
热点行是指在数据库中那些会被频繁执行修改操作的数据行。高并发场景下对热点行的更新会造成严重的行锁竞争与等待,影响系统性能。因此PolarDB针对此场景在数据库内核层进行了创新性的优化,极大地提升了系统性能。
背景信息
热点行面临以下问题:
当一个事务对一行数据进行更新时,会对目标数据行加锁,直到事务提交或回滚时才释放。在同一时段内,针对同一数据行,只有一个事务能够进行更新,而其他事务则需要等待。由此可见,对于单一热点行的更新请求实际上是串行执行的,传统的分库分表策略在性能提升方面并不会有太大帮助。
在电商平台业务中,限购、秒杀是常用的促销手段。在这些场景下,大量对热点行的更新请求在极短时间间隔内到达后台数据库系统,必然造成严重的行锁竞争和等待,影响系统性能。如果一个更新请求等待执行的时间变长,将会对业务层面产生显著负面影响。
针对上述问题,单纯提高计算机硬件配置已经无法满足这样的低延迟需求。因此PolarDB在数据库内核层进行了创新性的优化,不但能够自动识别热点行更新请求,而且将一定时间间隔内对同一数据行的更新操作进行分组,不同分组采用流水线的方式并行处理,通过这些优化,极大地提升了系统的性能。
技术方案
串行处理变流水线处理
为了提升数据库系统的性能,最直接的方法是使用并行处理,但是对同一热点行的更新操作很难做到完全并行。PolarDB创新性地使用了流水线处理方式,最大限度地将热点行更新操作并行化。

热点行更新操作所使用的SQL语句会用
autocommit或者COMMIT_ON_SUCCESS进行标记。优化后的MySQL内核层会自动识别带此类标记的更新操作,在一定的时间间隔内,将收集到的更新操作按照主键或者唯一键进行Hash,对于Hash到同一个桶中的更新操作,会将它们按照到达的先后顺序分组分批地进行处理和提交。为了使用流水线方式处理这些更新操作,需要使用两个执行单元对它们进行分组。当第一个分组收集完毕准备提交时,第二个分组立即开始收集更新操作。当第二个分组收集完毕准备提交时,第一个分组已经提交完毕并开始收集新一批的更新操作,两个分组不断切换,并行执行。
现如今多核CPU的使用已经非常普遍。这样的流水线式的处理方式能够充分利用硬件资源,提升CPU的使用率和数据库系统的并行处理能力,从而最大限度地提升数据库系统的吞吐量。
消除申请行锁时的等待
为了保证数据的逻辑一致性,对一个数据行进行更新时,首先会对该数据行加锁。如果加锁请求无法立刻满足,则进入等待状态。这样一来,不但增加了处理延迟,还会触发死锁检测,导致额外的资源消耗。
前面提到,我们会按照时间顺序将对同一数据行的更新操作进行分组。组内第一个更新操作为Leader,其读取目标数据行并且加锁。后续更新操作为Follower,其对目标数据行加锁时,如果发现Leader已经持有行锁,无需等待,直接获得行锁。
