
如果您的业务场景涉及图像分类,则可以通过图像分类训练(torch)组件构建图像分类模型,从而进行模型推理。本文为您介绍图像分类训练(torch)组件的配置方法及使用示例。
前提条件
已开通OSS并完成授权,详情请参见开通OSS服务和云产品依赖与授权:Designer。
功能限制
仅Designer提供该算法组件。
支持的计算引擎为DLC。
算法简介
图像分类训练(torch)组件提供了CNN和Transformer两大类主流模型,支持ResNet、ResNeXt、HRNet、ViT、SwinT、MobileNetv2算法,并提供了基于ImageNet预训练的模型,方便您进行模型调整。
图像分类训练(torch)组件位于组件库视觉算法文件夹下的离线训练模型子文件夹。
可视化配置组件
输入桩
输入桩(从左到右)
限制数据类型
建议上游组件
是否必选
训练数据标注文件
OSS
否
验证数据标注文件
OSS
否
组件参数
页签
参数
是否必选
描述
默认值
字段设置
训练模型类型
是
训练模型使用的算法类型,仅支持Classification。
Classification
保存训练输出的oss目录
是
存储训练模型的OSS目录,比如:
oss://examplebucket/yunji.cjy/designer_test。无
训练数据标注结果文件路径
否
如果您没有通过输入桩配置该组件的训练数据标注结果文件,则需要配置该参数。
说明如果您同时通过输入桩和该参数配置了该组件的训练数据标注结果文件,则优先使用输入桩配置的数据。
训练数据标注结果文件所在的OSS路径,比如:
oss://examplebucket/yunji.cjy/data/imagenet/meta/train_labeled.txt。其中train_labeled.txt文件每行的存储格式为:
绝对路径/图片名称.jpg label_id。重要图片存放路径和label_id之间使用空格分隔。
重要组件提供ClsSourceImageList和ClsSourceItag格式的训练数据输入。通过PAI提供的智能标注模块进行数据标注的数据文件可以直接输入进行训练。
验证数据标注结果文件路径
否
如果您没有通过输入桩配置该组件的验证数据标注结果文件,则需要配置该参数。
说明如果您同时通过输入桩和该参数配置了该组件的验证数据标注结果文件,则优先使用输入桩配置的数据。
验证数据标注结果文件所在的OSS路径,比如:
oss://examplebucket/yunji.cjy/data/imagenet/meta/val_labeled.txt。其中val_labeled.txt文件每行的存储格式为:
绝对路径/图片名称.jpg label_id。重要图片存放路径和label_id之间使用空格分隔。
说明组件提供ClsSourceImageList和ClsSourceItag格式的训练数据输入。通过PAI提供的智能标注模块进行数据标注的数据文件可以直接输入进行训练。
无
类别名称列表文件
是
类别名称列表文件用于指定图像分类后的类别列表,支持直接写入类别名称,或设置为存有类别名称的txt文件路径。
直接写入类别名称:配置格式为
[name1,name2,……]多个类别名称间使用逗号(,)分隔,例如[0, 1, 2]或[person, dog, cat]。配置为txt文件路径:可将类别名称列表写入txt文件后,将txt文件上传至同地域的OSS,此处即可配置为OSS中的文件路径。
此场景下,txt文件中的类别名称可以使用逗号(,)或换行符号(\n)分隔。例如
0, 1, 2,或0, \n 1, \n 2\n。如果此参数为空,类别名称将默认为
str(0)到str(num_classes-1)。其中num_classes为类别数目。即如果图像分类后的类别数为3,则默认的类别名称列表为
0,1,2。
无
数据源格式
是
输入数据的格式类型,支持ClsSourceImageList和ClsSourceItag。
ClsSourceItag
预训练模型oss路径
否
