
本文介绍如何免费体验PolarDB PostgreSQL版列存索引功能。
背景
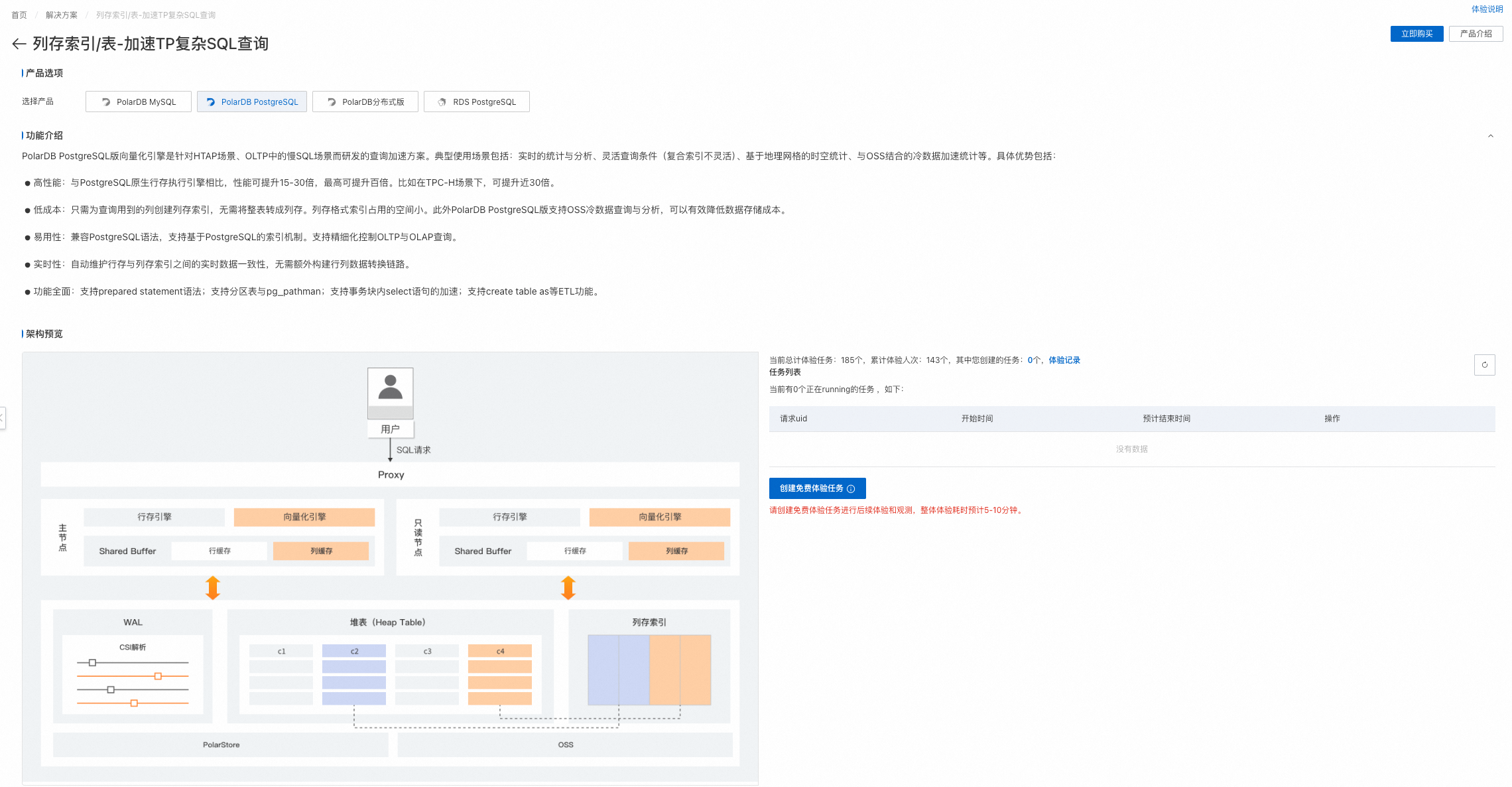
PolarDB列存索引是针对HTAP场景、OLTP中的慢SQL场景而研发的查询加速方案。典型使用场景包括:实时的统计与分析、灵活查询条件(复合索引不灵活)、基于地理网格的时空统计、与OSS结合的冷数据加速统计等。具体优势包括:
高性能:与PostgreSQL原生行存执行引擎相比,性能可提升15-30倍,最高可提升百倍。比如在TPC-H场景下,可提升近60倍。
低成本:只需为查询用到的列创建列存索引,无需将整表转成列存。列存格式索引占用的空间小。此外PolarDB PostgreSQL版支持OSS冷数据查询与分析,可以有效降低数据存储成本。
易用性:兼容PostgreSQL语法,支持基于PostgreSQL的索引机制。支持精细化控制OLTP与OLAP查询。
实时性:自动维护行存与列存之间的实时数据一致性,无需额外构建行列数据转换链路。
功能全面:
支持
Prepared Statement语法。支持分区表与
pg_pathman。支持事务块内
SELECT语句的加速。支持
CREATE TABLE AS等ETL功能。
阿里云提供了数据库解决方案功能体验馆,提供真实免费的PolarDB集群环境和开箱即用的测试方法,您可以在线快捷体验列存索引带来的提升效果。
影响
本功能体验不涉及生产环境的部署,因此不会影响业务。
费用
本次体验中,由于体验涉及到的资源不归属于您,因此不会产生任何费用,您可以放心体验。
体验内容
体验环境
在本免费体验中,阿里云提供了预置环境供您操作体验,预置环境的详情如下:
集群:提供了一个PolarDB PostgreSQL版集群。具体如下:
内核版本: 14.13.27.0
产品版本:企业版
系列:集群版独享规格
集群规格:集群包含1个主节点和1个只读节点,规格都为2核8 GB
存储类型: PSL5
测试数据集:集群中预置了标准测试集TPCH 10G的数据集。
观测指标
