
分区裁剪
云原生数据仓库AnalyticDB PostgreSQL版支持静态分区和动态分区裁剪。在扫描分区表前,能通过检查分区约束条件与每个分区的定义,提前排除不需要扫描的分区,大大减少从磁盘中读取的数据量,从而缩短运行时间,改善查询性能,减少资源浪费。
云原生数据仓库AnalyticDB PostgreSQL版支持按列分区。分区表能够将大的事实表分解成多个小表,根据查询条件自动跳过不满足条件的分区数据,从而提高查询效率。分区裁剪(Partition Pruning)是数据库分区表中常用的性能优化手段。
使用限制
仅支持分区表。
仅支持在Range或List分区列上使用范围、等式和IN列表谓词。AnalyticDB PostgreSQL 7.0版支持Hash分区,Hash分区只能通过等值条件进行裁剪。
动态分区裁剪仅支持分区列的等值条件,如
=或IN等。分区裁剪效果与数据分布有关,如果分区约束无法有效裁剪,性能会回退到与全表扫描一致。
静态分区裁剪
概述
如果分区约束为确定的表达式,在查询规划阶段就可以根据分区约束表达式裁掉不需要扫描的分区,这种在查询规划阶段做分区裁剪的方式称为静态分区裁剪。
AnalyticDB PostgreSQL版主要通过静态谓词确定何时使用静态裁剪。支持的静态谓词包括:=、>、>=、<、<=五种操作符,以及IN列表。
静态分区裁剪可以从EXPLAIN输出查看裁剪结果。
示例
示例一:通过静态谓词
=进行分区裁剪。--创建分区表。 CREATE TABLE sales (id int, year int, month int, day int, region text) DISTRIBUTED BY (id) PARTITION BY RANGE (month) SUBPARTITION BY LIST (region) SUBPARTITION TEMPLATE ( SUBPARTITION usa VALUES ('usa'), SUBPARTITION europe VALUES ('europe'), SUBPARTITION asia VALUES ('asia'), DEFAULT SUBPARTITION other_regions) (START (1) END (13) EVERY (1), DEFAULT PARTITION other_months ); --分区裁剪。 EXPLAIN SELECT * FROM sales WHERE year = 2008 AND month = 1 AND day = 3 AND region = 'usa';由于查询条件落在一级分区1的二级子分区
'usa'上,查询只会扫描读取这个二级子分区数据。如下其查询计划显示,总计52个三级子分区中,只有一个分区被读取(Partitions selected)。Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..431.00 rows=1 width=24) -> Sequence (cost=0.00..431.00 rows=1 width=24) -> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4) Partitions selected: 1 (out of 52) -> Dynamic Seq Scan on sales (dynamic scan id: 1) (cost=0.00..431.00 rows=1 width=24) Filter: ((year = 2008) AND (month = 1) AND (day = 3) AND (region = 'usa'::text))示例二:通过静态谓词
>=及IN列表进行分区裁剪。EXPLAIN SELECT * FROM sales WHERE month in (1,5) AND region >= 'usa'; QUERY PLAN ----------------------------------------------------------------------------------------------------- Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..431.00 rows=1 width=24) -> Sequence (cost=0.00..431.00 rows=1 width=24) -> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4) Partitions selected: 6 (out of 52) -> Dynamic Seq Scan on sales (dynamic scan id: 1) (cost=0.00..431.00 rows=1 width=24) Filter: ((month = ANY ('{1,5}'::integer[])) AND (region >= 'usa'::text))
