
MaxCompute具有层次结构,您可以通过了解其结构,为后期项目规划、安全管理等提供思路。本文为您介绍MaxCompute中核心概念的层次结构及简要含义。
MaxCompute核心概念的层次结构如下。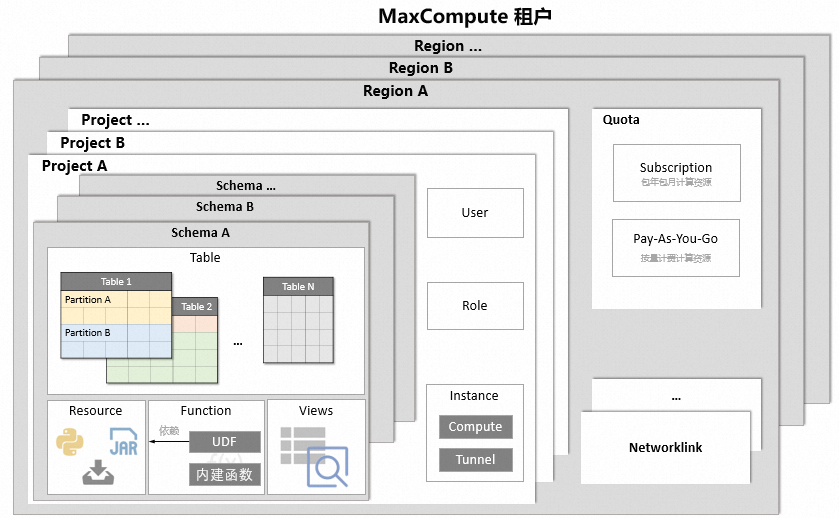
核心概念 | 说明 |
Project(项目) | 项目是MaxCompute的基本组织单元,类似于传统数据库的Database或Schema的概念,是进行多用户隔离和访问控制的主要边界。更多项目信息,请参见项目。 |
Table(表) | 表是MaxCompute的数据存储单元。更多表信息,请参见表。 |
Partition(分区) | 分区Partition是指一张表下,根据分区字段(一个或多个字段的组合)对数据存储进行划分。如果表没有分区,数据是直接放在表所在的目录下。如果表有分区,每个分区对应表下的一个目录,数据是分别存储在不同的分区目录下。更多分区信息,请参见分区。 |
View(视图) | 视图是在表之上建立的虚拟表,它的结构和内容都来自表。一个视图可以对应一个表或多个表。如果您想保留查询结果,但不想创建表占用存储,可以通过视图实现。更多视图信息,请参见视图操作。 |
User(用户) | 用户是MaxCompute安全功能中的概念,MaxCompute支持您通过阿里云账号、RAM用户或RAM角色访问MaxCompute。非MaxCompute项目所有者(Project Owner)的用户必须被加入MaxCompute项目中,且被授予相应的权限,才能操作MaxCompute项目中的数据、作业、资源及函数。更多用户管理信息,请参见用户规划与管理。 |
Role(角色) | 角色是MaxCompute安全功能中的概念,可以理解为拥有相同权限的用户的集合。多个用户可以同时存在于一个角色下,一个用户也可以隶属于多个角色。给角色授权后,该角色下的所有用户拥有相同的权限。更多角色管理信息,请参见角色规划。 |
Resource(资源) | 资源是MaxCompute中特有的概念。当您使用MaxCompute的自定义函数(UDF)或MapReduce功能时,需要依赖资源来完成。更多资源信息,请参见资源。 |
Function(函数) | MaxCompute提供函数功能,包括内建函数和UDF。更多函数信息,请参见函数。 |
