TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于评估一个词在一个文档中的重要性的统计方法。它通过结合词频(TF)和反文档频率(IDF)来衡量词的权重,从而提高文本检索和信息挖掘的准确性。
TF词频(Term Frequency)是指某一个给定的词语在该文件中出现的次数。IDF反文档频率(Inverse Document Frequency)是指如果包含词条的文档越少,IDF越大,则说明词条的类别区分能力越强。
TF-IDF是一种统计方法,用于评估字词或文件的重要程度。例如:
在文件集中的字词会随着出现次数的增加呈正比增加趋势。
在语料库中的文件会随着出现频率的增加呈反比下降趋势。
TF-IDF组件基于词频统计算法的输出结果(而不是基于原始文档),计算各词语对于各文章的TF-IDF值。
使用说明
由于TF-IDF组件是基于词频统计算法的输出结果,因此TF-IDF组件需要接入到词频统计组件的下游。
组件配置
方式一:可视化方式
在Designer工作流页面添加TF-IDF组件,并在界面右侧配置相关参数:
参数类型 | 参数 | 描述 |
字段设置 | 选择文档ID列 | 您可以直接选择词频统计组件输出的文档ID列(id列)或自行将原始文档处理为相应格式,详情请参见词频统计示例部分的输出介绍。 |
选择单词列 | 您可以直接选择词频统计组件输出的单词列(word列)或自行将原始文档处理为相应格式,详情请参见词频统计示例部分的输出介绍。 | |
选择单词计数列 | 您可以直接选择词频统计组件输出的单词计数列(count列)或自行将原始文档处理为相应格式,详情请参见词频统计示例部分的输出介绍。 | |
执行调优 | 计算核心数 | 节点个数,默认自动计算。 |
每个核心内存 | 单个节点内存大小,单位为MB。 |
方式二:PAI命令方式
使用PAI命令配置TF-IDF组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
PAI -name tfidf
-project algo_public
-DinputTableName=rgdoc_split_triple_out
-DdocIdCol=id
-DwordCol=word
-DcountCol=count
-DoutputTableName=rg_tfidf_out;参数 | 是否必选 | 默认值 | 描述 |
inputTableName | 是 | 无 | 输入表名称。 |
inputTablePartitions | 否 | 输入表的所有分区 | 输入表中,参与训练的分区。 格式为 |
docIdCol | 是 | 无 | 标识文章ID的列名,仅可指定一列。 |
wordCol | 是 | 无 | Word列名,仅可指定一列。 |
countCol | 是 | 无 | Count列名,仅可指定一列。 |
outputTableName | 是 | 无 | 输出表名称。 |
lifecycle | 否 | 无 | 输出表生命周期。正整数。单位:天 |
coreNum | 否 | 自动计算 | 核心数,与memSizePerCore同时设置才生效。 |
memSizePerCore | 否 | 自动计算 | 内存数,与coreNum同时设置才生效。 |
示例
以TF-IDF组件实例中的输出表作为TF-IDF组件的输入表,对应的参数设置如下:
选择文档ID列: id
选择单词列:word
选择单词计数列:count
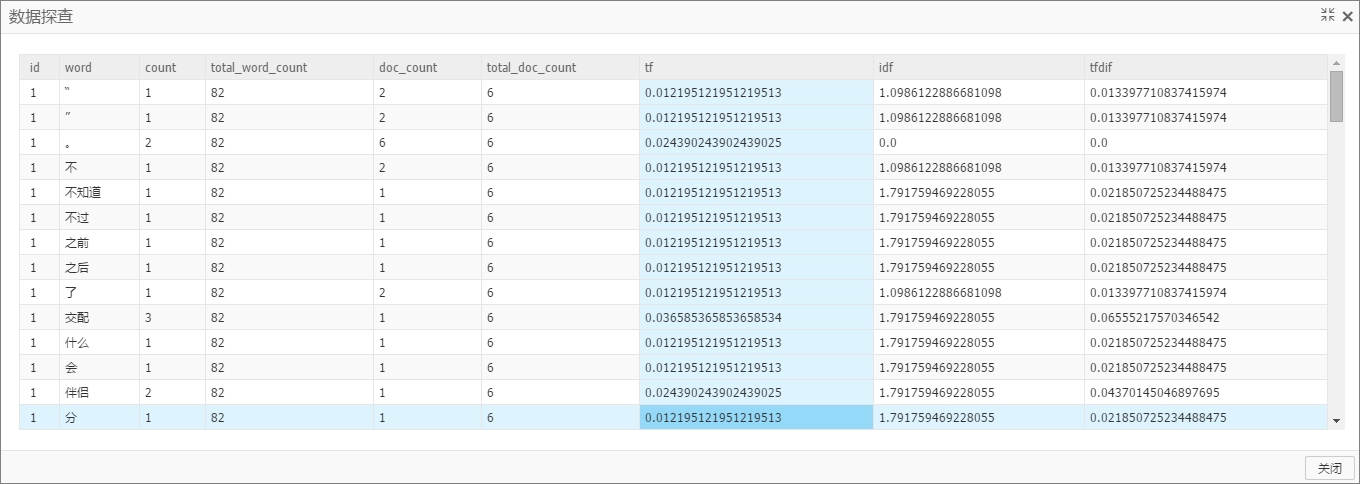
输出表有9列:docid、word、word_count(当前word在当前doc中出现次数)、total_word_count(当前doc中总word数)、doc_count(当前word的总doc数)、total_doc_count(全部doc数)、tf、idf和tfidf。