
RDS SQL Server提供了实例级别的数据库迁移上云方案,支持将自建SQL Server的多库或所有库的全量数据迁移至阿里云RDS SQL Server。您只需先备份自建SQL Server的所有数据库,并将完整备份文件上传到OSS Bucket(存储空间)的同一文件夹中,然后执行迁移上云脚本即可。
如果您的上云迁移级别为数据库,即每次只需完成一个数据库迁移上云,SQL Server提供了以下三种基于OSS的数据库上云方案:
前提条件
源端数据库需为自建SQL Server。
目标端RDS SQL Server实例需满足如下条件:
实例版本为2008 R2、2012及以上。如需创建实例,请参见创建RDS SQL Server实例。
实例版本为RDS SQL Server 2008 R2时,需要在目标RDS实例中创建与待迁移数据库名称相同的数据库,并保持数据库为空。如何创建数据库,请参见创建数据库和账号。
2012及以上版本的实例,无需执行本步骤。
RDS SQL Server实例拥有足够的存储空间。如果空间不足,请提前升级实例空间。
已开通OSS服务。
如果通过RAM用户登录,则必须满足以下条件:
RAM账号具备AliyunOSSFullAccess权限和AliyunRDSFullAccess权限。如何为RAM用户授权,请参见通过RAM对OSS进行权限管理和通过RAM对RDS进行权限管理。
阿里云账号(主账号)已授权RDS官方服务账号可以访问您OSS的权限。
前往RDS实例详情页备份恢复页面,单击OSS备份数据恢复上云按钮。
在数据导入向导页面单击两次下一步,进入3. 数据导入步骤。
若该页面左下角显示您已授权RDS官方服务账号可以访问您OSS的权限,则表示已授权。否则表示还未授权,单击该页面的授权地址同意授权即可。
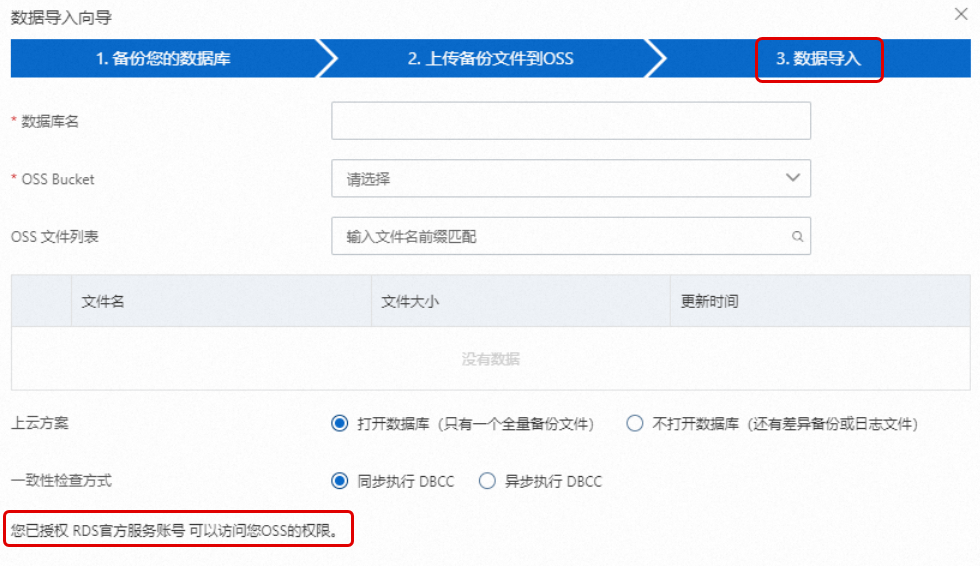
所在阿里云账号(主账号)需手动创建权限策略,然后将权限添加到RAM账号中。
限制条件
本方案仅支持全量迁移上云,暂不支持增量迁移上云。
费用说明
本方案中仅会产生OSS的相关费用,详情如下图所示。

准备工作
安装Python2.7.18版本,详情请参见Python官网。
确认Python安装成功并查看版本。
执行
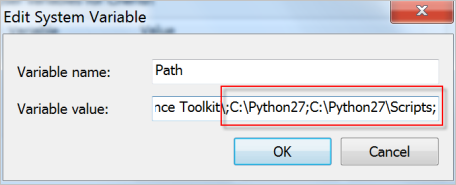
c:\Python27\python.exe -V查看Python版本,若输出内容为Python 2.7.18表示您已安装成功。如果提示“不是内部或外部命令”,请在Path环境变量中增加Python的安装路径和pip命令的目录。
选择下述方法之一,安装SDK依赖包:
方式一:使用pip安装方式二:使用源码安装pip install aliyun-python-sdk-rds pip install oss2# 克隆OpenAPI git clone https://github.com/aliyun/aliyun-openapi-python-sdk.git # 安装阿里云SDK核心库 cd aliyun-python-sdk-core python setup.py install # 安装阿里云RDS SDK cd aliyun-python-sdk-rds python setup.py install # 克隆阿里云OSS SDK git clone https://github.com/aliyun/aliyun-oss-python-sdk.git cd aliyun-oss-python-sdk # 安装阿里云OSS2 SDK python setup.py install
1. 备份自建SQL Server所有数据库
为保障数据一致性,在执行全量备份期间,请勿写入新的数据,请提前安排以免影响业务运行。
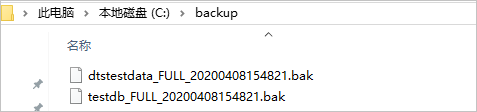
如果您不使用备份脚本来执行备份,备份文件必须按照
数据库名称_备份类型_备份时间.bak的格式来命名,例如Testdb_FULL_20180518153544.bak,否则会导致备份报错。
下载备份脚本。
双击备份脚本,使用Microsoft SQL Server Management Studio(SSMS)客户端打开。SSMS的连接方法,请参见官方文档。
根据业务需求,修改如下参数。
配置项
说明
配置项
说明
@backup_databases_list
需要备份的数据库,多个数据库以分号(;)或者半角逗号(,)分隔。
@backup_type
备份类型,取值如下:
FULL:全量备份。
DIFF:差异备份。
LOG:日志备份。
本方案中,取值需为FULL。
@backup_folder
备份文件所在的本地目录。如不存在,会自动创建。
@is_run
是否执行备份,取值:
1:执行备份。
0:仅执行检查,不执行备份。
运行备份脚本,数据库将备份至指定的目录中。
2. 上传备份文件到OSS
如果没有Bucket,需要先创建存储空间Bucket。
登录OSS管理控制台,单击Bucket列表,然后单击创建Bucket。
配置如下关键参数,其他参数可以保持默认。
创建的存储空间主要用于本次数据上云,只需配置关键参数即可,上云完成后可以及时删除以避免数据泄露及产生相关费用。
创建Bucket时请勿开启数据加密。
参数
说明
取值示例
参数
说明
取值示例
Bucket 名称
存储空间名称,全局唯一,设置后无法修改。
命名规则:
只能包括小写字母、数字和短划线(-)。
必须以小写字母或者数字开头和结尾。
长度必须在3~63字符之间。
migratetest
地域
Bucket所属的地域,如果您通过ECS内网上传数据至Bucket中,且通过内网将数据恢复至RDS中,则需要三者地域保持一致。
华东1(杭州)
存储类型
选择标准存储。本文上云操作不支持其他存储类型的Bucket。
标准存储
上传备份文件到OSS。
本地数据库备份完成后,请将备份文件上传到与您的RDS实例同地域的OSS Bucket中,两者处于同一地域时可通过内网互通(不会产生外网流量费用),且数据上传速度更快。您可以采用如下方法之一:
下载ossbrowser。
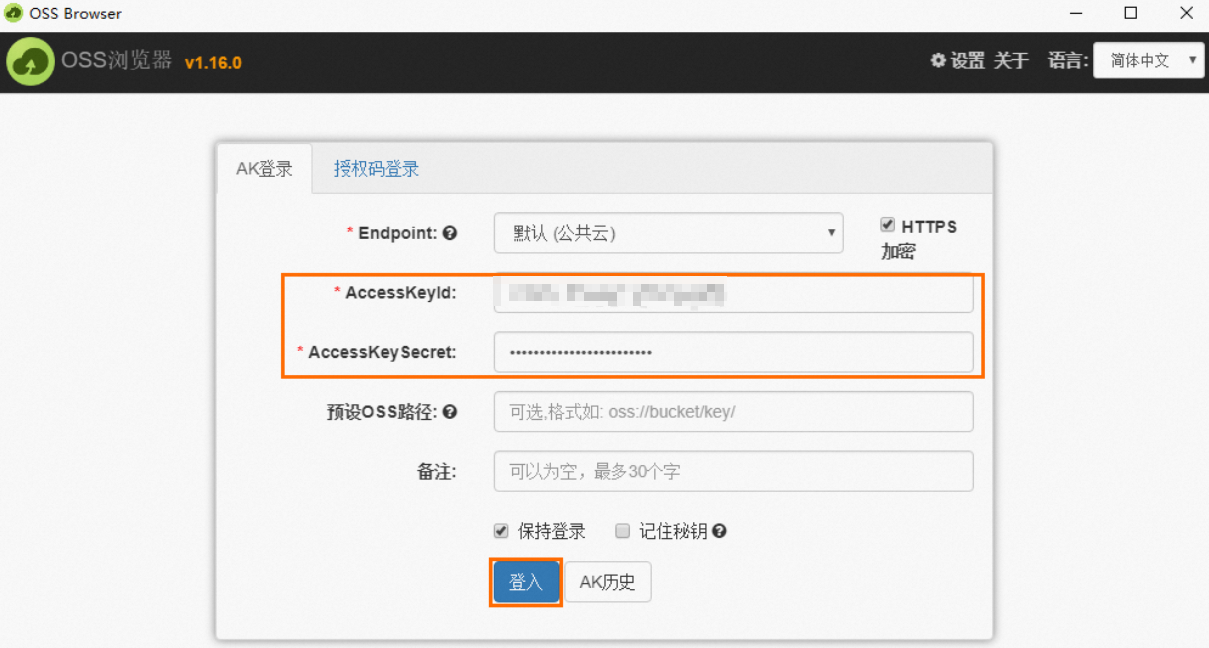