通过这个优化,能够减少行锁的加锁次数和时间开销,整个数据库系统的性能显著提升。
减少B-tree索引的遍历
MySQL是以B-tree索引的方式管理数据的。每次执行查询时,都需要遍历索引才能定位到目标数据行,数据表越大,索引层级越多,遍历时间就越长。
在前面提到的对更新操作进行分组的机制中,只有每组的Leader遍历索引定位数据行,之后把更新后的数据行缓存(Row Cache)在内存中。同组的Follower加锁成功后,直接从内存中读取目标数据行,不需要再次遍历索引。
这样一来,从整体上减少了索引遍历的次数和时间开销。
前提条件
您的PolarDB集群需为以下版本之一:
MySQL 5.6,且内核小版本需为20200601及以上版本。
MySQL 5.7,且内核小版本需为5.7.1.0.17及以上版本。
MySQL 8.0,且内核小版本需为8.0.1.1.10及以上版本。
已开启Binlog。
集群参数
rds_ic_reduce_hint_enable处于关闭状态。MySQL 5.6与MySQL 8.0:集群参数默认处于关闭状态。
MySQL 5.7:集群默认处于开启状态,开启热点行优化功能前,需修改参数值为OFF(关闭)。
说明集群参数在PolarDB控制台上都已加上MySQL配置文件的兼容性前缀loose_。如果您需要在PolarDB控制台修改
rds_ic_reduce_hint_enable参数,请选择带loose_前缀的参数(即loose_rds_ic_reduce_hint_enable)进行修改。
使用限制
在以下场景中,热点行性能优化将不会被使用:
热点行所属的数据表是分区表。
热点行所属的数据表上定义了触发器(Trigger)。
热点行使用了Statement Queue机制。
在全局Binlog开启的情况下,若会话级别的Binlog关闭,执行
UPDATE语句将不会使用热点行性能优化。开启热点行优化功能后,仅依赖
ON UPDATE CURRENT_TIMESTAMP属性自动更新的列会失效。请在UPDATE语句中使用SET column_name = CURRENT_TIMESTAMP(n)对此类列显式赋值。
使用说明
开启热点行性能优化功能。
您可以在PolarDB控制台上修改以下参数,以开启或关闭热点行性能优化功能。
参数
说明
hotspot
热点行性能优化功能总开关。取值范围如下:
ON:开启。
OFF(默认):关闭。
说明集群参数在PolarDB控制台上都已加上MySQL配置文件的兼容性前缀loose_。如果您需要在PolarDB控制台修改hotspot参数,请选择带loose_前缀的参数(即loose_hotspot)进行修改。
使用Hint语法来使用热点行性能优化功能。
Hint
是否必选
说明
必选
