
避免下盘
在AnalyticDB PostgreSQL版查询执行过程中,当集群内存不足时,数据库可能会选择将临时结果暂存到磁盘。由于磁盘操作相对内存访问缓慢,避免查询执行过程中的算子下盘有助于提高查询效率。
算子下盘常见原因
在数据量较大的表上执行SORT、JOIN、HASH等操作时,可能由于内存不足导致临时结果落盘。您通过观察执行计划(explain analyze)可以辨认发生了算子下盘:
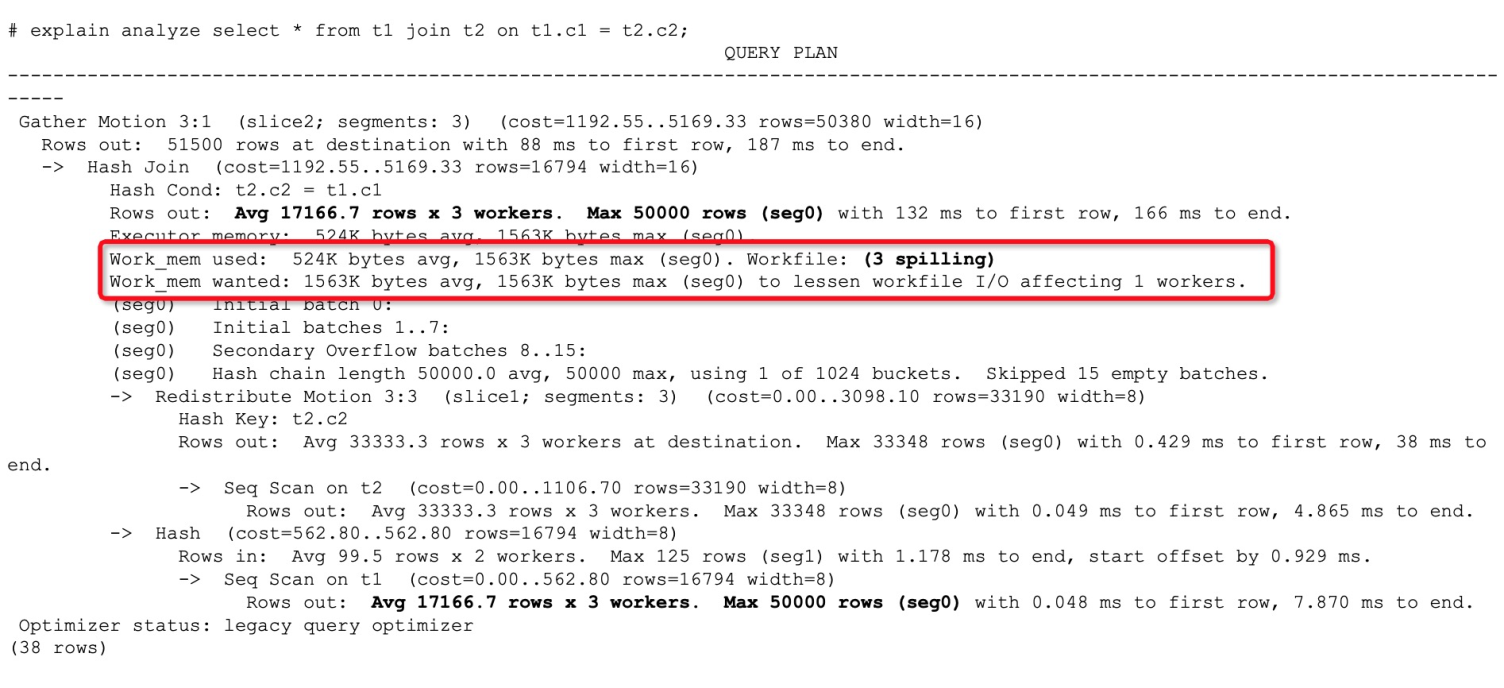
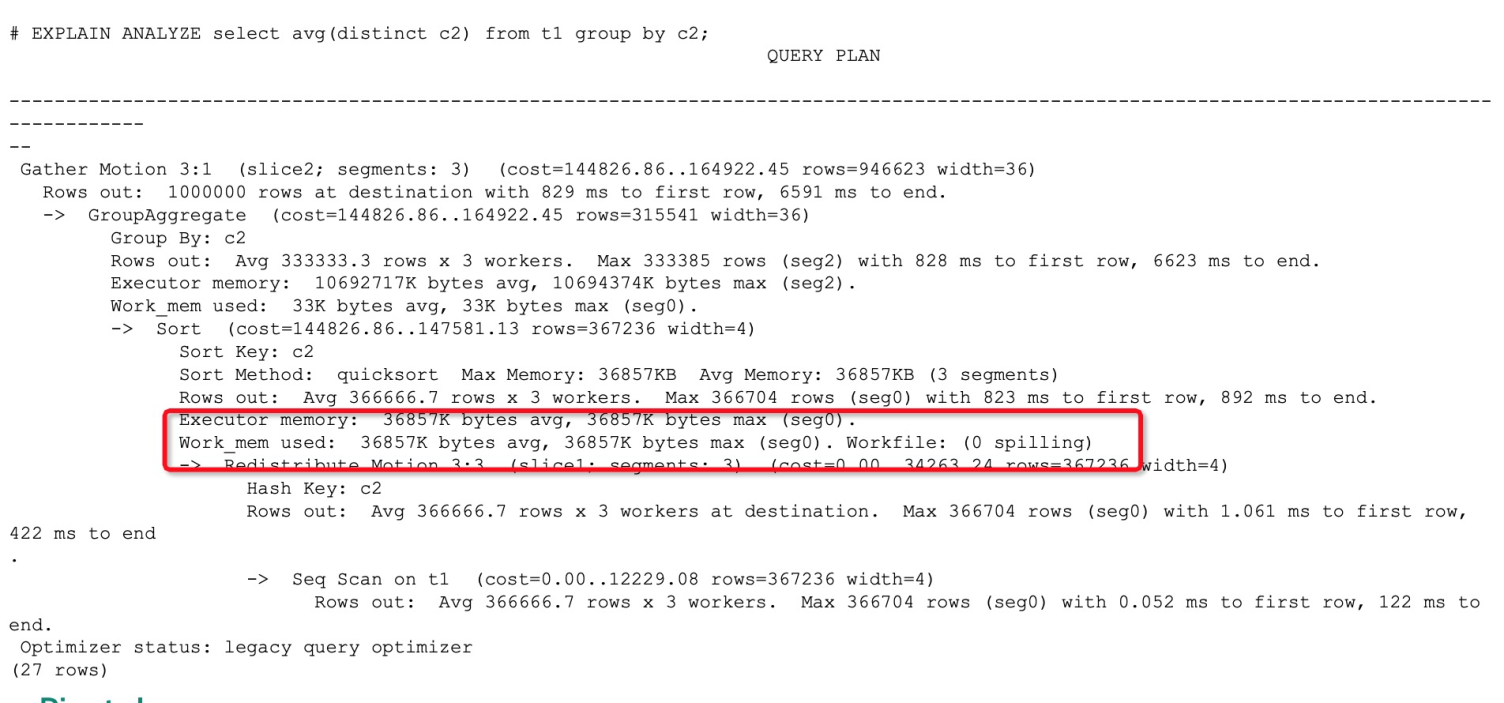
上图是一个发生了算子落盘的查询计划例子,执行计划中Workfile这一项显示了是否发生了算子落盘。而不发生算子落盘的执行计划对应项会显示为0,如下图所示:
产生算子下盘的常见原因包括:
查询能够使用的内存太小。
