
词频统计算法是一种基本的文本分析方法,通过计算每个单词在文本中出现的次数,将文本数据转换为数值特征。这一过程生成的结果常用于特征提取阶段,为后续的自然语言处理任务,如文本分类、聚类和信息检索等提供基础数据。
算法说明
词频是指某个词在特定语料中出现的次数,用于衡量词在文本中的重要性。为统计词频,首先需对文档进行分词,即将文档内容(docContent)拆分为单独的词语。接下来,对于每个文档,按照输入顺序输出其文档ID(docId)及相关词汇数据。最后,计算每个词在指定文档中的出现次数。这一过程不仅有助于揭示文本的词汇结构,还为后续的文本分析任务提供基础数据支持,如文本分类、主题建模和信息检索等。
输入/输出
输入桩
输出桩
组件配置
方式一:可视化方式
在Designer工作流页面添加词频统计组件,并在界面右侧配置相关参数:
参数类型 | 参数 | 描述 |
字段设置 | 选择文档ID列 | 选择文档ID列(docId)。 |
选择文档内容列 | 选择文档内容列(docContent)。该列中的文本内容将被用于词频统计分析,即对其进行分词并计算每个词的出现频率。 | |
执行调优 | 核心数 | 节点数量。 |
每个核心的内存 | 单个节点内存大小,单位为MB。 |
方式二:PAI命令方式
使用PAI命令配置词频统计组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见场景4:在SQL脚本组件中执行PAI命令。
pai -name doc_word_stat
-project algo_public
-DinputTableName=tdl_doc_test_split_word
-DdocId=docid
-DdocContent=content
-DoutputTableNameMulti=doc_test_stat_multi
-DoutputTableNameTriple=doc_test_stat_triple
-DinputTablePartitions="region=cctv_news"
-Dlifecycle=7参数 | 是否必选 | 默认值 | 描述 |
inputTableName | 是 | 无 | 输入表名称。 |
docId | 是 | 无 | 标识文档ID的列名,仅可指定一列。 |
docContent | 是 | 无 | 标识文档内容的列名,仅可指定一列。 |
outputTableNameMulti | 是 | 无 | 输出保序词语表名。用于存储分词后的结果,其中包含文档ID列(docId)及其对应文档内容(docContent)的分词数据。各个词语按照它们在文档中出现的顺序逐一输出。 |
outputTableNameTriple | 否 | 无 | 输出词频统计表名。用于输出文档ID列(docId)及其对应的文档内容(docContent)。 |
inputTablePartitions | 否 | 选择所有分区 | 输入表中,参与训练的分区。系统支持以下格式:
说明 指定多个分区时,分区之间使用英文逗号(,)分隔,例如name1=value1,value2。 |
lifecycle | 否 | -1 | 输出表生命周期,正整数。 |
组件输出
输出端1:三元组输出
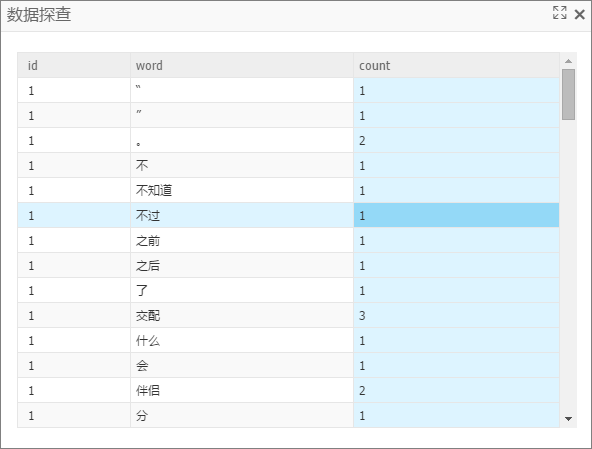
输出端2:多行输出
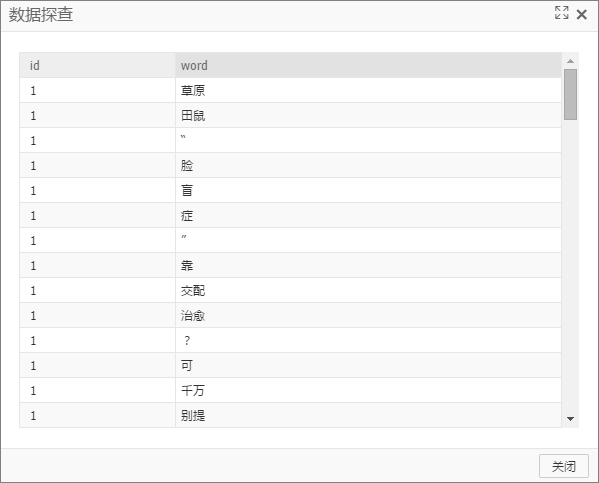
本端口输出表按词语在文档中出现的顺序依次输出,没有统计词语的出现次数,因此同一文档中某个词语可能出现多条记录。该输出表格式主要用于兼容Word2Vec组件。