CPU占用率:集群中主节点、只读节点和只读列存节点的平均CPU使用率。
查询耗时:执行特定SQL所耗费的时间。单位:秒。
操作步骤
前往瑶池解决方案体验馆,免费体验列存索引/表-加速TP复杂SQL查询。
在产品选项中选择PolarDB PostgreSQL。
单击页面下方的创建免费体验任务按钮。
在确认创建查询加速体验任务对话框中,单击确定。
稍等片刻后,可以看到您创建的体验任务。
单击查看详情,进入实时查询体验页面。
使用行存引擎和列存引擎分别进行单表统计和多表JOIN两个场景的SQL语句查询。
说明请根据页面按钮提示,手动单击按钮执行每一步操作。若在倒计时结束时没有手动单击按钮,则会自动执行对应操作。
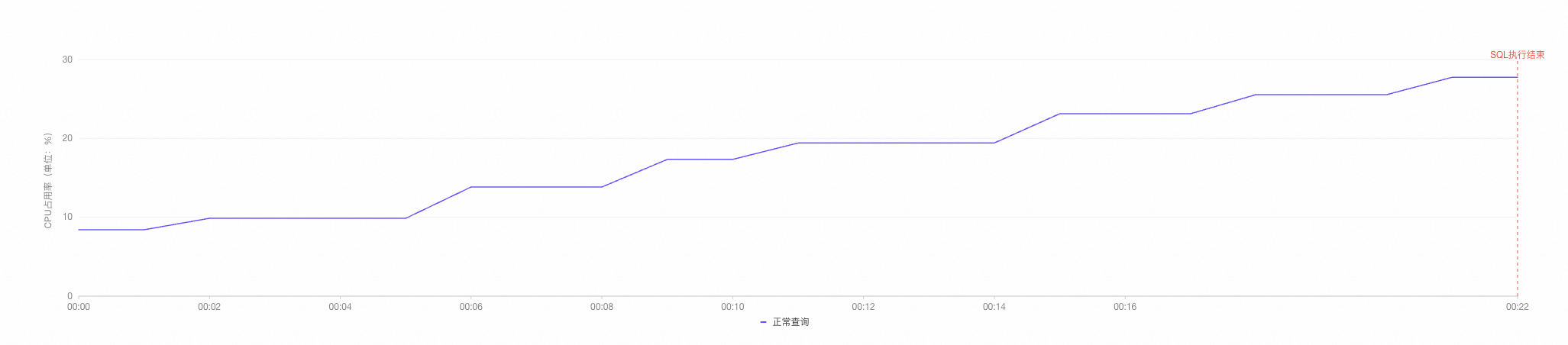
整个体验过程中,您可以在下方的趋势图中观测CPU占用率。
单击开始任务。
单击选择数据库,系统会自动执行如下命令,切换至目标数据库。
\c mydb首先进行单表统计场景查询。
首先进行单表统计的普通查询,单击关闭向量化引擎,系统会自动执行如下命令。
set polar_csi.enable_query to off;单击查看SQL执行计划,系统会自动执行如下命令,查看如下SQL的执行计划。
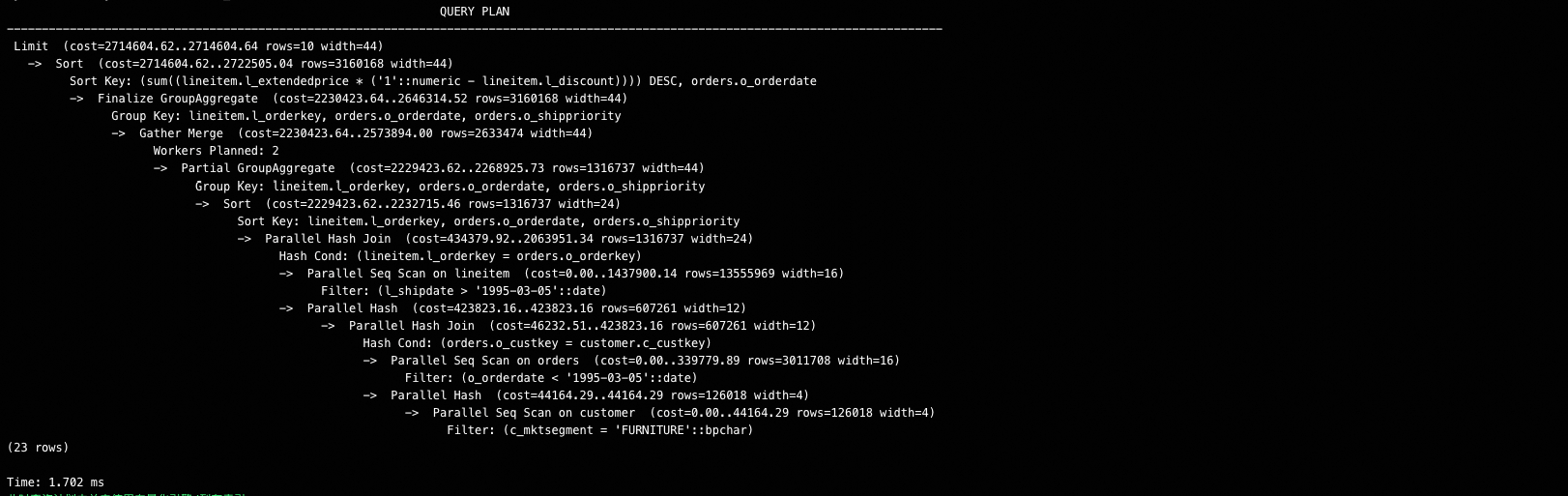
explain select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from lineitem where l_shipdate <= date '1998-12-01' - '60 day'::interval group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus;此时查询计划中并未使用列存索引,返回结果如下:

单击执行SQL,系统会自动执行以下SQL语句:
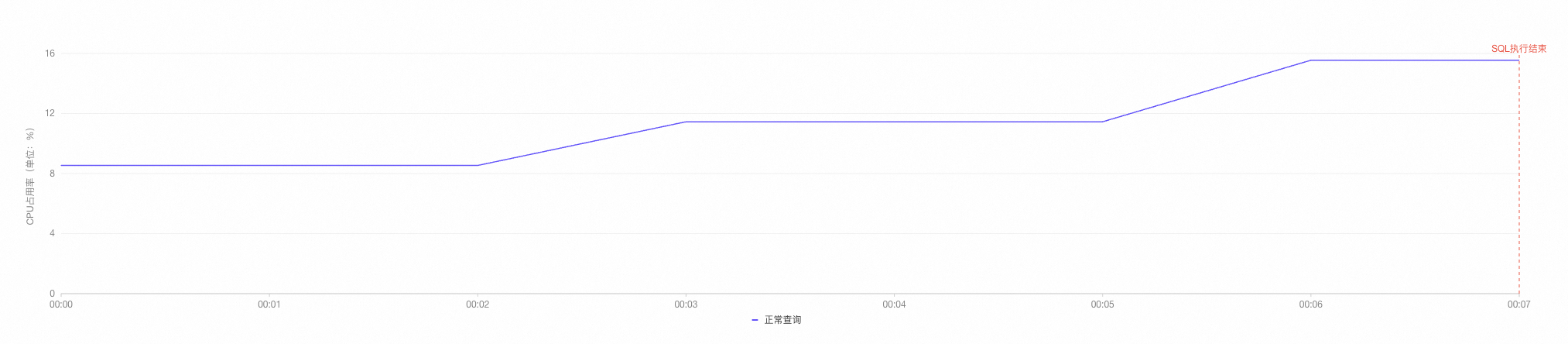
