster Key一致,以便取得最佳的优化效果。
命令语法
CREATE TABLE [IF NOT EXISTS] <table_name> [(<col_name> data_type [comment <col_comment>], ...)] [comment table_comment] [PARTITIONED BY (<col_name> data_type [comment <col_comment>], ...)] [RANGE CLUSTERED BY (<col_name> [, <col_name>, ...]) [SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] [INTO <number_of_buckets> BUCKETS]] [AS select_statement]使用示例。
非分区表。
CREATE TABLE T1 (a string, b string, c int) RANGE CLUSTERED BY (c) SORTED by (c) INTO 1024 BUCKETS;分区表。
CREATE TABLE T1 (a string, b string, c int) PARTITIONED BY (dt int) RANGE CLUSTERED BY (c) SORTED by (c) INTO 1024 BUCKETS;
属性说明
RANGE CLUSTERED BY
指定Range Cluster Key,MaxCompute将对指定一列或者多列进行排序和采样,并根据指定Bucket数目,切分到尽可能理想的若干个Range里面。为避免数据倾斜、避免热点,取得较好的并行执行效果,Clustered By列适宜选择取值范围大、重复键值少的列。此外为了达到优化目的,也应该考虑选取常用的Aggregation Key或者Filter Key。
SORTED BY
指定在Bucket内字段的排序方式,建议Sorted By和Clustered By一致,以取得较好的性能。此外当Sorted By子句指定之后,MaxCompute将自动生成索引(Global Index和File Index),并且在查询的时候利用索引来加速执行。
INTO number_of_buckets BUCKETS
和Hash Clustering不一样,对于Range Clustering
INTO ... BUCKETS是可选项。如果不指定Bucket数目,MaxCompute将根据数据大小自动决定分片数目。在大多数情况下,建议指定Bucket数目,以便根据实际情况来做优化选择。对于Bucket数目的选择,和Hash Clustering类似,建议保持在每个Bucket 512MB ~ 1GB这样的数据量,对于特别大的表,Bucket 数目可以大些,但建议不要超过4000。
更改表的Hash Clustering属性
对于分区表支持通过ALTER TABLE语句,来增加或者去除Range Clustering属性。
命令语句
--更改表为Range Clustering表 ALTER TABLE <table_name> [RANGE CLUSTERED BY (<col_name> [, <col_name>, ...]) [SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] [INTO <number_of_buckets> BUCKETS]; --更改Range Clustering表为非Range Clustering表 ALTER TABLE <table_name> NOT CLUSTERED;注意事项
ALTER TABLE语句改变聚集属性,只对于分区表有效,非分区表一旦聚集属性建立就无法改变。
ALTER TABLE语句只会影响分区表的新建分区(包括insert overwrite生成的),新分区将按新的聚集属性存储,老的数据分区保持不变。
由于ALTER TABLE语句只影响新分区,所以该语句不可以再指定PARTITION。
