
TairVector是Tair自研的扩展数据结构,提供高性能、实时,集存储、检索于一体的向量数据库服务。
TairVector简介
TairVector采用多层Hash的数据结构,如下所示: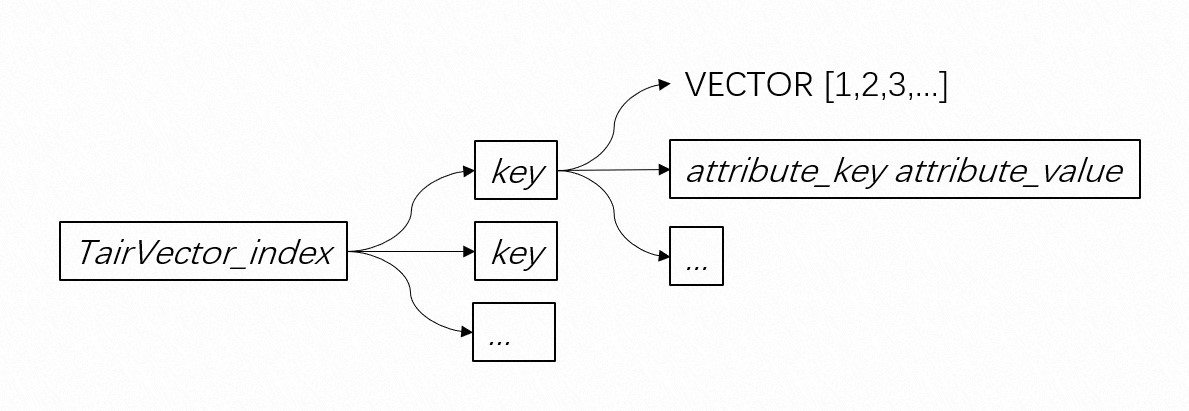 TairVector提供了HNSW(Hierarchical Navigable Small World)和暴力搜索(Flat Search)两种索引算法:
TairVector提供了HNSW(Hierarchical Navigable Small World)和暴力搜索(Flat Search)两种索引算法:
HNSW:以图结构构建向量检索的索引,支持异步空间回收,可以在保证高查询精度的同时,均衡实时更新的性能表现。
暴力搜索:具有100%查询精度,插入数据速度快,适用于小规模数据集。
同时,TairVector支持欧式距离(Euclidean distance)、向量内积(Internal product)、余弦距离(Cosine distance)和Jaccard距离(Jaccard distance)等多种距离函数。相对于传统的向量检索服务,TairVector的优势如下:
所有数据均在内存中,支持实时更新索引,具有更短的读写时延。
优化内存数据结构,占用空间更小。
开箱即用,以云服务的方式整体申请即可使用,整体架构简单高效,没有复杂组件依赖。
支持向量检索与全文检索组合的混合检索。
支持创建标量(标签属性等)倒排索引,并提供先标量后向量的KNN检索特性。
发布记录
2022年10月13日随Tair内存型(兼容Redis 6.0)首次发布TairVector。
2022年11月22日发布6.2.2.0版本,新增支持Jaccard距离函数、TVS.GETINDEX命令支持统计每个索引的内存占用(
index_data_size和attribute_data_size)。2022年12月26日发布6.2.3.0版本,支持集群代理模式,新增FLOAT16的向量数据类型,新增TVS.MINDEXKNNSEARCH、TVS.MINDEXMKNNSEARCH命令。
2023年07月04日发布6.2.8.2版本,支持余弦距离、支持HNSW索引垃圾自动回收。
2023年08月03日发布23.8.0.0版本,支持对Index中的key级别设置TTL(新增TVS.HEXPIREAT、TVS.HPEXPIREAT等命令),支持对指定Key列表进行向量近邻查询(新增TVS.GETDISTANCE命令),支持全文检索(更新TVS.CREATEINDEX、TVS.KNNSEARCH等命令),可以实现向量检索与全文检索组合的混合检索。
2024年06月06日发布24.5.1.0版本,新增TVS.KNNSEARCHFIELD、TVS.MINDEXKNNSEARCHFIELD命令,支持在近邻查询时返回标签属性信息。
2024年07月22日发布24.7.0.0版本,支持在稀疏向量中使用HNSW索引。
最佳实践
前提条件
实例的存储介质为内存型(兼容Redis 6.0及以上)。
内存型(兼容Redis 5.0)实例暂不支持升级至内存型(兼容Redis 6.0),如需使用请新建实例。
注意事项
操作对象为Tair实例中的TairVector数据。
TairVector数据结构的index_name、Key等暂不支持Redis的Hashtags特性。
TairVector暂不支持MOVE等特性。
若业务场景对数据持久化要求较高,建议开启半同步模式。
命令列表
表 1. TairVector命令
类型 | 命令 | 语法 | 说明 |
索引元数据操作 |
| 创建一个向量索引空间,同时指定构建索引和查询的具体算法,以及距离函数。该对象仅能通过 | |
| 查询指定的向量索引,获取该向量索引的元数据信息。 | ||
| 删除指定的向量索引及该索引内的所有数据。 | ||
| 扫描Tair实例中所有符合条件的向量索引。 | ||
向量数据操作 |
| 往向量索引中插入数据记录(key),若该记录已存在则更新并覆盖原记录。 | |
| 查询指定向量索引中的key对应的所有数据记录。 | ||
| 查询指定向量索引的key中对应的attribute_key所对应的数值。 | ||
| 在指定向量索引中,删除指定数据记录(key)。 | ||
| 在向量索引的数据记录(key)中,删除指定的attribute_key与其数值。 | ||
| 在指定向量索引中,扫描符合条件的数据记录(key)。 | ||
| 在指定向量索引中,将指定数据记录(key)的attribute_key的值增加num,num为一个整数。 | ||
| 在指定向量索引中,将指定数据记录(key)的attribute_key的值增加num,num为一个浮点数。 | ||
| 在指定向量索引中,为指定数据记录(key)设置绝对过期时间,精确到毫秒。 | ||
| 在指定向量索引中,为指定数据记录(key)设置相对过期时间,精确到毫秒。 | ||
| 在指定向量索引中,为指定数据记录(key)设置绝对过期时间,精确到秒。 | ||
| 在指定向量索引中,为指定数据记录(key)设置相对过期时间,精确到秒。 | ||
| 在指定向量索引中,查看指定数据记录(key)的剩余过期时间,精确到毫秒。 | ||
| 在指定向量索引中,查看指定数据记录(key)的剩余过期时间,精确到秒。 | ||
| 在指定向量索引中,查看指定数据记录(key)的绝对过期时间,精确到毫秒。 | ||
