
横向聚类
更新时间:2023-11-03 02:53:44
一、组件说明
横向聚类组件是横向场景下的一种无监督机器学习算法,用于将n个数据点分成k个簇,使得簇内的数据点具有高度相似性。聚类算法通过度量数据点之前的相似性或距离来确定数据点之间的关系,将相似的数据点划分到同一簇中。适用于对没有标签的数据进行归类和分组。
组件截图
二、参数说明
字段设置
参数名称 | 参数说明 |
特征字段 | 用于训练的特征字段,数值类型,多选。 |
输入特征为KV格式 | 目前DataTrust支持KV格式的特征输入(即LIBSVM格式)。使用时,数据格式如下,其中key的下标应从1开始,value应均为数值: |

参数设置
参数名称 | 参数英文名称 | 参数说明 |
聚类数 | cluster_num | 全局目标簇数量 |
最大迭代次数 | max_iters | 全局最大迭代次数 |
使用方本地聚类数 | host_cluster_num | 使用方本地进行聚类训练的目标簇数量。 |
使用方最大迭代数 | host_max_iters | 使用方本地进行聚类训练的最大迭代次数。 |
加持方本地聚类数 | slave_cluster_num | 加持方本地进行聚类训练的目标簇数量。 |
加持方最大迭代数 | slave_max_iters | 加持方本地进行聚类训练的最大迭代次数。 |
训练成功后的模型保存
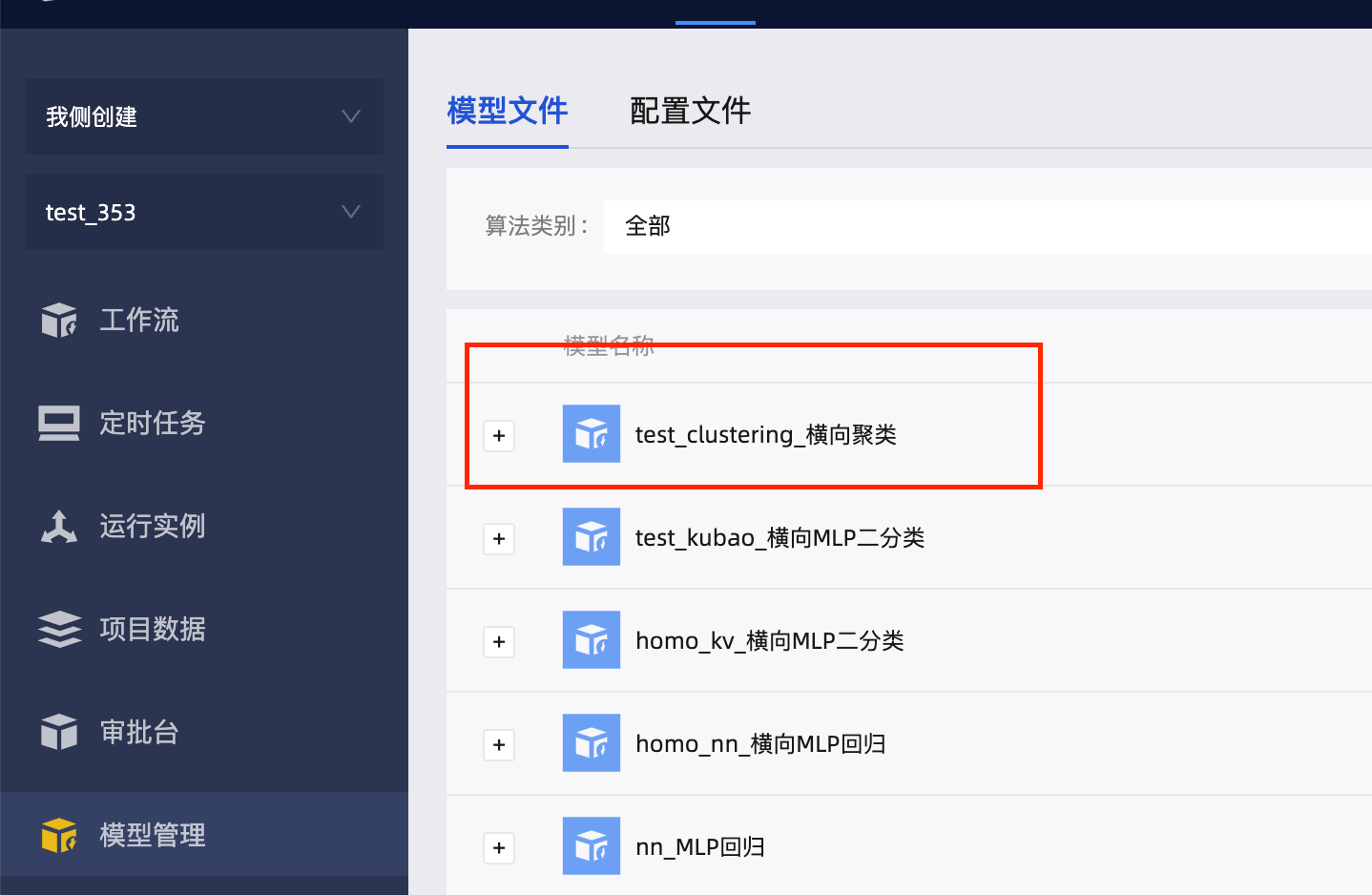
训练成功后,双方本地均保存有最终的全局模型。该全局模型支持双方进行单方预测、评估使用。训练成功的模型保存在【项目台】-【模型管理】-【模型文件】中,保存名称为${工作流名称}_${建模组件名称}。例如,本项目中有成功建模的任务名为“1_横向虚拟关联_train算法”,其中有建模组件名字为“横向聚类”,则模型名字为“1_横向虚拟关联_train算法_聚类”,如下图所示:
该文章对您有帮助吗?
- 本页导读 (0)
- 一、组件说明
- 组件截图
- 二、参数说明
- 字段设置
- 参数设置
- 训练成功后的模型保存