ALTER TABLE语句适用于存量表,在增加了新的聚簇属性之后,新的分区将做Range Clustering存储。
表属性显式验证
在创建Range Clustering Table之后,可以通过如下命令来查看表属性,Range Clustering属性将显示在Extended Info里面。
DESC EXTENDED <table_name>;返回结果示例如下图所示。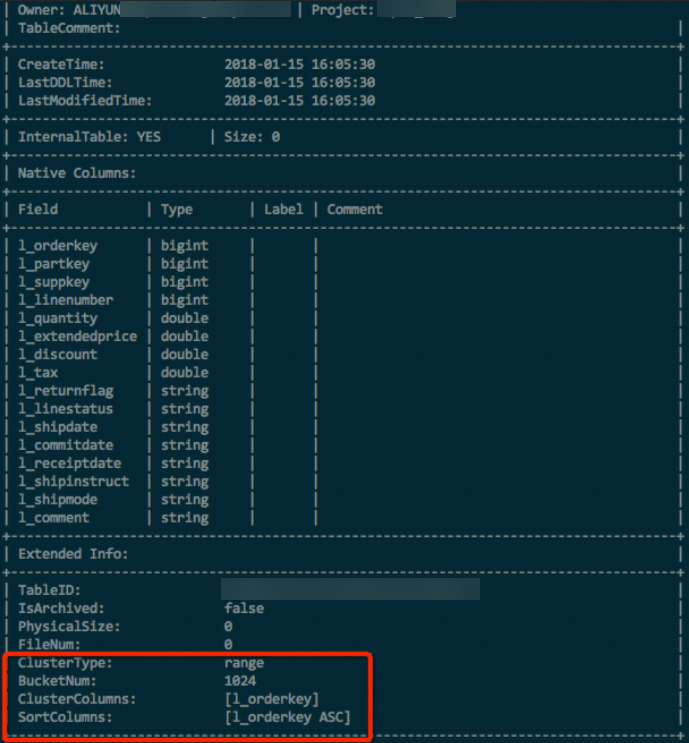 对于分区表,除了使用以上命令查看表属性之后,还可以通过以下命令查看分区的属性。
对于分区表,除了使用以上命令查看表属性之后,还可以通过以下命令查看分区的属性。
DESC EXTENDED <table_name> partition(<pt_spec>);返回结果示例如下图所示。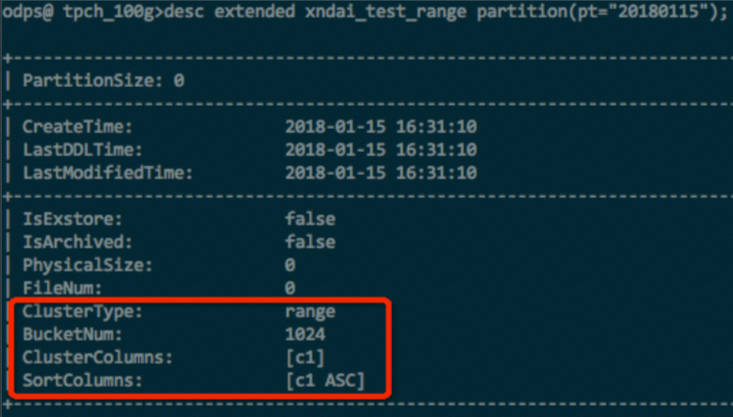
使用场景
过滤查询优化
Range Clustering保证了数据全局有序,在这个基础上MaxCompute自动创建了Global Index和File Index,利用数据的存储特性,可以加快数据过滤(Filter)的效率。不仅仅可以优化等值查询,也可以优化区间查询。
例如对于一个简单的查询条件id < 3,先在优化器里面将查询条件抽取出来,并转化成值域空间(-∞, 3)。这个时候就可以利用Global Index做Bucket Pruning,把不在这个区间的Bucket 2和Bucket 3都去掉。最后再利用每个Bucket文件自带的Index,快速在文件内部定位,这个过程称之为谓词下推(Predicate Pushdown),示意图如下: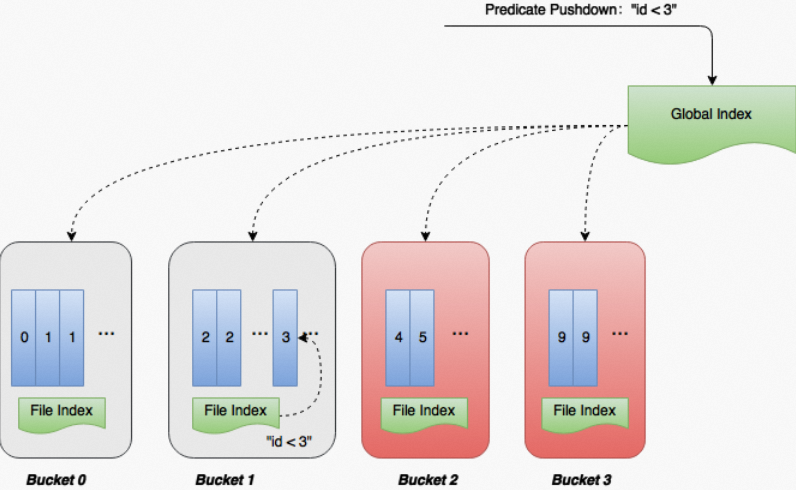 TPC-H Q6在100GB数据集上使用Range Clustering后进行查询,查询语句如下。Q6是一个区间过滤的基础上再做的聚合操作,使用Range Clustering可以利用两级Index快速定位数据,无论是执行时间、CPU使用率和内存使用率的性能都有数倍的提升。
TPC-H Q6在100GB数据集上使用Range Clustering后进行查询,查询语句如下。Q6是一个区间过滤的基础上再做的聚合操作,使用Range Clustering可以利用两级Index快速定位数据,无论是执行时间、CPU使用率和内存使用率的性能都有数倍的提升。
select sum(l_extendedprice * l_discount) as revenue
from tpch_lineitem l
where l_shipdate >= '1994-01-01'
and l_shipdate < '1995-01-01'
and l_discount >= 0.05
and l_discount <= 0.07
and l_quantity < 24;多键组合查询
为了比较好的理解多键组合查询场景,使用如下命令将mf_tab 表改造成Range Clustering表。
ALTER TABLE mf_project.mf_tab
RANGE CLUSTERED BY (project_name, name)
SORTED BY (project_name, name)
INTO 1024 BUCKETS;这样做的好处是,既可以在Project级别上做一些聚合查询,示例命令如下:
SELECT COUNT(*)
from mf_project.mf_tab
WHERE project_name="xxxdw"
AND ds="20180115"
AND type="TABLE";又可以用组合键来精确定位某张表,示例命令如下:
SELECT count(*)
from mf_project.mf_tab
WHERE project_name="xxxdw"
AND name="adm_ctu_cle_kba_midun_trade_dd"
AND type="TABLE";甚至可以用于区域查询,比如统计以adm开头的表:
SELECT count(*)
from mf_project.mf_tab