| 在指定向量索引中,查看指定数据记录(key)的绝对过期时间,精确到秒。 | ||
向量近邻查询 |
| 在指定向量索引中,对指定的向量(VECTOR)进行近邻查询,最多可返回topN条。 | |
| 在指定向量索引中,对指定的向量(VECTOR)进行近邻查询,检索逻辑与TVS.KNNSEARCH相同,额外支持返回标签属性。 | ||
| 在指定向量索引中,针对指定Key列表,进行向量(VECTOR)近邻查询。 | ||
| 在指定向量索引中,批量对多条向量(VECTOR)进行近邻查询。 | ||
| 在多个向量索引中,对指定的向量(VECTOR)进行近邻查询。 | ||
| 在多个向量索引中,对指定的向量(VECTOR)进行近邻查询,支持返回标签属性。 | ||
| 在多个向量索引中,批量对多条向量(VECTOR)进行近邻查询。 | ||
通用 |
| 使用原生Redis的DEL命令可以删除一条或多条TairVector数据。 |
本文的命令语法定义如下:
大写关键字:命令关键字。斜体:变量。[options]:可选参数,不在括号中的参数为必选。A|B:该组参数互斥,请进行二选一或多选一。...:前面的内容可重复。
TVS.CREATEINDEX
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 创建一个向量索引空间,同时指定构建索引和查询的具体算法,以及距离函数。该对象仅能通过 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例均为如下: |
TVS.GETINDEX
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 查询指定的向量索引,获取该向量索引的元数据信息。 |
选项 |
|
返回值 |
|
示例 | 请提前执行如下命令: 命令示例(以HNSW算法的向量索引为例): 返回示例: |
TVS.DELINDEX
类别 | 说明 |
语法 |
|
时间复杂度 | O(N),N为该向量索引中Key的数量。 |
命令描述 | 删除指定的向量索引及该索引内的所有数据。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.SCANINDEX
类别 | 说明 |
语法 |
|
时间复杂度 | O(N),N为Tair实例中向量索引数量。 |
命令描述 | 扫描Tair实例中所有符合条件的向量索引。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: 带Pattern的查询示例: 返回示例: |
TVS.HSET
类别 | 说明 |
语法 |
|
时间复杂度 | 若本次插入、更新数据无需创建或更新向量值,则时间复杂度为O(1);否则时间复杂度为O(log(N)),N为该向量索引中Key的数量。 |
命令描述 | 往向量索引中插入数据记录(key),若该记录已存在则更新并覆盖原记录。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HGETALL
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 查询指定向量索引中的key对应的所有数据记录。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HMGET
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 查询指定向量索引的key中对应的attribute_key所对应的数值。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.DEL
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,删除指定数据记录(key)。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HDEL
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在向量索引的数据记录(key)中,删除指定的attribute_key与其数值。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.SCAN
类别 | 说明 |
语法 |
|
时间复杂度 | O(N),N为该向量索引中Key的数量。 |
命令描述 | 在指定向量索引中,扫描符合条件的数据记录(key)。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HINCRBY
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,将指定数据记录(key)的attribute_key的值增加num,num为一个整数。 若指定的attribute_key不存在则自动新建并赋予该值,若该记录已存在则更新并覆盖原值。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HINCRBYFLOAT