以Windows x64操作系统为例,解压下载的
oss-browser-win32-x64.zip压缩包,双击运行oss-browser.exe应用程序。使用AK登录方式,配置参数AccessKeyId和AccessKeySecret,其他参数保持默认,然后单击登入。
AccessKey用于身份验证,确保数据安全,请妥善保管。
单击目标Bucket,进入存储空间。

单击
 ,选择需要上传的备份文件,然后单击打开,即可将本地文件上传至OSS中。
,选择需要上传的备份文件,然后单击打开,即可将本地文件上传至OSS中。
如果备份文件小于5 GB,建议您直接通过OSS控制台上传备份文件。
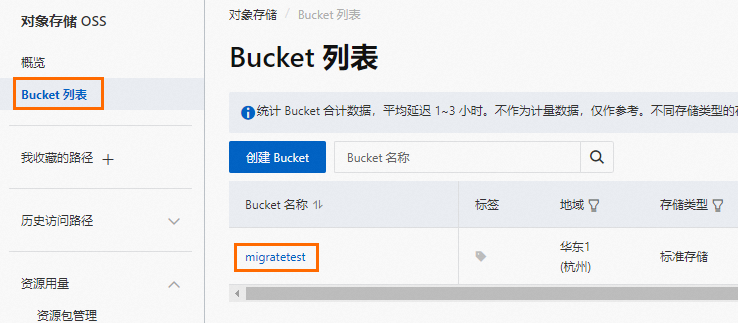
登录OSS管理控制台。
单击Bucket列表,然后单击目标Bucket名称。
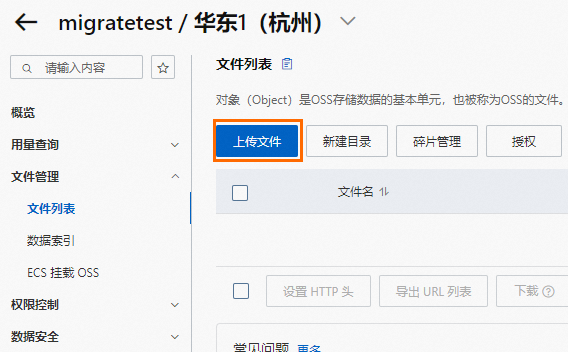
在文件列表中,单击上传文件。
您可以将备份文件拖拽至待上传文件区域,也可以单击扫描文件,选择需要上传的备份文件。
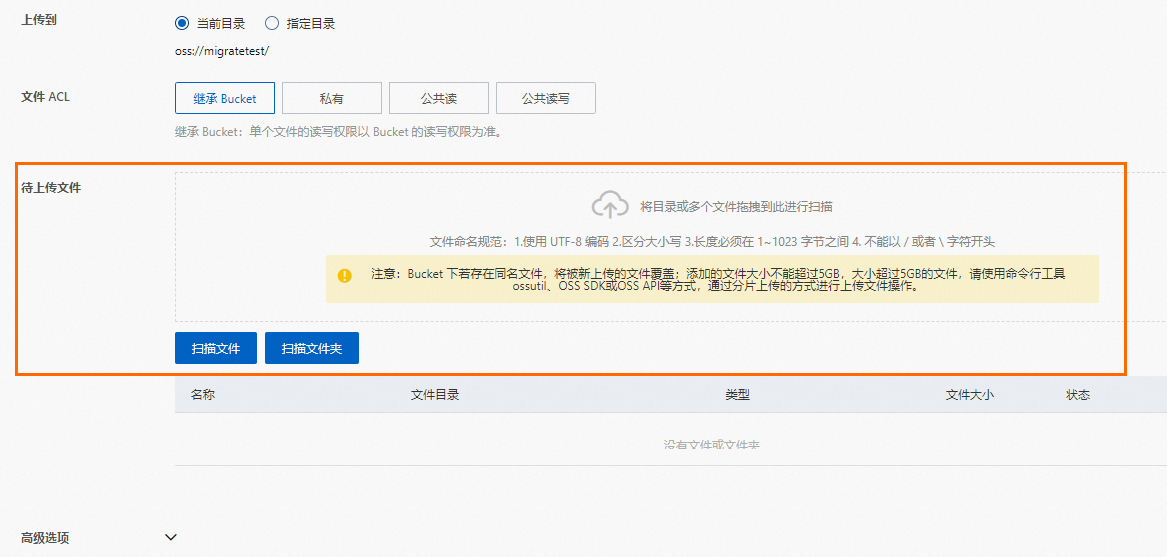
单击页面下方的上传文件,即可将本地备份文件上传至OSS中。
3. 执行迁移上云脚本将数据库迁移至RDS
解压后执行如下命令,了解该脚本需要传入的参数信息。
python ~/Downloads/RDSSQLCreateMigrateTasksBatchly.py -h结果如下:
RDSSQLCreateMigrateTasksBatchly.py -k <access_key_id> -s <access_key_secret> -i <rds_instance_id> -e <oss_endpoint> -b <oss_bucket> -d <directory>参数说明如下:
参数
说明
access_key_id
目标RDS实例所属的阿里云账号的AccessKey ID。
access_key_secret
目标RDS实例所属的阿里云账号的AccessKey Secret。
rds_instance_id
目标RDS实例ID。
oss_endpoint
备份文件所属的存储空间的Endpoint地址。获取方法,请参见存储空间概览。
oss_bucket
备份文件所属的存储空间名称。
directory
备份文件在OSS存储空间中的目录。如果是根目录,请传入
/。执行迁移上云脚本,完成迁移任务。
本示例以将OSS存储空间(名称为
testdatabucket)的Migrationdata目录中所有满足条件的备份文件,全量迁移到RDS SQL Server实例(实例ID为rm-2zesz5774ud8s****)为例。python ~/Downloads/RDSSQLCreateMigrateTasksBatchly.py -k LTAI**************** -s yourAccessKeySecret -i rm-2zesz5774ud8s**** -e oss-cn-beijing.aliyuncs.com -b testdatabucket -d Migrationdata在RDS控制台查看迁移任务的执行进度。
