
本文介绍AI RAG。
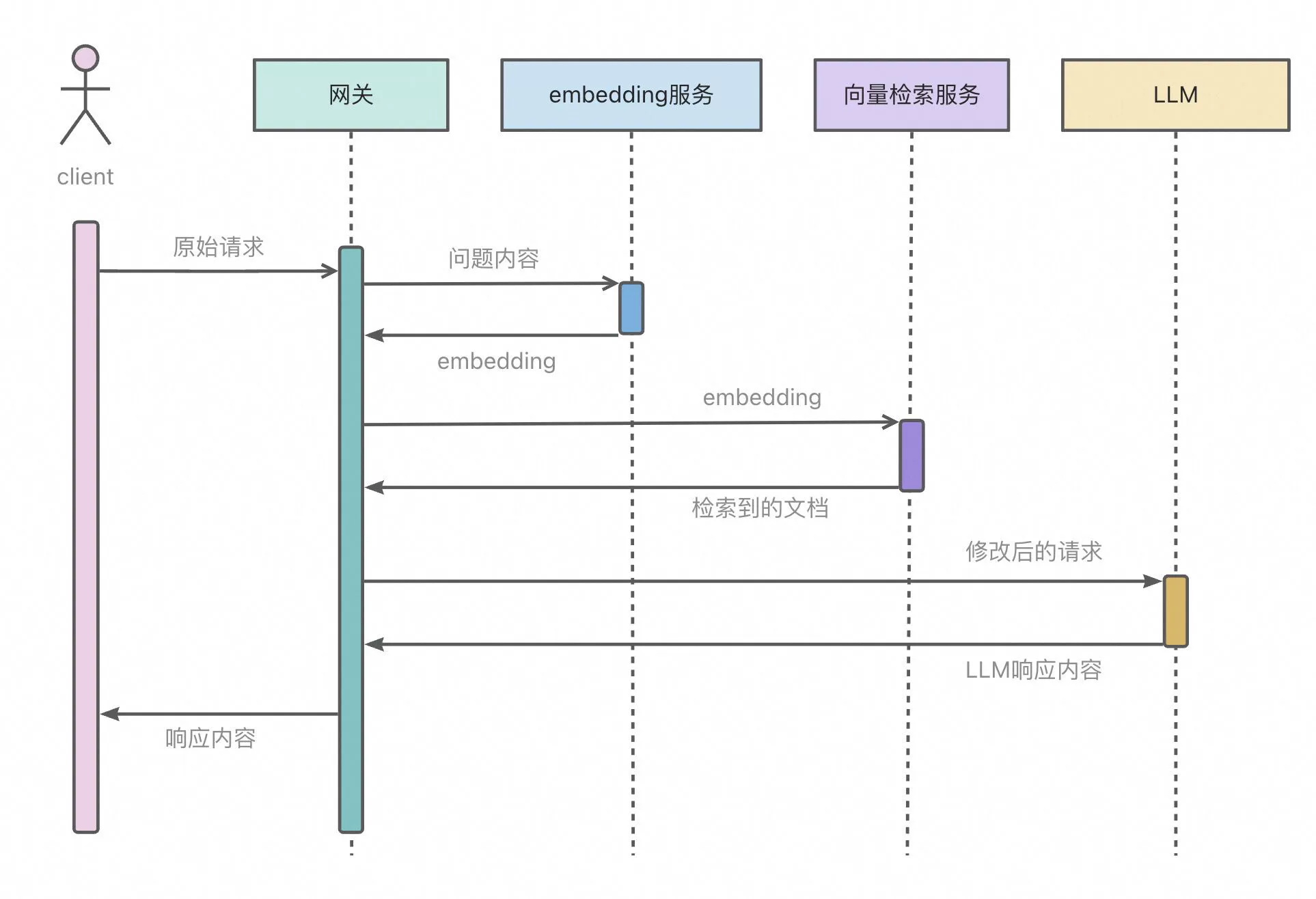
通过对接阿里云向量检索服务DashVector实现LLM-RAG,流程如图所示:
运行属性
插件执行阶段:默认阶段,插件执行优先级:400。
配置说明
|
名称 |
数据类型 |
填写要求 |
默认值 |
描述 |
|
|
string |
必填 |
- |
用于在访问千问服务时进行认证的令牌。 |
|
|
string |
必填 |
- |
千问服务名。 |
|
|
int |
必填 |
- |
千问服务端口。 |
|
|
string |
必填 |
- |
访问千问服务时域名。 |
|
|
string |
必填 |
- |
用于在访问阿里云向量检索服务DashVector时进行认证的令牌。 |
|
|
string |
必填 |
- |
阿里云向量检索服务DashVector名。 |
|
|
int |
必填 |
- |
阿里云向量检索服务DashVector端口。 |
|
|
string |
必填 |
- |
访问阿里云向量检索服务DashVector的域名。 |
|
|
int |
必填 |
- |
阿里云向量检索时获取向量数。 |
|
|
float |
必填 |
- |
向量距离阈值,高于该阈值的文档会被过滤掉。 |
|
|
string |
必填 |
- |
阿里云向量检索存储文档的字段名。 |
插件开启后,在使用链路追踪功能时,会在span的attribute中添加rag检索到的文档id信息,供排查问题使用。
示例
dashscope:
apiKey: xxxxxxxxxxxxxxx
serviceFQDN: dashscope
servicePort: 443
serviceHost: dashscope.aliyuncs.com
dashvector:
apiKey: xxxxxxxxxxxxxxxxxxxx
serviceFQDN: dashvector
servicePort: 443
serviceHost: vrs-cn-xxxxxxxxxxxxxxx.dashvector.cn-hangzhou.aliyuncs.com
collection: xxxxxxxxxxxxxxx
topk: 1
threshold: 0.4
field: rawCEC-Corpus数据集包含332篇突发事件的新闻报道的语料和标注数据,提取其原始的新闻稿文本,将其向量化后添加到阿里云向量检索服务DashVector。文本向量化的教程可以参考基于向量检索服务DashVector与TextEmbedding实现语义搜索。
以下为使用RAG进行增强的例子,原始请求为:海南追尾事故,发生在哪里?原因是什么?人员伤亡情况如何?
-
未经过RAG插件处理LLM返回的结果为:
抱歉,作为AI模型,我无法实时获取和更新新闻事件的具体信息,包括地点、原因、人员伤亡等细节。对于此类具体事件,建议您查阅最新的新闻报道或官方通报以获取准确信息。您可以访问主流媒体网站、使用新闻应用或者关注相关政府部门的公告来获取这类动态资讯。
-
经过RAG插件处理后LLM返回的结果为:
海南追尾事故发生在海文高速公路文昌至海口方向37公里处。关于事故的具体原因,交警部门当时仍在进一步调查中,所以根据提供的信息无法确定事故的确切原因。人员伤亡情况是1人死亡(司机当场死亡),另有8人受伤(包括2名儿童和6名成人),所有受伤人员都被解救并送往医院进行治疗。