更新成功时提交。
可选
更新失败时回滚。
可选
显式指定该请求只会更新一行,若不符合则更新失败。
说明由于Hint语法生效会自动提交事务,因此Hint需要位于事务的最后一条SQL语句。
示例:更新
sbtest表中c列的数值。UPDATE /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW(1) */ sbtest SET c = c + 1 WHERE id = 1;
相关操作
自定义参数配置
PolarDB控制台不支持对以下参数进行修改。如果您需要进行修改,请前往配额中心,在配额ID为polardb_mysql_hotspot的操作列,单击申请。
参数 | 说明 |
hotspot_for_autocommit |
|
hotspot_update_max_wait_time | 行数据分组批量更新(Group Update)过程中Leader等待Follower加入该分组的等待时间。
|
hotspot_lock_type | 行数据分组批量更新(Group Update)过程中是否使用新类型的行锁。取值范围如下:
说明
|
查看参数配置
您可以使用如下命令查看热点行性能优化功能的参数配置。
SHOW variables LIKE "hotspot%";返回结果示例:
+------------------------------+-------+
|Variable_name | Value |
+------------------------------+-------+
|hotspot | OFF |
|hotspot_for_autocommit | OFF |
|hotspot_lock_type | OFF |
|hotspot_update_max_wait_time | 100 |
+------------------------------+-------+查看使用情况
您可以使用如下命令查看热点行性能优化功能的使用情况。
SHOW GLOBAL status LIKE 'Group_update%';性能测试
测试工具
Sysbench是一个开源的、跨平台的性能测试工具,主要用于数据库基准测试(如MySQL)、 系统性能测试(如CPU、内存、IO、线程)。它支持多线程测试,并通过Lua脚本灵活控制测试逻辑,适合数据库性能评估、压力测试等场景。
测试数据表与测试语句
数据表定义
CREATE TABLE sbtest (id INT UNSIGNED NOT NULL, c BIGINT UNSIGNED NOT NULL, PRIMARY KEY (id));测试语句