select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from lineitem where l_shipdate <= date '1998-12-01' - '60 day'::interval group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus;返回结果如下,执行时间为21.034秒,且可以观察到CPU占有率显著升高。

然后进行单表统计的加速查询。单击开启向量化引擎,系统会自动执行如下命令。
set polar_csi.enable_query to on;单击查看SQL执行计划,系统会自动执行如下命令,查看如下SQL的执行计划。
explain select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from lineitem where l_shipdate <= date '1998-12-01' - '60 day'::interval group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus;此时查询计划使用列存索引,返回结果如下:

单击执行SQL,系统会自动执行以下SQL语句:
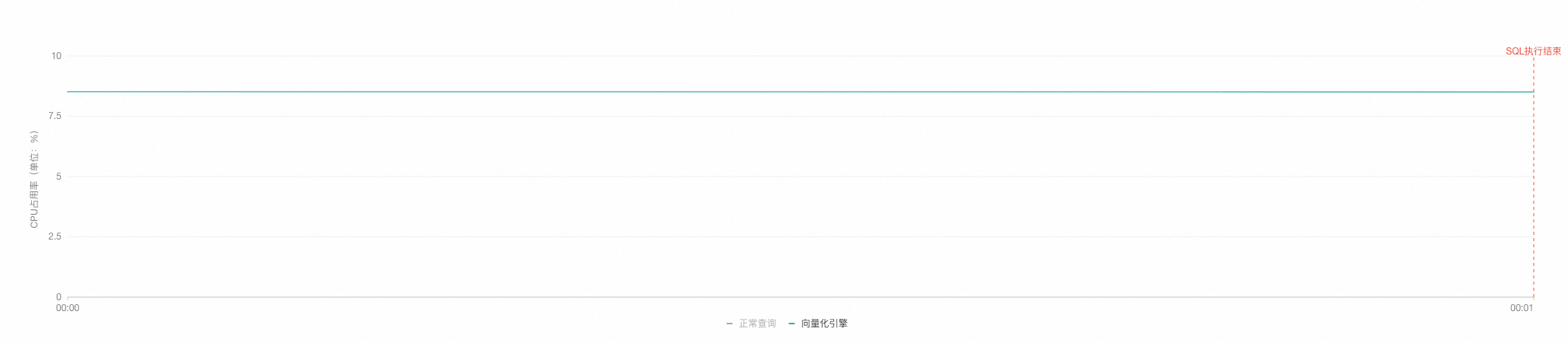
select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from lineitem where l_shipdate <= date '1998-12-01' - '60 day'::interval group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus;返回结果如下,执行时间为0.444秒,且可以观察到CPU占有率并无明显变化。
开始进行多表JOIN场景查询。
首先进行多表JOIN的普通查询,单击关闭向量化引擎,系统会自动执行如下命令。