Instance(实例) | 即实际运行作业的一个具体实例,类同Hadoop中Job的概念。详情请参见任务实例。 |
Quota(配额) | 配额是MaxCompute的计算资源池,提供作业运行所需计算资源。更多配额信息,请参见配额。 |
Networklink(网络连接) | 当您使用外部表、UDF或湖仓一体功能时,MaxCompute默认未建立与外网或VPC网络间的网络连接,您需要开通网络连接以访问外网或VPC中的目标服务(例如HBase、RDS、Hadoop等)。更多开通网络连接信息,请参见网络开通流程。 |
Schema | MaxCompute支持Schema,在Project之下对Table、Resource、Function进行归类。更多Schema信息,请参见Schema操作。 |
通常MaxCompute的各层级概念的组织模式如下:
租户代表组织,以企业为例,一个企业可以在不同地域开通MaxCompute按量付费服务或预先购买包年包月计算资源(Quota)。
企业内的各个部门在开通服务的地域内创建和管理自己的项目(Project),用于存储该部门的数据。项目内可以存储多种类型对象,例如表(Table)、资源(Resource)、函数(Function)和实例(Instance)等。如果您有需要,也可以通过创建Schema,在项目之下进一步对上述对象进行归类,详情请参见Schema操作。各部门可以在项目内通过用户与角色的管控,对项目内的各类数据进行权限控制。
项目产生的存储费用以项目粒度出账。如果您使用按量付费计算资源,则查询费用计入运行查询的项目。如果您使用包年包月计算资源,则不再另收查询费用。
组织模式示例如下图所示: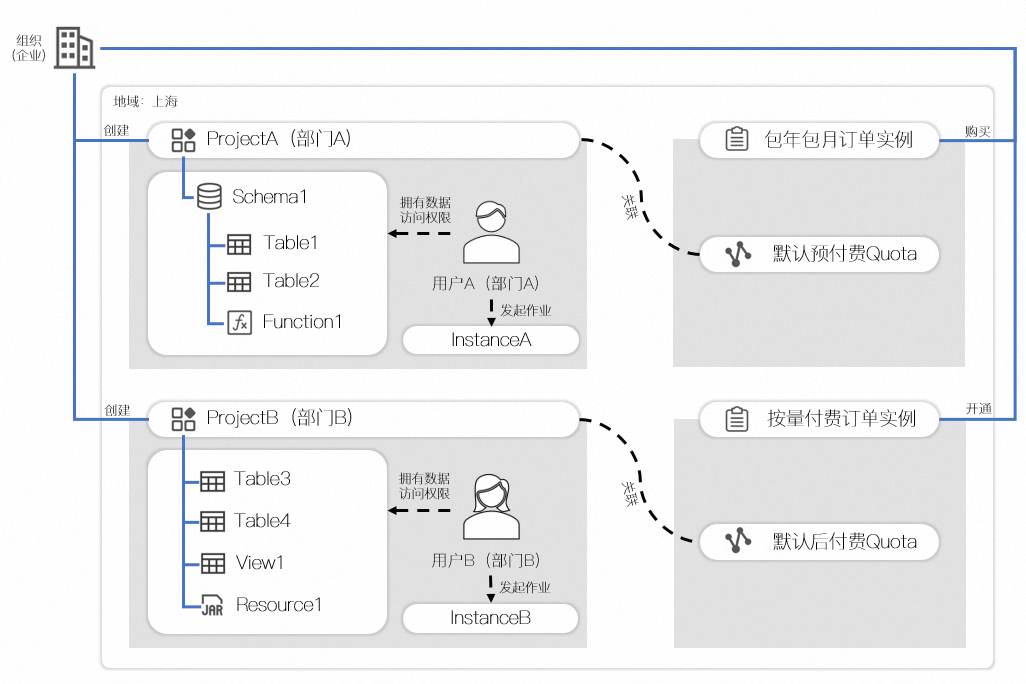
在此示例中,某企业在上海地域开通了按量付费服务(默认后付费Quota),并且购买了包年包月规格计算资源(默认预付费Quota)。
部门A创建了项目A,项目A包含一个Schema1,Schema内存储了表1、表2、以及函数1,关联了默认预付费Quota,部门A的用户A被授予了项目A数据的访问权限,并且可以发起作业,所有作业默认使用的计算资源为默认预付费Quota。
部门B创建了项目B,项目B没有开启按Schema存储,所以项目下直接存储了表3、表4、视图1和资源1,关联了默认后付费Quota,部门B的用户B被授予了项目B数据的访问权限,并且可以发起作业,所有作业默认使用的计算资源为默认后付费Quota。