UPDATE /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW(1) */ sbtest SET c = c + 1 WHERE id = 1;
测试结果
PolarDB MySQL版5.6
测试场景
单个热点行加8核CPU。
测试结果
在单热点行加8核CPU的场景下,引入热点行性能优化后,库存热点性能在高并发时提升近50倍。
测试数据(QPS)
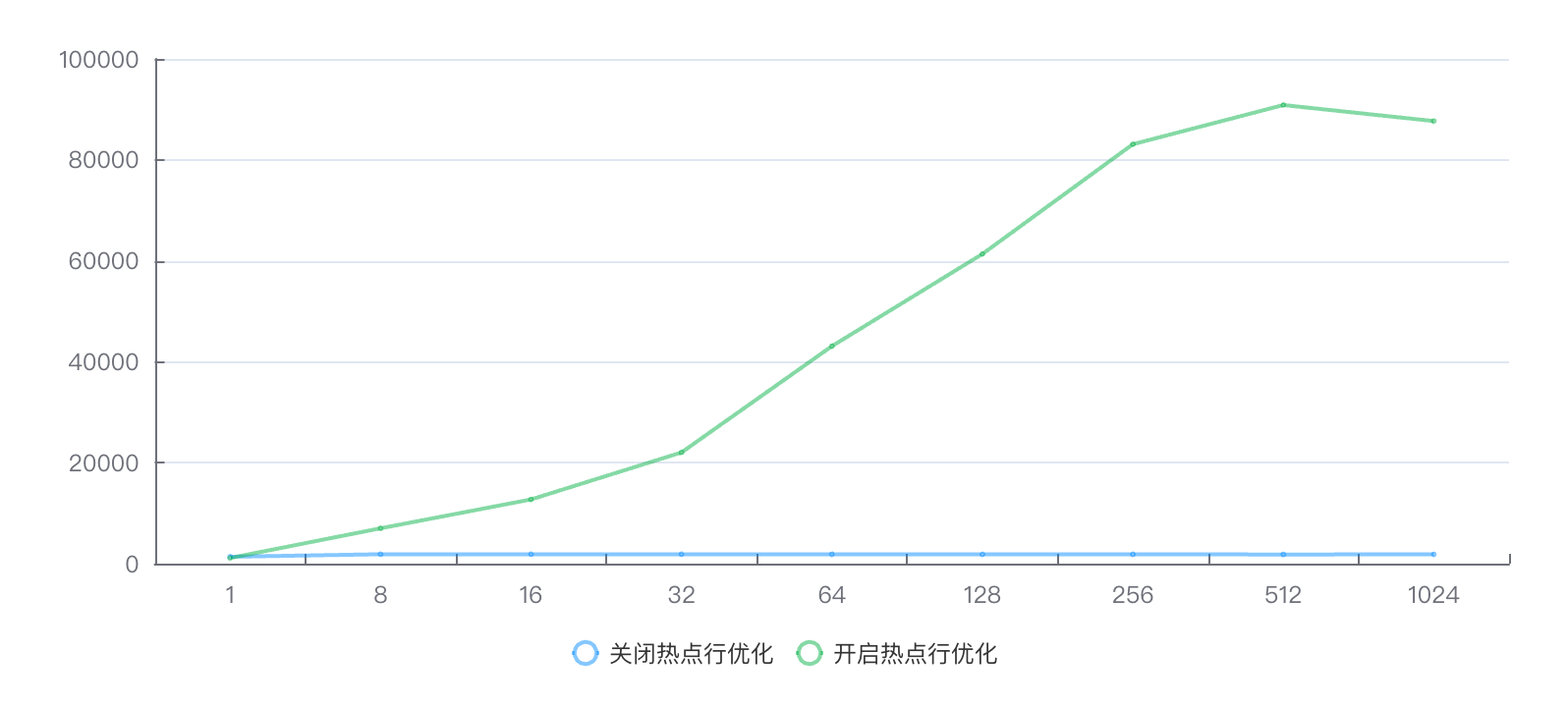
并发数 | 1 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
关闭热点行优化 | 1365.31 | 1863.94 | 1866.6 | 1862.64 | 1867.32 | 1832.51 | 1838.31 | 1819.52 | 1833.2 |
开启热点行优化 | 1114.79 | 7000.19 | 12717.32 | 22029.48 | 43096.06 | 61349.7 | 83098.69 | 90860.94 | 87689 |
PolarDB MySQL版5.7
测试场景
单个热点行加8核CPU。
测试结果
在单热点行加8核CPU的场景下,引入热点行性能优化后,库存热点性能在高并发时提升近35倍。
测试数据
QPS
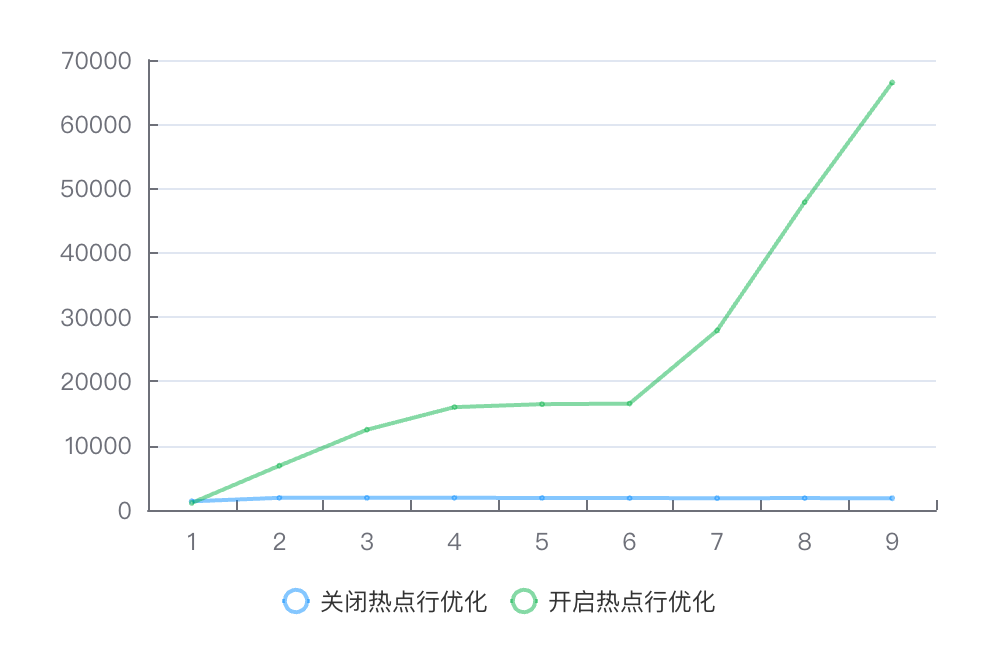
并发数 | 1 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
关闭热点行优化 | 1348.49 | 1892.29 | 1889.77 | 1895.86 | 1875.2 | 1850.26 | 1843.62 | 1849.92 | 1835.68 |
开启热点行优化 | 1104.9 | 6886.89 | 12485.17 | 16003.23 | 16460.31 | 16548.86 | 27920.89 | 47893.96 | 66500.92 |
lat95th (95分位延迟)
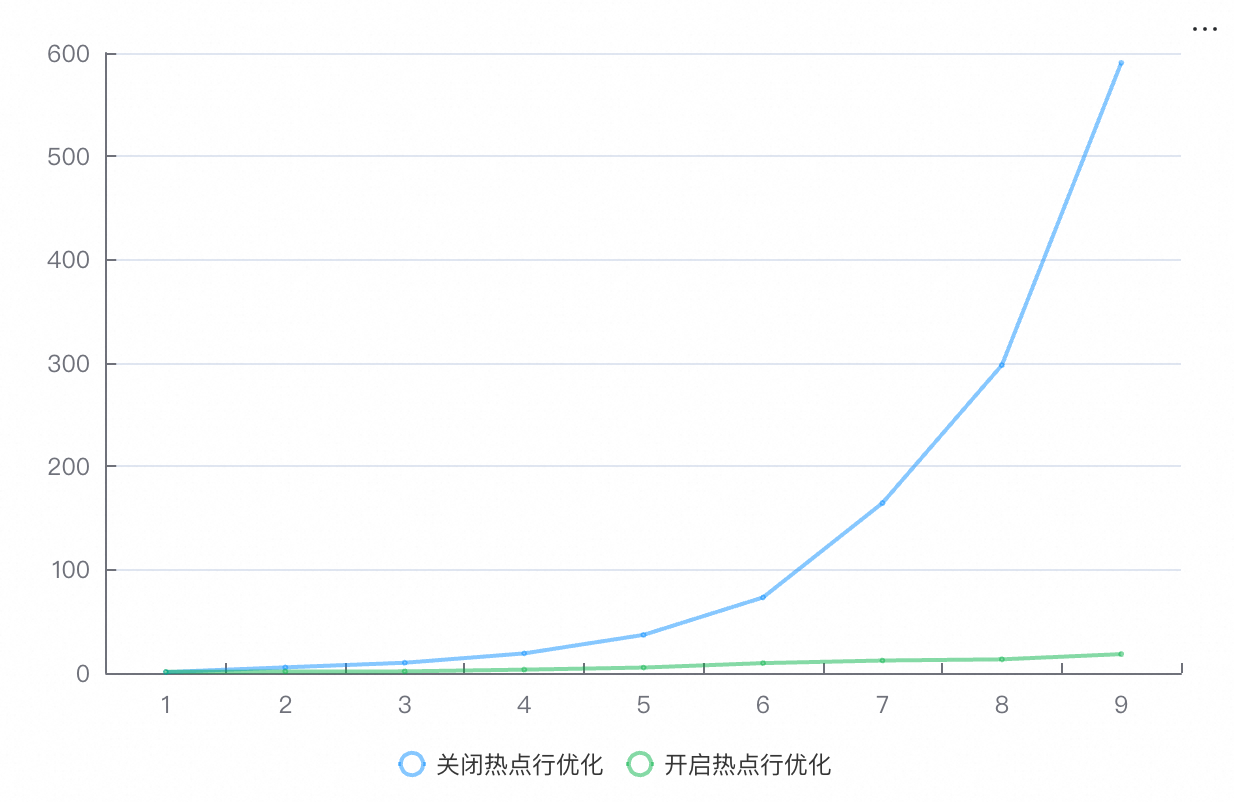
并发数 | 1 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
关闭热点行优化 | 0.9 | 5.47 | 9.91 | 18.95 | 36.89 | 73.13 | 164.45 | 297.92 | 590.56 |
开启热点行优化 | 1.08 | 1.44 | 1.58 | 3.25 | 5.28 | 9.56 | 12.08 | 13.22 | 18.28 |
PolarDB MySQL版8.0
测试场景
单个热点行加8核CPU。
测试结果