WHERE project_name="xxxdw"
AND name>="adm"
AND name < "adn"
AND type="TABLE";以上查询都可以充分利用Range Clustering全局排序的特性,下推查询谓词,减少表扫描的IO量以及过滤计算的CPU和内存消耗。
对于多个Range Cluster Key组合的场景,是有一定要求的。对于RANGE CLUSTERED BY k0, k1, ..., kn,如果查询用到了km,则k0, k1, ..., km-1都必须在查询条件中且都是等值条件,才能取得索引加速最佳效果。
假设表T的Range Cluster Key为k1, k2 ,则有:
查询条件为
k1 < 5:可以Index加速。k1 = 10 AND k2 = 20:可以Index加速。k1 = 10 AND k2 < 0:可以Index加速。k2 < 0:不可以Index加速,k1缺失。k1 < 0 AND k2 > 0:可以Index加速部分,Index只过滤k1<0的条件,k2>0条件需要扫描。
Group By优化
对于Range Clustering,由于数据全局有序,并且相同的键值在做Range切分的时候,放到了同一个Bucket里面,Aggregation计算就可以利用这个数据的物理属性,节省掉Shuffle的步骤。
例如,对于如下对表T数据的Group By操作可以直接在一个Mapper Stage里面完成。
CREATE TABLE T (department int, team string, employee string)
RANGE CLUSTERED BY (department, team)
SORTED BY (c1, c2)
INTO 1024 BUCKETS;
SELECT COUNT(*) from T GROUP BY department, team;如果要取得最佳的GROUP BY优化效果,GROUP BY Key需要和RANGE CLUSTERED BY Key一致。
Aggregate 优化
表foo结构如下。
create table foo(a bigint, b bigint, c bigint)
range clustered by (a,b)
sorted by(a,b) into 3 buckets;假设表foo的Range为:
Bucket 0: [1,1 : 3,3]
Bucket 1: [5,5 : 7,7]
Bucket 2: [8,8 : 9,9]以上Bucket Range可以理解为:Bucket N: [lower bound values : upper bound values]。如果按照a来聚合的话,每个Bucket的范围就变成:
Bucket 0: [1 : 3]
Bucket 1: [5 : 7]
Bucket 2: [8 : 9]可以直接产生类似按照a、b聚合的执行计划(Plan),启动3个Instance对每个Bucket聚合,然后输出结果后结束。
但是对于a的值横跨多个Bucket的情况下,就会得到错误的结果,示例如下。
Bucket 0: [1,1 : 3,3]
Bucket 1: [3,5 : 7,7]
Bucket 2: [7,8 : 9,9]列a有两个值3和7,分别横跨两个Bucket,只有把拥有相同的a值的tuple放到同一个Instance里面去进行聚合才能得到正确的结果。也就是像下面按照红色虚线重新切分Bucket,指定每个Instance读取的数据的范围才行: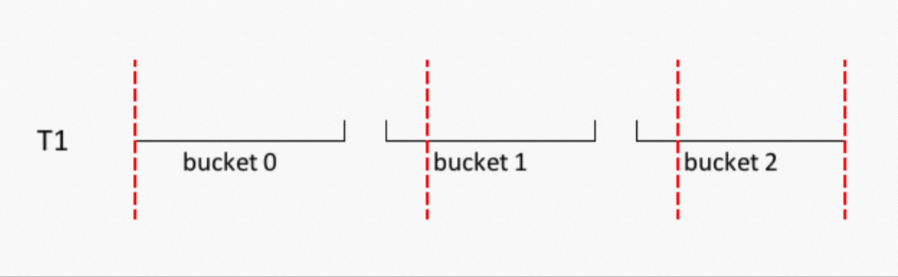 但是该从哪个地方切分, 这时候就需要直方图的帮助。对于Range Clustering表,在Clustering Key和Sort Key相同的情况下,当往Range Clustering表插入数据的时候,每个Bucket对应的Worker会每10000行采样一个tuple,取其Clustering Keys的值,并保存到直方图中,最后每个Bucket的直方图会存到Clustermeta文件中。 这种直方图被称为等高直方图(equi-depth histogram)。