set polar_csi.enable_query to off;单击查看SQL执行计划,系统会自动执行如下命令,查看如下SQL的执行计划。
explain select l_orderkey, sum(l_extendedprice * (1 - l_discount)) as revenue, o_orderdate, o_shippriority from customer,orders, lineitem where c_mktsegment = 'FURNITURE' and c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < date '1995-03-05' and l_shipdate > date '1995-03-05' group by l_orderkey, o_orderdate, o_shippriority order by revenue desc, o_orderdate limit 10;此时查询计划中并未使用列存索引,返回结果如下:
单击执行SQL,系统会自动执行以下SQL语句:
select l_orderkey, sum(l_extendedprice * (1 - l_discount)) as revenue, o_orderdate, o_shippriority from customer,orders, lineitem where c_mktsegment = 'FURNITURE' and c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < date '1995-03-05' and l_shipdate > date '1995-03-05' group by l_orderkey, o_orderdate, o_shippriority order by revenue desc, o_orderdate limit 10;返回结果如下,执行时间为6.789秒,且可以观察到CPU占有率显著升高。
说明观察CPU占有率时,您可单击图表下方的正常查询或向量化引擎以观察两者之间的CPU占有率对比。
然后进行单表统计的加速查询。单击开启向量化引擎,系统会自动执行如下命令。
set polar_csi.enable_query to on;单击查看SQL执行计划,系统会自动执行如下命令,查看如下SQL的执行计划。
explain select l_orderkey, sum(l_extendedprice * (1 - l_discount)) as revenue, o_orderdate, o_shippriority from customer,orders, lineitem where c_mktsegment = 'FURNITURE' and c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < date '1995-03-05' and l_shipdate > date '1995-03-05' group by l_orderkey, o_orderdate, o_shippriority order by revenue desc, o_orderdate limit 10;此时查询计划使用列存索引,返回结果如下:
单击执行SQL,系统会自动执行以下SQL语句:
select l_orderkey, sum(l_extendedprice * (1 - l_discount)) as revenue, o_orderdate, o_shippriority from customer,orders, lineitem where c_mktsegment = 'FURNITURE' and c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < date '1995-03-05' and l_shipdate > date '1995-03-05' group by l_orderkey, o_orderdate, o_shippriority order by revenue desc, o_orderdate limit 10;返回结果如下,执行时间为0.325秒,且可以观察到CPU占有率并无明显变化。
