
在配置Logtail采集文本日志时,如果选择完整正则模式解析和采集日志,需要根据您的日志样例配置正则表达式。本文主要介绍在配置正则表达式过程中如何进行调试。
重要
本文档可能包含第三方产品信息,该信息仅供参考。阿里云对第三方产品的性能、可靠性以及操作可能带来的潜在影响,不做任何暗示或其他形式的承诺。
功能说明
在配置正则表达式时,您可以使用验证功能进行调试。
行首正则表达式:检查当前设置能否正确匹配出您期望的日志数量。
提取字段:检查各个字段中的值是否是您预期的值。
如果您希望进行更多的正则表达式调试功能,您可以利用如Regex101等工具,将控制台为您自动生成的正则表达式粘贴到这些工具上,然后填充您的实际日志样例进行检查、调试。
说明
完整正则模式提供自动生成正则表达式功能,但是在为多行日志生成正则表达式时,会存在问题,本文以Regex101为例进行正则表达式的调试和修改。
具体操作
访问Regex101,将日志服务根据日志样例自动生成的完整正则表达式拷贝到REGULAR EXPRESSION,如何生成正则表达式,请参见完整正则模式。
\[([^]]+)]\s\[(\w+)]\s([^:]+:\s\w+\s\w+\s[^:]+:\S+\s[^:]+:\S+\s\S+).*在界面的右侧,您还可以看到该正则表达式的含义。
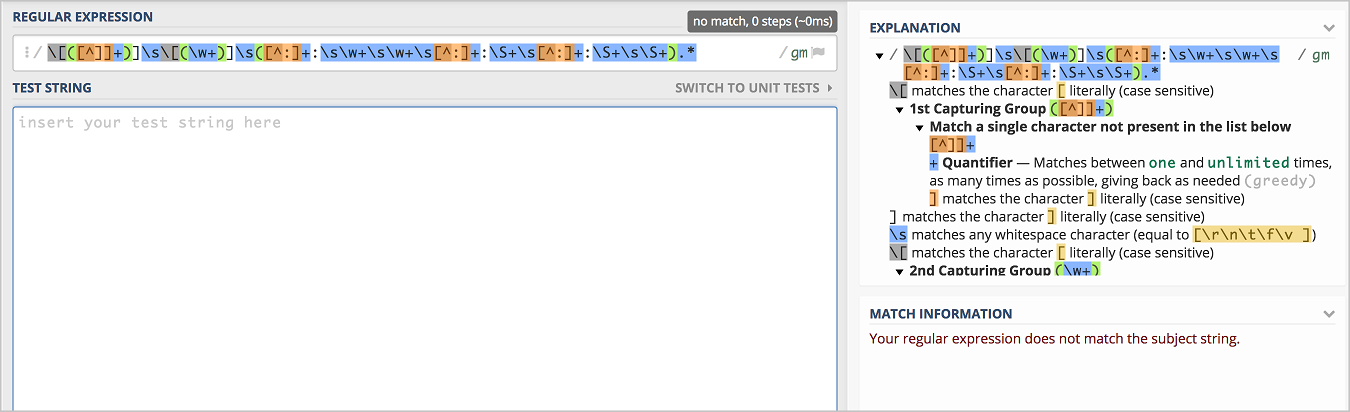
在TEST STRING中粘贴日志样例中的日志,at之后的内容并没有被包含到message字段中(蓝色部分),因此该表达式不能完全匹配样例日志,即对于该样例日志来说,这条正则表达式是错误的,使用这条正则表达式无法正常采集到所有日志数据。
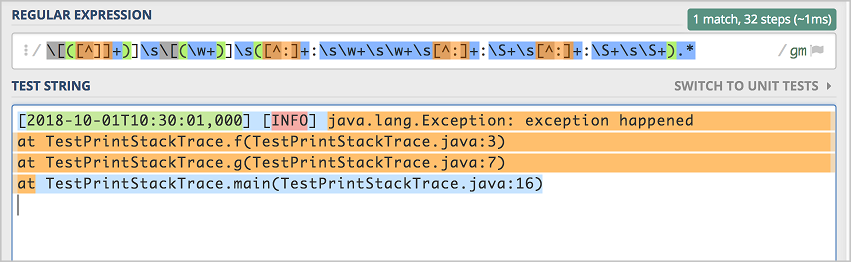
如果日志中只有两个冒号的情况,发现完全匹配失败。
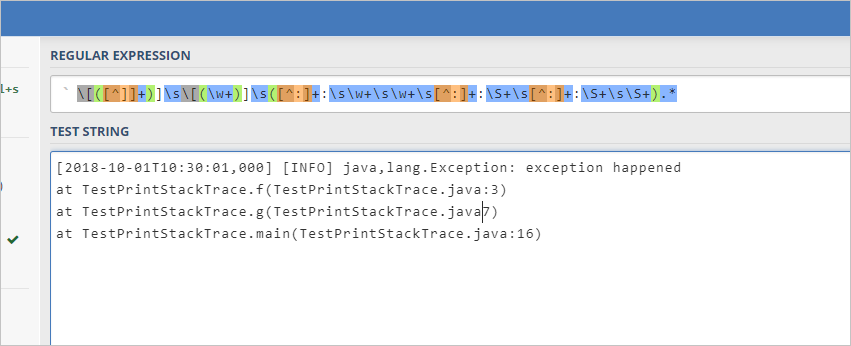
此时将最后一个正则表达式替换为
[\S\s]+,并再次尝试检查匹配程度,能完整的匹配。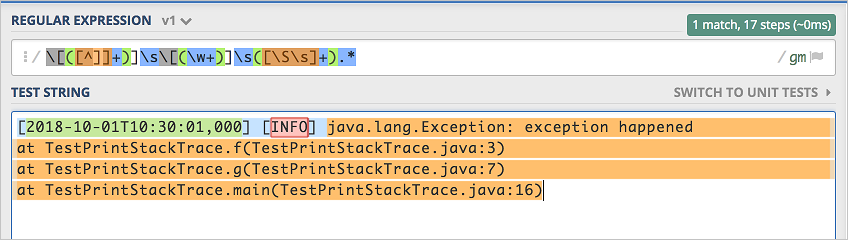 且只有两个冒号的日志也能完整匹配。
且只有两个冒号的日志也能完整匹配。 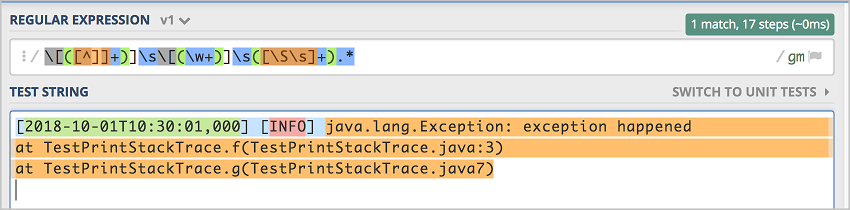
该文章对您有帮助吗?