但是该从哪个地方切分, 这时候就需要直方图的帮助。对于Range Clustering表,在Clustering Key和Sort Key相同的情况下,当往Range Clustering表插入数据的时候,每个Bucket对应的Worker会每10000行采样一个tuple,取其Clustering Keys的值,并保存到直方图中,最后每个Bucket的直方图会存到Clustermeta文件中。 这种直方图被称为等高直方图(equi-depth histogram)。
目前仅在Clustering Key和Sort Key一样的情况下才会采样。
有了每个Bucket的直方图就可以为每个Worker重新切分Bucket。切分原则如下:
拥有相同Grouping Key的tuple必须被划分到同一个Bucket中。
每个Bucket中的数据尽量均匀的切分。
有了每个新的Bucket的起始值,每个Worker就可以读取正确的数据范围,并返回正确的结果。
使用TPC-H数据集中1TB的partsupp表来测试性能提升如何。首先使用如下命令将partsupp表改造为Range Clustering表:
CREATE TABLE partsupp ( PS_PARTKEY BIGINT NOT NULL,
PS_SUPPKEY BIGINT NOT NULL,
PS_AVAILQTY BIGINT NOT NULL,
PS_SUPPLYCOST DECIMAL(15,2) NOT NULL,
PS_COMMENT VARCHAR(199) NOT NULL)
RANGE CLUSTERED BY(PS_PARTKEY, PS_SUPPKEY)
SORTED BY(PS_PARTKEY, PS_SUPPKEY) INTO 128 BUCKETS;使用下面的Query进行测试:
SELECT ps_partkey, count(*) c FROM partsupp GROUP BY ps_partkey;使用如下命令关闭优化:
set odps.optimizer.enable.range.partial.repartitioning=false;结果示例:

使用如下命令打开优化:
set odps.optimizer.enable.range.partial.repartitioning=true;结果示例:
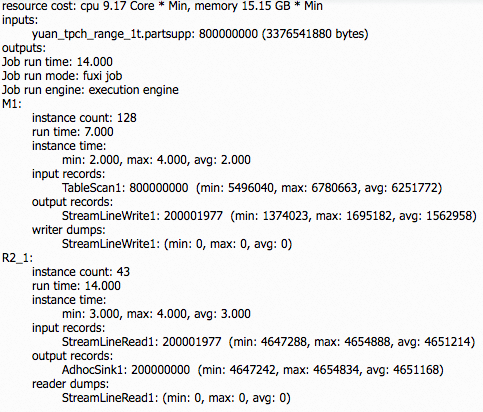

由上图可以看出,针对此查询优化后速度提升了57%、CPU的使用率降低了52%、内存的使用降低了71%。当然针对不同数据量、不同的查询,可能得到性能提升的程度也不同。
Range表的Join优化
假设有两个表:
create table t1(a bigint, b bigint, c bigint, d bigint) range clustered by(a,b,c) sorted by(a,b,c) into 3 buckets; create table t2(a bigint, b bigint, c bigint, d bigint) range clustered by(a,b,c) sorted by(a,b,c) into 3 buckets;然后分别往两个表里插入不同的数据。
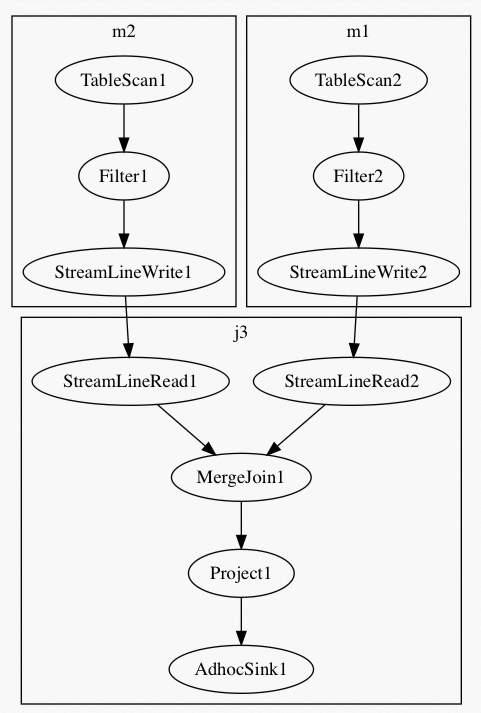
对于Hash Clustering表,只要两个相Join的Hash Clustering表拥有相同数目的Bucket,那么两个表对应的Bucket里的数据就可以Join。与Hash Clustering表不同的是:即使相Join的两个Range Clustering表拥有相同数目的Bucket,也不能简单地直接根据Bucket Id来进行Join,因为每个Range Bucket所存储的数据范围(Boundary)很有可能会不同。两个Range Clustering表相Join始终会产生如下图所示有Shuffle的查询计划:
对此需要进行改进,通过对两个Range表的Boundary进行对齐来重新划分每个表的Bucket,即重新定义每个Instance要读取的数据范围。假设有两个表:
create table t1(a bigint, b bigint, c bigint, d bigint) range clustered by(a,b,c) sorted by(a,b,c) into 5 buckets; create table t2(a bigint, b bigint, c bigint, d bigint) range clustered by(a,b,c) sorted by(a,b,c) into 3 buckets;当插入一定量的数据后得到如下的Bucket Boundary:
对于如下Query:SELECT * FROM t1 JOIN t2 ON t1.a=t2.a AND t1.b=t2.b AND t1.c=t2.c;优化器会取拥有较多Bucket数目的Boundary来和另外一个表的Boundary进行对齐,然后得到每个表的新的Boundary,即如下图所示:
这样就产生了没有Shuffle的查询计划:对于下面的查询:SELECT * FROM t1 JOIN t2 ON t1.a=t2.a AND t1.b=t2.b;优化器会先对每个表按照a、b两个列重新划分Bucket,然后再将切分好的Bucket进行对齐再次切分,从而得到每个表的每个Bucket所需要读取的数据范围,进而产生像上图那样没有Shuffle的查询计划。
性能测试
表改造
用TPC-H Q2在1TB的数据表进行测试,对part表和partsupp表进行Range Clustering的改造,其他表保持不变:
CREATE TABLE PARTSUPP ( PS_PARTKEY BIGINT NOT NULL, PS_SUPPKEY BIGINT NOT NULL, PS_AVAILQTY BIGINT NOT NULL, PS_SUPPLYCOST DECIMAL(15,2) NOT NULL, PS_COMMENT VARCHAR(199) NOT NULL) RANGE CLUSTERED BY(PS_PARTKEY, PS_SUPPKEY) SORTED BY(PS_PARTKEY, PS_SUPPKEY) INTO 128 BUCKETS; CREATE TABLE PART ( P_PARTKEY BIGINT NOT NULL, P_NAME VARCHAR(55) NOT NULL, P_MFGR CHAR(25) NOT NULL, P_BRAND CHAR(10) NOT NULL, P_TYPE VARCHAR(25) NOT NULL, P_SIZE BIGINT NOT NULL, P_CONTAINER CHAR(10) NOT NULL, P_RETAILPRICE DECIMAL(15,2) NOT NULL, P_COMMENT VARCHAR(23) NOT NULL) RANGE CLUSTERED BY(P_PARTKEY) SORTED BY(P_PARTKEY) INTO 64 BUCKETS;TPC-H Q2的内容如下:
select s_acctbal, s_name, n_name, p_partkey, p_mfgr, s_address, s_phone, s_comment from part, supplier, partsupp, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and p_size = 15 and p_type like '%BRASS' and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'EUROPE' and ps_supplycost = (select min(ps_supplycost) from partsupp, supplier, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'EUROPE') order by s_acctbal desc, n_name, s_name, p_partkey limit 100;测试结果