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
根据RDS实例的版本,选择下述操作步骤:
RDS SQL Server 2008 R2RDS SQL Server 2012及以上版本单击左侧导航栏的数据上云,您可以查看到所有提交的迁移上云任务。
可以单击右上角的刷新来查看迁移上云任务的最新状态。
单击左侧导航栏的备份恢复,然后单击备份数据上云记录页签。
默认会展示最近一周的记录,您可以选择时间范围来查看特定时间段内的上云恢复记录。
视频演示
SQL Server实例级别迁移上云
常见错误
错误提示 | 原因 | 解决方法 |
错误提示 | 原因 | 解决方法 |
| 调用OpenAPI时使用的AccessKey ID不正确。 | 传入正确的AccessKey ID和AccessKey Secret,查看方法请参见访问密钥常见问题。 |
| 调用OpenAPI时使用的AccessKey Secret不正确。 | |
| 本方案仅支持RDS SQL Server,不支持其他引擎。 | 将RDS SQL Server作为迁移的目标实例。 |
| RDS实例ID不存在。 | 检查传入的RDS实例ID是否正确。 |
| Endpoint错误,导致连接失败。 | 检查传入的Endpoint是否正确,获取方法请参见存储空间概览。 |
| OSS Bucket(存储空间)不存在。 | 检查传入的OSS Bucket是否正确。 |
| OSS Bucket中对应的文件夹不存在或文件夹中没有满足条件的数据库备份文件。 | 检查OSS Bucket中文件夹是否存在,同时检查该文件夹中是否存在满足条件的数据库备份文件。 |
| 备份文件的名称不符合规范。 | 如果您不使用备份脚本来执行备份,备份文件必须按照 |
| 子账号权限不足。 | 需要为子账号授予OSS和RDS的读写权限(即AliyunOSSFullAccess和AliyunRDSFullAccess权限)。关于授权操作方法,请参见为RAM用户授权。 |
| 调用OpenAPI返回了错误信息。 | 根据错误码和错误信息来分析具体原因,详情请参见OpenAPI错误码。 |
OpenAPI错误码
HTTP Status Code | Error | Description | 说明 |
403 | InvalidDBName | The specified database name is not allowed. | 非法的数据库名字,不允许使用系统数据库名。 |
403 | IncorrectDBInstanceState | Current DB instance state does not support this operation. | RDS实例状态不正确。例如,实例状态为创建中。 |
400 | IncorrectDBInstanceType | Current DB instance type does not support this operation. | 不支持的引擎,该功能仅支持RDS SQL Server。 |