在单热点行加8核CPU的场景下,引入热点行性能优化后,库存热点性能在高并发时提升近26倍。
测试数据
QPS
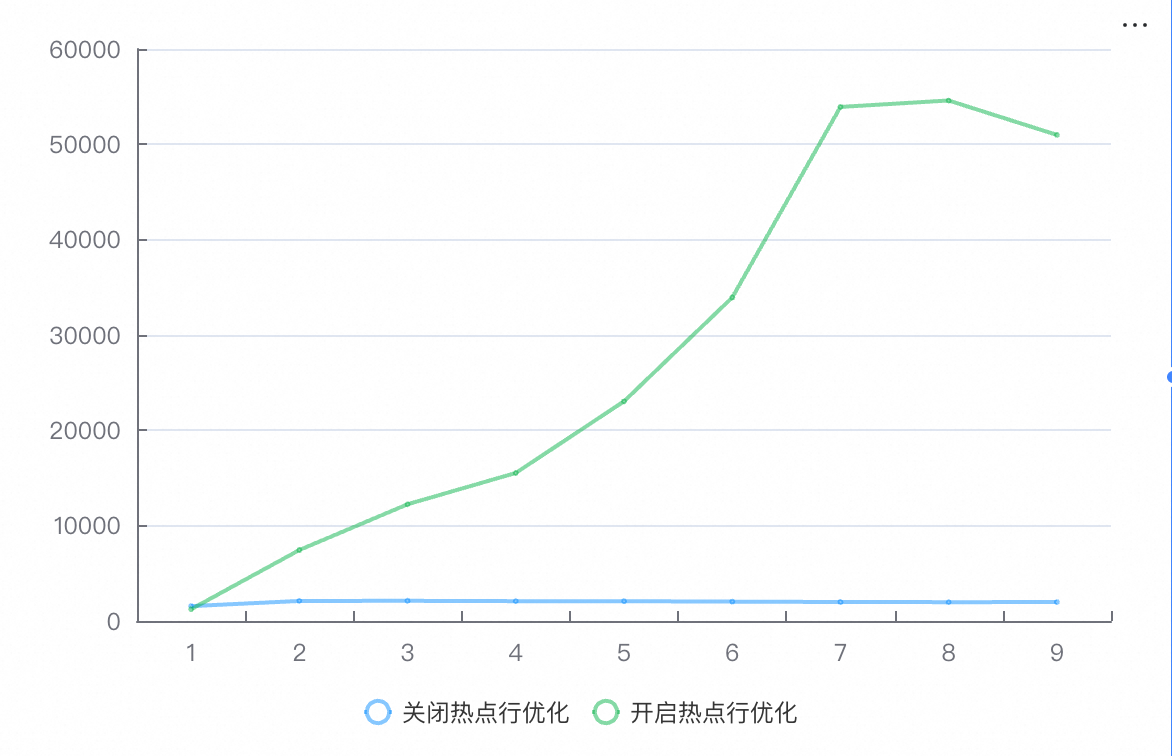
并发数 | 1 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
关闭热点行优化 | 1559.14 | 2103.82 | 2116.4 | 2082.1 | 2079.74 | 2031.64 | 1993.09 | 1977.6 | 1983.61 |
开启热点行优化 | 1237.28 | 7443.04 | 12244.19 | 15529.52 | 23041.15 | 33931.18 | 53924.24 | 54598.6 | 50988.22 |
lat95th (95分位延迟)
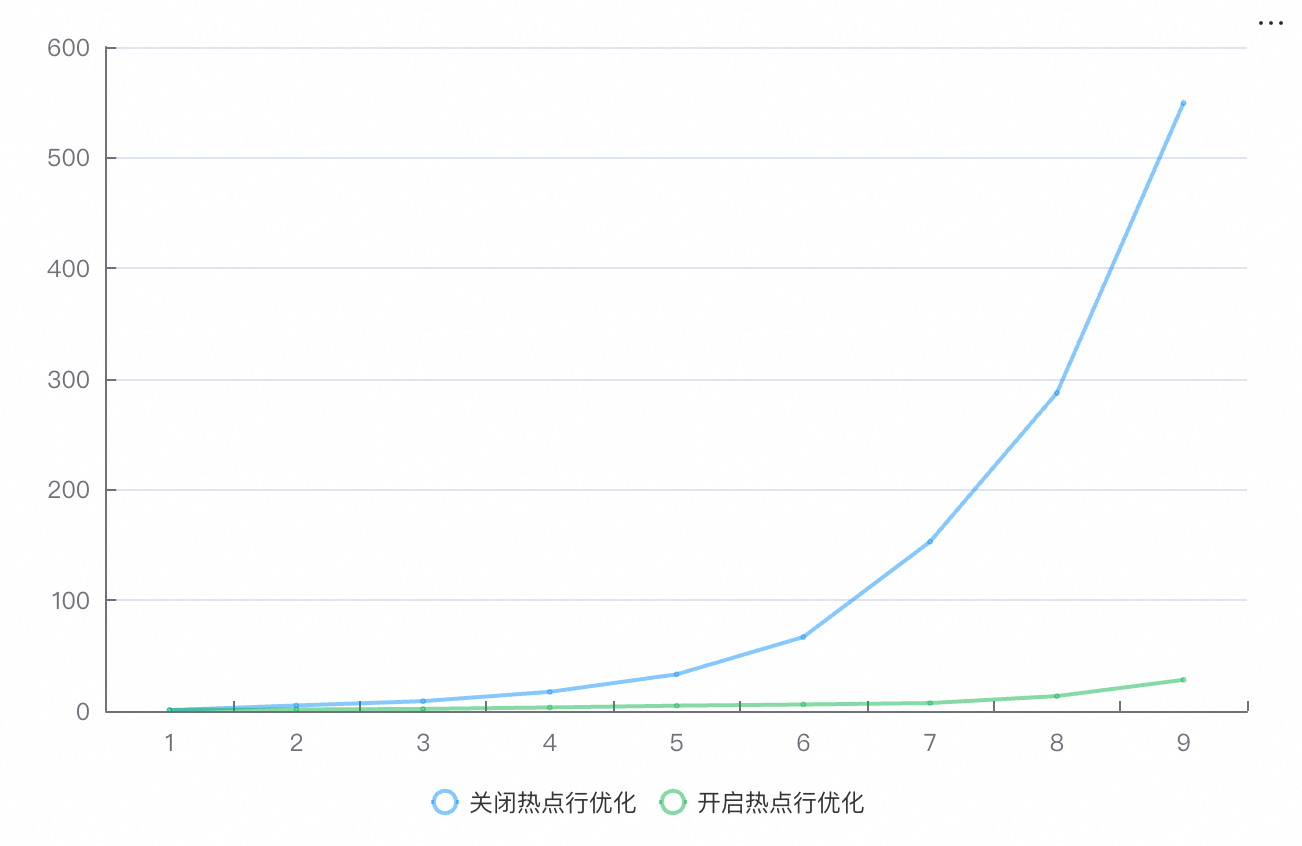
并发数 | 1 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
关闭热点行优化 | 0.8 | 5 | 8.9 | 17.32 | 33.12 | 66.84 | 153.02 | 287.38 | 549.52 |
开启热点行优化 | 0.97 | 1.34 | 1.89 | 3.19 | 4.82 | 5.88 | 7.17 | 13.46 | 28.16 |
附录:性能测试步骤
准备一台ECS实例,并安装Sysbench。
将以下
oltp_inventory.lua放在Sysbench源码的src/lua目录下。#!/usr/bin/env sysbench -- it is to test inventory_hotspot performance sysbench.cmdline.options= { inventory_hotspot = {"enable ali inventory hotspot", 'off'}, tables = {"table number", 1}, table_size = {"table size", 1}, oltp_skip_trx = {'skip trx', true}, hotspot_rows = {'hotspot row number', 1} } function cleanup() drv = sysbench.sql.driver() con = drv:connect() for i = 1, sysbench.opt.tables do print(string.format("drop table sbtest%d ...", i)) drop_table(drv, con, i) end end function