静态分区裁剪不支持LIKE和<>操作符。例如,将示例二的查询,WHERE条件改成region LIKE 'usa',就无法进行分区裁剪。
EXPLAIN
SELECT * FROM sales
WHERE region LIKE 'usa';
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..431.00 rows=1 width=24)
-> Sequence (cost=0.00..431.00 rows=1 width=24)
-> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4)
Partitions selected: 52 (out of 52)
-> Dynamic Seq Scan on sales (dynamic scan id: 1) (cost=0.00..431.00 rows=1 width=24)
Filter: (region ~~ 'usa'::text)动态分区裁剪
概述
在PREPARE-EXECUTE执行方式和分区约束表达式中包含子查询的场景中,查询规划阶段无法确定分区约束,只能在执行阶段,通过外部参数和子查询的结果进行裁剪,这种在执行阶段做分区裁剪的方式称为动态分区裁剪。
动态分区裁剪可以通过EXPLAIN ANALYZE从执行结果中查看裁剪结果。
动态分区裁剪JOIN优化
AnalyticDB PostgreSQL版针对数仓场景下常见的事实表和维度表JOIN,可以将事实表进行分区,通过动态分区裁剪进行JOIN优化。
一般来说,事实表很大,而维度表很小。如果JOIN KEY为事实表的分区键,那么AnalyticDB PostgreSQL版会根据小表的数据,动态生成大表的分区约束,这有助于跳过一些分区文件,从而减少JOIN算子的数据量。
动态分区裁剪的原理:利用JOIN算子内表的数据,动态生成外表(分区表)的分区过滤器,从而跳过不需要的分区。如果没有分区裁剪,分区大表和小表的JOIN可以简化为下图: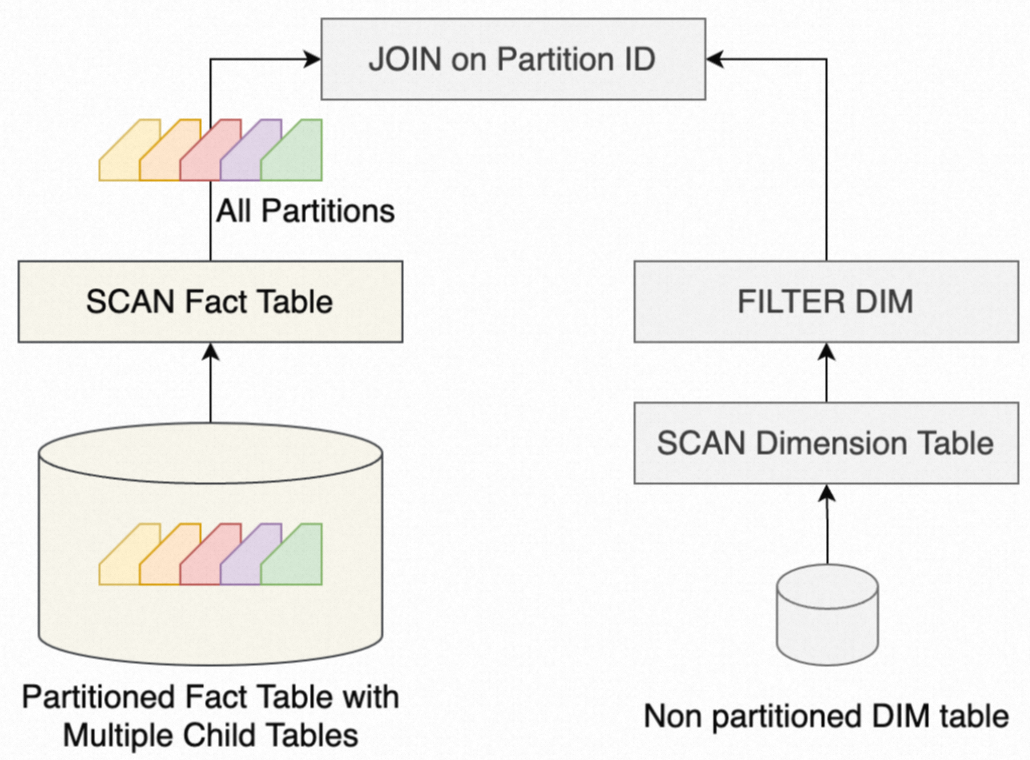
当JOIN KEY为分区键,那么分区表中的所有分区都需要被扫描,然后和小表进行JOIN。而动态分区裁剪会先扫描小表,生成一个分区过滤器,并传给大表的Scan算子,这样只有一部分分区被提取到JOIN算子中,大大减少了数据量。有分区裁剪,分区大表和小表的JOIN简化如下图:
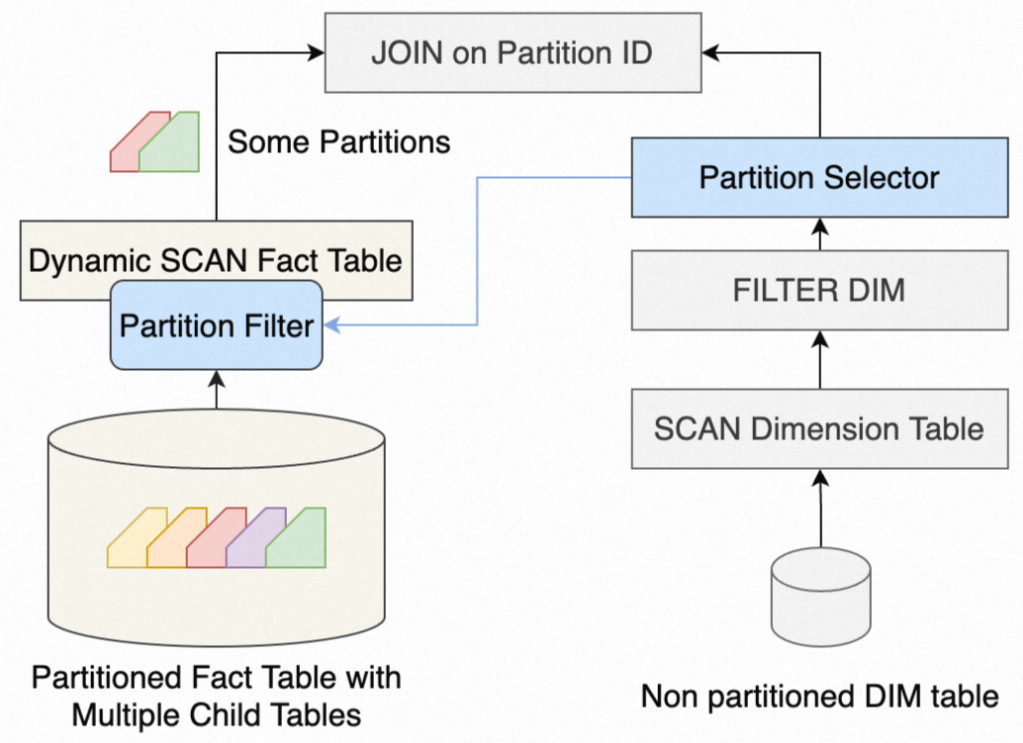
因此,对于大表JOIN小表的典型场景,可以考虑通过将大表改造成分区表,利用动态分区裁剪的特性加速查询。
示例
示例一:WHERE条件包含子查询的动态分区裁剪。
CREATE TABLE t1 (a int, b int); INSERT INTO t1 VALUES (3,3), (5,5); EXPLAIN ANALYZE SELECT * FROM sales WHERE month = ( SELECT MIN(a) FROM t1 );WHERE条件包含子查询,子查询的结果在查询规划阶段未知,需要在执行阶段确定分区约束。根据插入的数据来看,
MIN(a)应该为3,所以sales表应该只读取month=3的4个子分区(Partitions scanned: Avg 4.0)。Gather Motion 3:1 (slice3; segments: 3) (cost=0.00..862.00 rows=1 width=24) (actual time=5.134..5.134 rows=0 loops=1) -> Hash Join (cost=0.00..862.00 rows=1 width=24) (never executed) Hash Cond: (sales.month = (min((min(t1.a))))) -> Sequence (cost=0.00..431.00 rows=1 width=24) (never executed) -> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4) (never executed) Partitions selected: 52 (out of 52) -> Dynamic Seq Scan on sales (dynamic scan id: 1) (cost=0.00..431.00 rows=1 width=24) (never executed) Partitions scanned: Avg 4.0 (out of 52) x 3 workers. Max 4 parts (seg0). -> Hash (cost=100.00..100.00 rows=34 width=4) (actual time=0.821..0.821 rows=1 