400 | IncorrectDBInstanceLockMode | Current DB instance lock mode does not support this operation. | 数据库锁定状态不正确。 |
400 | InvalidDBName.NotFound | Specified one or more DB name does not exist or DB status does not support. | 数据库不存在。
|
400 | IncorrectDBType | Current DB type does not support this operation. | 数据库类型不支持该操作。 |
400 | IncorrectDBState | Current DB state does not support this operation. | 数据库状态不正确,例如,数据库在创建中或者正在上云任务中。 |
400 | UploadLimitExceeded | UploadTimesQuotaExceeded: Exceeding the daily upload times of this DB. | 上云次数超过限制,每个实例每个库每天不超过20次上云操作。 |
400 | ConcurrentTaskExceeded | Concurrent task exceeding the allowed amount. | 上云次数超过限制,每个实例每天上云总次数不超过500次。 |
400 | IncorrectFileExtension | The file extension does not support. | 备份文件的后缀名错误。 |
400 | InvalidOssUrl | Specified oss url is not valid. | 提供的OSS下载链接地址不可用。 |
400 | BakFileSizeExceeded | Exceeding the allowed bak file size. | 数据库备份文件超过限制,最大不超过3TB。 |
400 | FileSizeExceeded | Exceeding the allowed file size of DB instance. | 还原备份文件后将超过当前实例的存储空间。 |
相关API
API | 描述 |
API | 描述 |
将OSS上的备份文件还原到RDS SQL Server实例,创建数据上云任务。 | |
打开RDS SQL Server备份数据上云任务的数据库。 | |
查询RDS SQL Server实例备份数据上云任务列表。 | |
查询RDS SQL Server备份数据上云任务的文件详情。 |
- 本页导读 (1)
- 前提条件
- 限制条件
- 费用说明
- 准备工作
- 1. 备份自建SQL Server所有数据库
- 2. 上传备份文件到OSS
- 3. 执行迁移上云脚本将数据库迁移至RDS
- 视频演示
- 常见错误
- 相关API