drop_table(drv, con, table_id) local query query = string.format("drop table if exists sbtest%d ", table_id) con:query(query) end function create_table(drv, con, table_id) local query query = string.format("CREATE TABLE sbtest%d (id INT UNSIGNED NOT NULL, c BIGINT UNSIGNED NOT NULL, PRIMARY KEY (id))", table_id) con:query(query) for i=1, sysbench.opt.table_size do con:query("INSERT INTO sbtest" .. table_id .. "(id, c) values (" ..i.. ", 1)") end end function prepare() drv = sysbench.sql.driver() con = drv:connect() for i = 1, sysbench.opt.tables do print(string.format("Creating table sbtest%d ...", i)) create_table(drv, con, i) end end function thread_init() drv = sysbench.sql.driver() con = drv:connect() begin_query = 'BEGIN' commit_query = 'COMMIT' end function event() local table_name table_name = "sbtest" .. sysbench.rand.uniform(1, sysbench.opt.tables) local min_line = math.min(sysbench.opt.table_size, sysbench.opt.hotspot_rows) local row_id = sysbench.rand.uniform(1, min_line) if not sysbench.opt.oltp_skip_trx then con:query(begin_query) end if (sysbench.opt.inventory_hotspot == "on") then con:query("UPDATE COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW 1 " .. table_name .. " SET c=c+1 WHERE id =" .. row_id) else con:query("UPDATE " .. table_name .. " SET c=c+1 WHERE id = " .. row_id) end if not sysbench.opt.oltp_skip_trx then if (sysbench.opt.inventory_hotspot == "on") then con:query(commit_query) end end end function thread_done() con:disconnect() end执行Sysbench测试。
准备数据。
sysbench --hotspot_rows=1 --histogram=on --mysql-user=<user> --inventory_hotspot=on --mysql-host=<host> --threads=1 --report-interval=1 --mysql-password=<password> --tables=1 --table-size=1 --oltp_skip_trx=true --db-driver=mysql --percentile=95 --time=300 --mysql-port=<port> --events=0 --mysql-db=<database> oltp_inventory prepare运行测试。
sysbench --db-driver=mysql --mysql-host=<host> --mysql-port=<port> --mysql-user=<user> --mysql-password=<password> --mysql-db=<database> --range-selects=0 --table_size=25000 --tables=250 --events=0 --time=600 --rand-type=uniform --threads=<threads> oltp_inventory run
输入参数说明
参数类别
说明
mysql-host
集群连接地址。
mysql-port
集群连接地址对应的端口。
mysql-user
集群用户名称。
mysql-password
集群用户名称对应的密码。
mysql-db
数据库名称
输出参数说明
参数类别
展示内容
说明
tables
数据表数量
所有参与测试的数据表数量。
table_size
数据表行数
展示每个表的记录数量。
数据量大小
以存储空间(如MB/GB)为单位展示表的数据量。
threads
并发线程数
显示当前配置的线程数量。
线程状态
支持实时查看线程运行状态。