loops=1) -> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4) (actual time=0.817..0.817 rows=1 loops=1) -> Broadcast Motion 1:3 (slice2) (cost=0.00..431.00 rows=3 width=4) (actual time=0.612..0.612 rows=1 loops=1) -> Aggregate (cost=0.00..431.00 rows=1 width=4) (actual time=1.204..1.205 rows=1 loops=1) -> Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..431.00 rows=1 width=4) (actual time=1.047..1.196 rows=3 loops=1) -> Aggregate (cost=0.00..431.00 rows=1 width=4) (actual time=0.012..0.012 rows=1 loops=1) -> Seq Scan on t1 (cost=0.00..431.00 rows=1 width=4) (actual time=0.005..0.005 rows=2 loops=1)示例二:通过动态分区裁剪进行JOIN优化。
EXPLAIN SELECT * FROM sales JOIN t1 ON sales.month = t1.a WHERE sales.region = 'usa';t1表中只有两条记录(3,3)和(5,5),与sales表的分区键month进行JOIN后,动态分区裁剪应该只扫描month为3和5的分区,再加上region指定为'usa',最终只有两个子分区被扫描(Avg 2.0)。通过EXPLAIN ANALYZE能得到其运行时的执行计划,符合预期。QUERY PLAN --------------------------------------------------------------------------------------------------------------- Gather Motion 3:1 (slice2; segments: 3) (actual time=3.204..16.022 rows=6144 loops=1) -> Hash Join (actual time=2.212..11.938 rows=6144 loops=1) Hash Cond: (sales.month = t1.a) Extra Text: (seg1) Hash chain length 1.0 avg, 1 max, using 2 of 524288 buckets. -> Sequence (actual time=0.317..4.197 rows=6144 loops=1) -> Partition Selector for sales (dynamic scan id: 1) (never executed) Partitions selected: 13 (out of 52) -> Dynamic Seq Scan on sales (dynamic scan id: 1) (actual time=0.311..3.391 rows=6144 loops=1) Filter: (region = 'usa'::text) Partitions scanned: Avg 2.0 (out of 52) x 3 workers. Max 2 parts (seg0). -> Hash (actual time=0.316..0.316 rows=2 loops=1) -> Partition Selector for sales (dynamic scan id: 1) (actual time=0.208..0.310 rows=2 loops=1) -> Broadcast Motion 3:3 (slice1; segments: 3) (actual time=0.008..0.012 rows=2 loops=1) -> Seq Scan on t1 (actual time=0.004..0.004 rows=1 loops=1)
常见问题
Q:如何判断我的查询进行了分区裁剪?
A:可以通过EXPLAIN语句观察执行计划,如果出现
Partition Selector的算子,就说明分区裁剪生效。Q:分区裁剪在ORCA和PG原生优化器上都支持吗?
A:是的,Planner和ORCA都支持动态或静态分区裁剪,只是执行计划稍有区别。
Q:为什么分区裁剪不生效?
A:分区裁剪需要对分区键进行FILTER或者JOIN。对于静态分区裁剪,目前仅支持
=、>、>=、<、<=五种操作符,以及IN列表;对于动态分区裁剪,目前仅支持等值条件。