如果您有自己的预训练模型,则将该参数配置为预训练模型的OSS路径。如果没有配置该参数,则使用PAI提供的默认预训练模型。
无
参数设置
图像分类模型使用的backbone
是
选择使用的骨干模型,支持以下几种主流模型:
resnet
resnext
hrnet
vit
swint
mobilenetv2
inceptionv4
resnet
图像类别数目
是
数据中类别标签的数目。
无
图片resize大小
是
图片大小调整成固定的高和宽(默认长宽相等)。
224
优化方法
是
模型训练的优化方法,支持以下取值:
SGD
Adam
SGD
初始学习率
是
初始学习率大小。
0.05
学习率调整策略
是
使用学习率调整策略来控制学习率。支持的学习率调整策略为step:人工指定各阶段的学习率。
step
lr step
是
与学习率调整策略配合使用,多个step用半角逗号(,)连接。当epoch数量达到某个阶段,学习率默认衰减0.1倍。
比如:初始学习率为0.1,总的训练迭代epoch轮数为20,lr step为5,10。则epoch轮数为1~5时,学习率为0.1;epoch轮数为5~10时,学习率为0.01;epoch轮数为10~20时,学习率为0.001。
[30,60,90]
训练batch_size
是
训练的批大小,即模型训练过程中,每次迭代(每一步)训练的样本数量。
2
评估batch_size
是
评估(验证)的批大小,即模型验证过程中,每次迭代(每一步)加载的样本数量。
2
总的训练迭代epoch轮数
是
所有样本训练完成一轮表示一个epoch。总的epoch轮数表示所有样本共训练多少轮。
1
保存checkpoint的频率
否
保存模型文件的频率。取值为1表示1个epoch训练完成后保存一次模型。
1
导出的模型类型
是
导出模型的格式,提供两种导出格式。
raw
onnx
raw
执行调优
每个GPU读取训练数据的进程数
否
每个GPU读取训练数据的进程数量。
4
开启半精度
否
选中该参数,表示使用FP16半精度进行模型训练,用来降低内存占用。
无
单机或分布式DLC
是
组件运行的引擎,您可以结合实际情况选择。系统支持以下计算引擎:
单机DLC
分布式DLC
单机DLC
worker个数
否
当运行引擎为分布式DLC时,需要配置该参数。
训练过程中,并发的进程(worker)数量。
1
cpu机型选择
否
当运行引擎为分布式DLC时,需要配置该参数。
选择运行的CPU规格。
16vCPU+64GB Mem-ecs.g6.4xlarge
gpu机型选择
是
选择运行的GPU规格。
8vCPU+60GB Mem+1xp100-ecs.gn5-c8g1.2xlarge
输出桩
输出桩
数据类型
下游组件
输出模型
OSS路径。该路径是您在字段设置页签的保存训练输出的oss目录参数配置的OSS路径,训练生成的模型存储在该路径下。
使用示例
您可以使用图像分类训练(torch)组件构建如下工作流。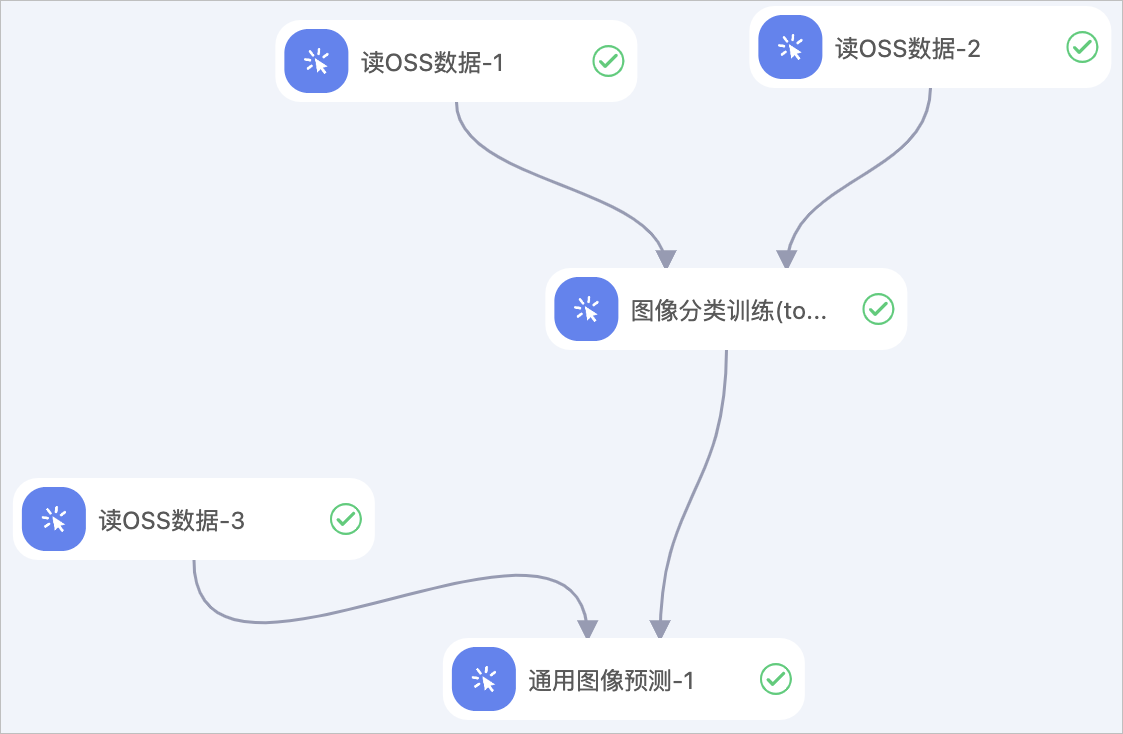 本示例中,您需要按照以下流程配置组件:
本示例中,您需要按照以下流程配置组件:
准备数据,通过PAI提供的智能标注模块进行数据标注,详情请参见智能标注(ITAG)。
使用读OSS数据-1和读OSS数据-2组件分别读取训练数据标注结果文件和验证数据标注结果文件,即配置读OSS数据组件的OSS数据路径参数为存放训练数据标注结果文件和验证数据标注结果文件的OSS路径。
重要数据源格式处选择ClsSourceItag格式
将以上2个读OSS数据组件接入图像分类训练(torch)组件,并配置具体参数,详情请参见上文的可视化配置组件。
使用读OSS数据-3组件读取预测数据文件,即配置读OSS数据组件的OSS数据路径参数为存放预测数据文件的OSS路径。
通过通用图像预测组件进行离线推理,需要配置以下关键参数,详情请参见通用图像预测。
模型类型:选择torch_classifier。
模型OSS路径:图像分类训练(torch)组件输出模型的OSS路径。