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,将指定数据记录(key)的attribute_key的值增加num,num为一个浮点数。 若指定的attribute_key不存在则自动新建并赋予该值,若该记录已存在则更新并覆盖原值。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HPEXPIREAT
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,为指定数据记录(key)设置绝对过期时间,精确到毫秒。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HPEXPIRE
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,为指定数据记录(key)设置相对过期时间,精确到毫秒。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HEXPIREAT
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,为指定数据记录(key)设置绝对过期时间,精确到秒。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HEXPIRE
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,为指定数据记录(key)设置相对过期时间,精确到秒。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HPTTL
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,查看指定数据记录(key)的剩余过期时间,精确到毫秒。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HTTL
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,查看指定数据记录(key)的剩余过期时间,精确到秒。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HPEXPIRETIME
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,查看指定数据记录(key)的绝对过期时间,精确到毫秒。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.HEXPIRETIME
类别 | 说明 |
语法 |
|
时间复杂度 | O(1) |
命令描述 | 在指定向量索引中,查看指定数据记录(key)的绝对过期时间,精确到秒。 |
选项 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
TVS.KNNSEARCH
类别 | 说明 |
语法 |
|
时间复杂度 |
N为该向量索引中Key的数量。 |
命令描述 | 在指定向量索引中,对指定的向量(VECTOR)进行近邻查询,最多可返回topN条。 |
选项 |
|
返回值 |
|
示例 | 请提前执行如下命令: 命令示例1: 返回示例1: 命令示例2: 返回示例2: |
TVS.KNNSEARCHFIELD
类别 | 说明 |
语法 |
|
时间复杂度 |
N为该向量索引中Key的数量。 |
命令描述 | 在指定向量索引中,对指定的向量(VECTOR)进行近邻查询,检索逻辑与TVS.KNNSEARCH相同,额外支持返回标签属性。 |
选项 |
|
返回值 |
|
示例 | 请提前执行如下命令: 命令示例: 返回示例: |
TVS.GETDISTANCE
类别 | 说明 |
语法 |
|
时间复杂度 |
N为该向量索引中Key的数量。 |
命令描述 | 在指定向量索引中,针对指定Key列表,进行向量(VECTOR)近邻查询。 |
选项 |
|
返回值 |
|
示例 | 请提前执行如下命令: 命令示例: 返回示例: |
TVS.MKNNSEARCH
类别 | 说明 |
语法 |
|
时间复杂度 |
N为该向量索引中Key的数量。 |
命令描述 | 在指定向量索引中,批量对多条向量(VECTOR)进行近邻查询。 |
选项 |
|
返回值 |
|
示例 | 请提前执行如下命令: 命令示例: 返回示例: |
TVS.MINDEXKNNSEARCH
类别 | 说明 |
语法 |
|
时间复杂度 |
N为该向量索引中Key的数量。 |
命令描述 | 在多个向量索引中,对指定的向量(VECTOR)进行近邻查询。 |
选项 |
|
返回值 |
|
示例 | 请提前执行如下命令: 命令示例: 返回示例: |
TVS.MINDEXKNNSEARCHFIELD
类别 | 说明 |
语法 |
|
时间复杂度 |
N为该向量索引中Key的数量。 |
命令描述 | 在多个向量索引中,对指定的向量(VECTOR)进行近邻查询,支持返回标签属性。 |
选项 |
|
返回值 |
|
示例 | 请提前执行如下命令: 命令示例: 返回示例: |
TVS.MINDEXMKNNSEARCH
类别 | 说明 |
语法 |
|
时间复杂度 |
N为该向量索引中Key的数量。 |
命令描述 | 在多个向量索引中,批量对多条向量(VECTOR)进行近邻查询。 |
选项 |
|
返回值 |
|
示例 | 请提前执行如下命令: 命令示例: 返回示例: |