说明观察CPU占有率时,您可单击图表下方的正常查询或向量化引擎以观察两者之间的CPU占有率对比。
整个执行SQL的过程中,您可以在左侧趋势图中观测集群平均CPU使用率的变化情况。
说明由于实时监控数据可能存在延迟,为了确保展示完整的CPU变化情况,趋势图中会在SQL执行完后,自动延长一定监控时间(2~3秒)。
(可选)对于已创建的任务,您可以在列存索引-加速TP复杂SQL查询页面,单击体验记录,在任务列表中,单击全部任务或我的任务,查看体验结果及其详情。






结果分析
从本方案中您可以体验到PolarDB PostgreSQL列存索引的如下优势:
1. 使用方式简单,无需更改查询SQL即可实现加速效果。
2. 针对单表统计和多表Join场景,列存索引均有近30倍以上的性能提升。
列存索引对查询有明显加速作用
从执行时间上看,当开启列存索引后,复杂查询执行时间大幅缩短,单表统计查询从29.998秒缩短至0.496秒,多表JOIN查询从15.105秒缩短至0.354秒。
从执行计划上看,当开启列存索引后,执行计划包含CSI Executor,即表示使用列存索引功能。
列存索引对查询的处理更高效
由于实时监控数据可能存在延迟,为了确保展示完整的CPU变化情况,趋势图中会在SQL执行完后,自动延长一定监控时间(2~3秒)。
从执行时间和对应的CPU占用率可以看到,列存索引通过更低的CPU占用率实现了更快的查询。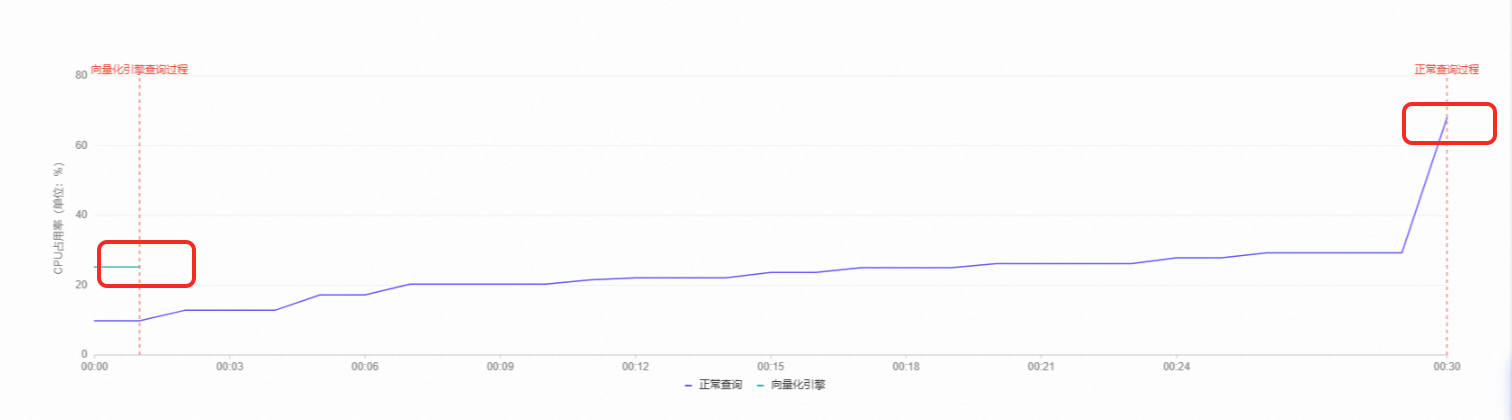
单表统计查询
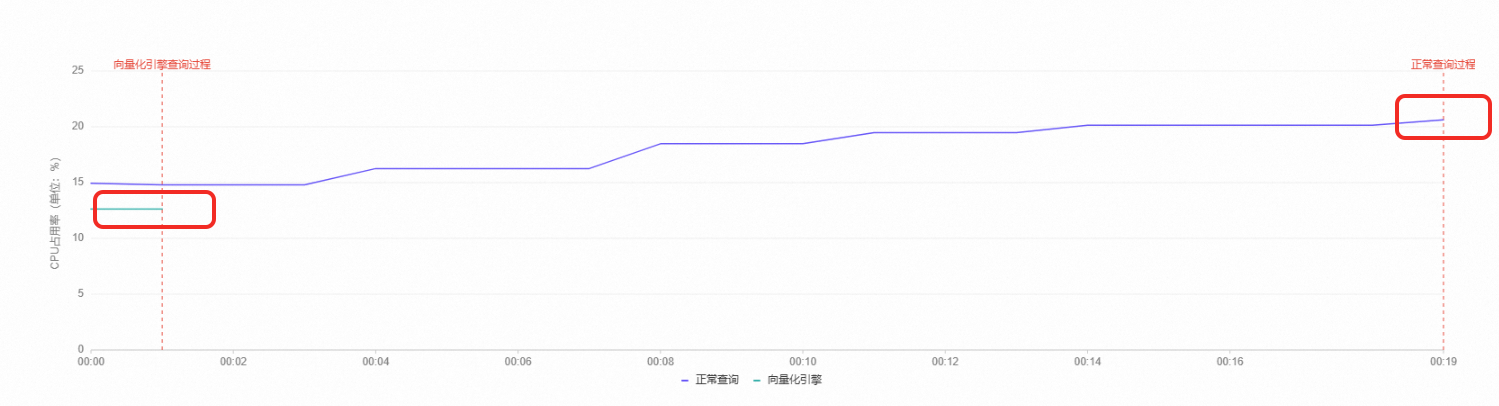
多表JOIN查询
相关内容
专家面对面
您可以加入官方钉钉群进行咨询,获取更多技术支持。钉钉群号:75850003226。