使用如下命令关闭优化:
set odps.optimizer.enable.range.partial.repartitioning=false;结果示例:
使用如下命令打开优化:
set odps.optimizer.enable.range.partial.repartitioning=true;结果示例:
对比可以看出,优化后不但有两个Stage的减少,速度提升了约21.4%,而且CPU的消耗减少了约35.4%,内存的使用也减少了约54.6%。
 对此需要进行改进,通过对两个Range表的Boundary进行对齐来重新划分每个表的Bucket,即重新定义每个Instance要读取的数据范围。
对此需要进行改进,通过对两个Range表的Boundary进行对齐来重新划分每个表的Bucket,即重新定义每个Instance要读取的数据范围。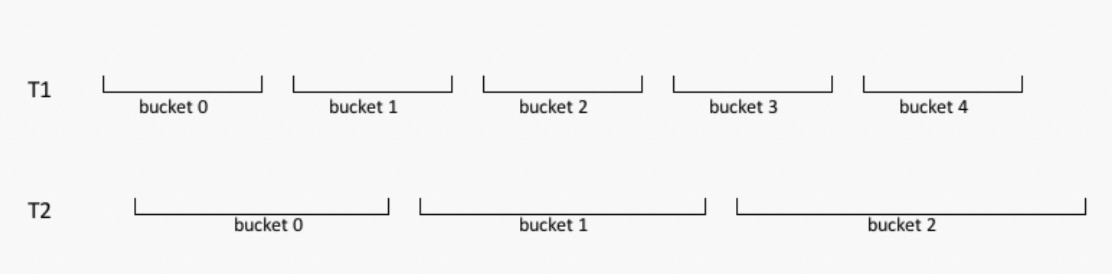 对于如下Query:
对于如下Query: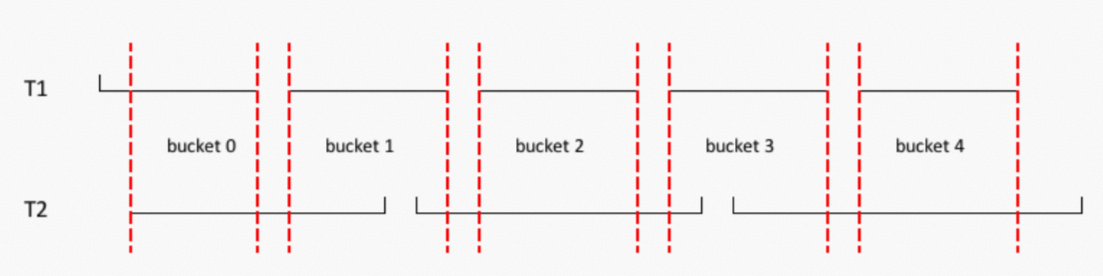 这样就产生了没有Shuffle的查询计划:
这样就产生了没有Shuffle的查询计划: 对于下面的查询:
对于下面的查询:
全局排序加速
Range Clustering还可以用来做全局排序加速。在普通的ORDER BY场景,为保证全局有序,所有的排序数据合并到一个单独的Instance运行,这就无法发挥并行处理的优势。利用Range Clustering的paritition步骤,可以实现并发多路全排序。首先对数据取样并划分Range,然后对各个Range做并发排序,最后得到的就是全局有序的结果。
需要注意的是,排序结束以后,修改表或分区存储时仍然包括了多个文件(Buckets),在消费数据时,如果要保证全局有序,需要按Bucket顺序读取文件。
Range Clustering的全排序加速缺省关闭,如果需要打开,请使用以下Flag。
set odps.optimizer.distribute.ordering.enable=true;局限性和注意事项
Range Clustering和Hash Clustering比较,有优势的同时在某些方面也有一些局限:
Range Clustering在数据生成的代价比Hash Clustering要高。Hash Clustering只是做一个简单的Hash操作和排序,但是对于Range而言,需要做数据采样,排序,以及Histogram的合并等等,总体的代价(运行时间、CPU使用率、Memory Cost)比Hash Clustering高。所以在Hash Clustering可以解决的问题,就不需要用Range Clustering。
不支持DYNAMIC PARTITION,以及INSERT INTO场景。
对Join的支持方面只支持Inner Join、Left/Right Outer Join、Semi Join,不支持Anti Join和Full Outer Join。
Range Clustering表的Range Cluster Key必须和Sort Key相同,比如对于表foo中
range clustered by (a,b) sorted by (a,b),本文中的优化可以生效;但是对于表bar中range clustered by(a,b) sorted by (b,a),本文中的优化就不会生效。Join Key和Group Key必须为Range Clustering key的全部或者前缀。比如
range clustered by(a,b,c) sorted by(a,b,c),对于Join Key和Group Key为a、a,b或a,b,c的查询才能应用本文中的优化;对于Join Key或Group Key为b或a,c的查询就无法应用本文中的优化。对于分区表,如果读取的Range Clustering表涉及两个或两个以上的分区无法应用本文中的优化。目前本文中的优化只针对单个分区的分区表和非分区表有效。