查询的计算量过大,需要的内存太大。
产生了数据倾斜。
下面详细介绍三种原因导致的算子下盘场景及解决方法。
常见算子下盘场景及解决方法
查询内存太小导致的算子下盘
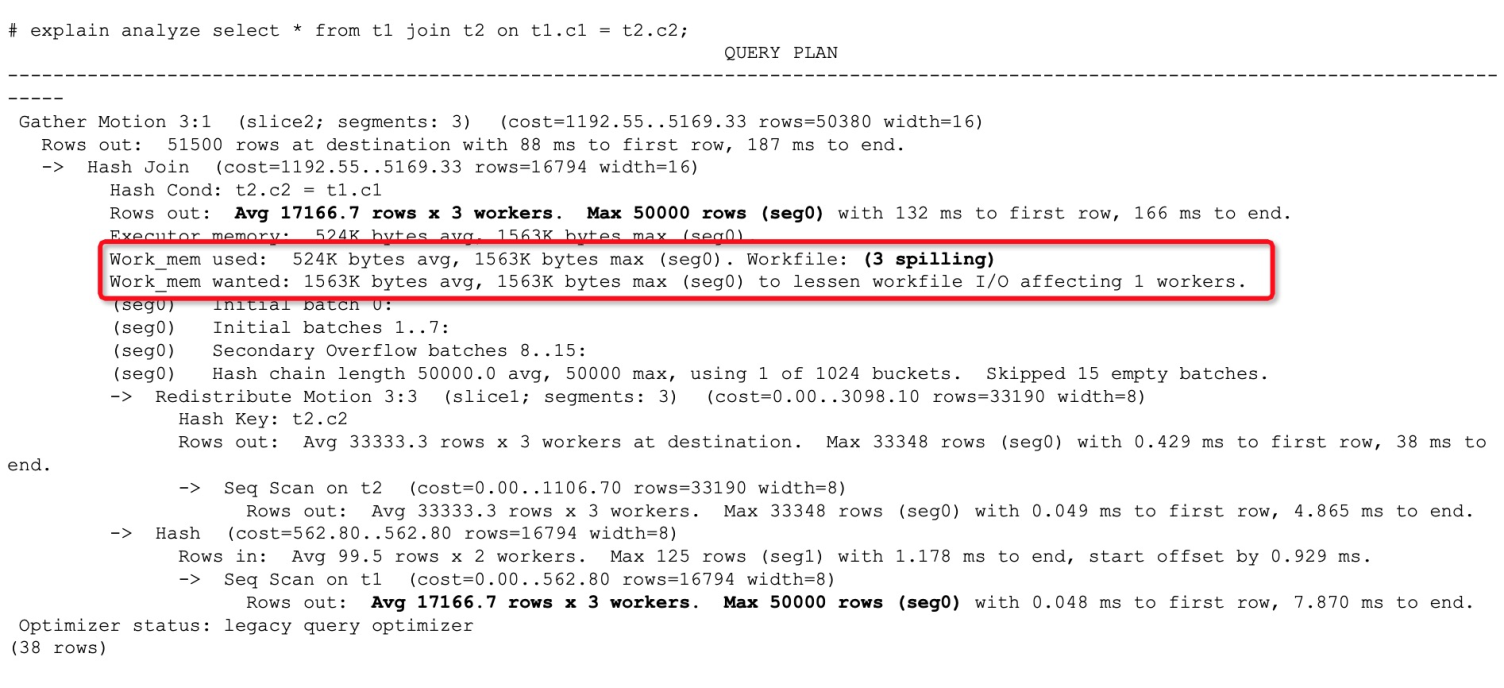
通过观察执行计划发现,算子需要的内存并不大,只有几K或几M,但还是发生了算子下盘。这种情况往往是查询能够使用的内存调小导致的,原因可能是受到了resource group或resource queue的限制,或者statement_mem参数本身设置的不合理。
对于这种情况,您可以通过调大statement_mem参数到一个合理的参数来避免算子下盘:
SET statement_mem TO '256MB';计算量过大导致的算子下盘
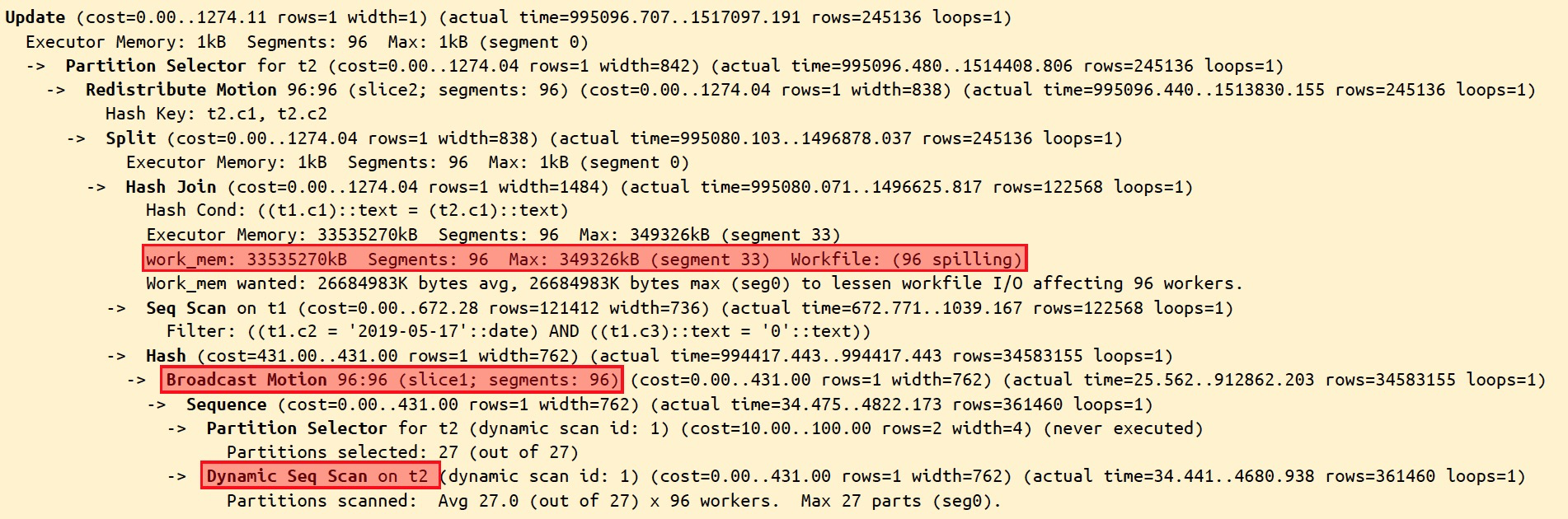
在某些时候,我们发现我们已经设置了较大的查询内存(statement_mem),但我们通过执行计划发现,算子执行过程中需要的内存远远大于我们设置的内存,这个时候往往是计算量过大导致的。这个时候我们需要考虑能够执行analyze、建立索引等方式减少算子执行中的计算量。
以图中的执行计划为例,我们发现较大的算子落盘,进一步分析我们发现,在这个执行计划中,错误了估计了t2子表的行数(rows),导致t2一个大表被估计为1行的小表,进行了broadcast,并做了hashjoin的内标,导致了巨大的计算量。我们对t2表执行了analyze之后,消除了算子下盘。
数据倾斜导致的算子下盘
数据倾斜也是一种常见的会导致算子下盘的因素,数据倾斜会导致单个Segment上的数据量和计算量远远超过其他Segment,导致可用内存不够算子下盘。对于数据倾斜的检测和消除,请参见数据倾斜诊断。