
本文介绍如何通过MaxCompute实现GitHub近实时数据同步以及增全量数据一体化分析。
方案概述
基于GitHub Archive公开数据集,通过DataWorks数据集成、FlinkCDC和Flink等多种实时数据写入方式,将GitHub中的项目、行为等超过十种事件类型的数据实时采集至MaxCompute进行增全量更新。借助MCQA 2.0的资源隔离能力,同时构建批处理资源组(QuotaA组)与交互式资源组(QuotaB组),从而实现MaxCompute中增全量数据的写入与更新,并同时进行交互式查询分析。此外,通过使用TopConsole和DataWorks Notebook,从开发者、项目和编程语言等多个维度,对GitHub实时数据的变化情况进行深入分析与挖掘。
方案架构与优势
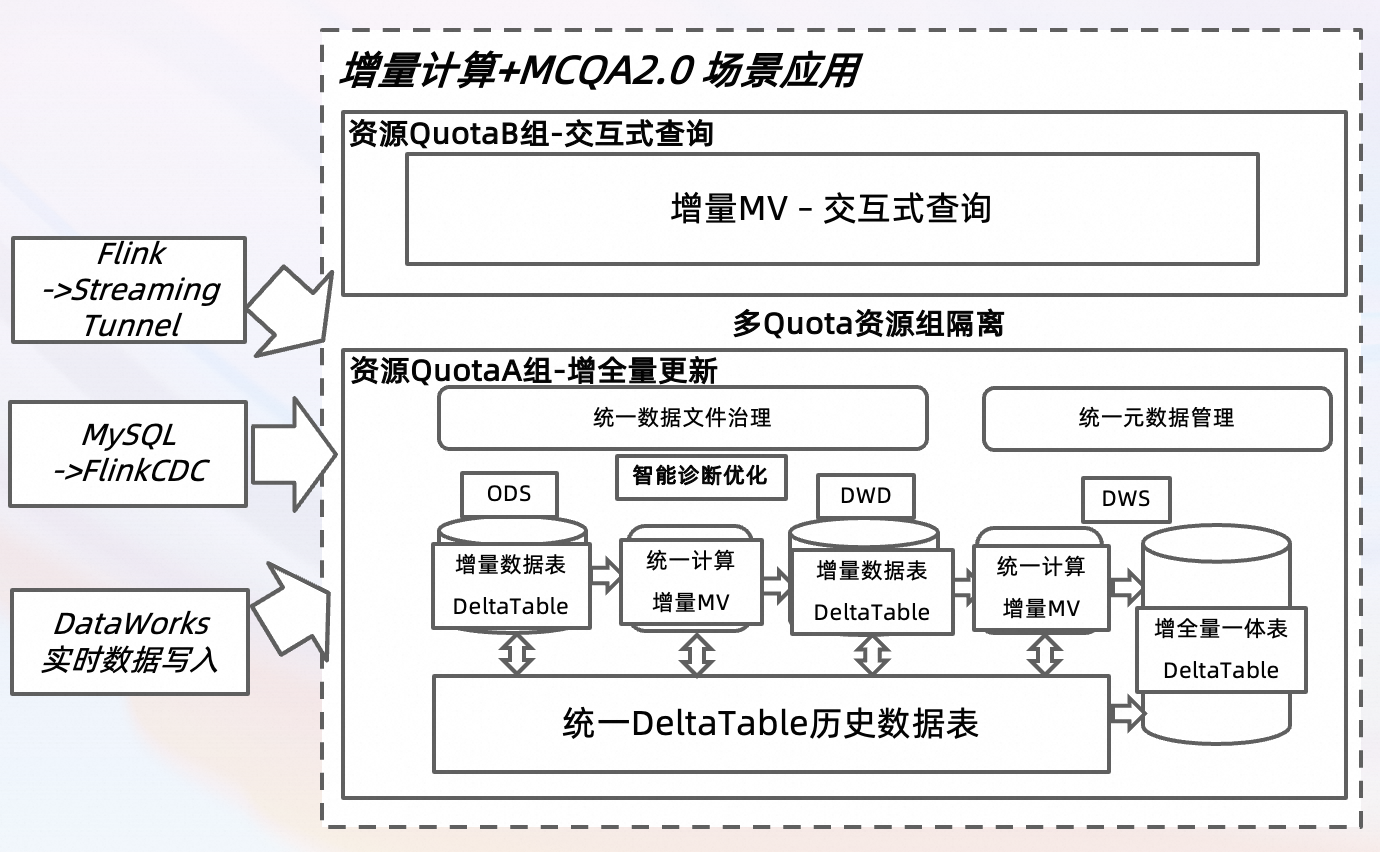
以上图示基于典型数据分析场景设计,可以满足当日近实时数据的写入以及历史离线数据的更新与查询分析场景。
实现增全量数据的统一校正(包括数据聚合、去重和反作弊等),定期将全量数据回写至DWD,并对应地更新DWS和ADS的增量MV。通过FlinkCDC和DataWorks实时数据集成,将数据写入Delta Table的增量数据表,实现增量查询与更新。
实现交互式数据查询(DWS/ADS层),支持增量物化视图(MV)在DWS和ADS中自动刷新,以确保数据的时效性。同时,与TopConsole和DataWorks对接,以便进行数据查询和展示。
借助MCQA 2.0查询加速引擎,在资源隔离架构下配置不同的Quota组,以分别支持增量数据计算和交互式查询分析场景。
近实时数仓-Delta Table增量表格式
针对分钟级或者小时级的近实时数据处理叠加海量数据批处理的场景,MaxCompute基于Delta Table的统一表格式特性,提供近实时的增全量一体的数据存储和计算解决方案,支持分钟级数据实时Upsert写入和TimeTravel数据回溯等能力。其核心特性包括:
支持近实时写入,并且能够实现Checkpoint间隔达到分钟级别以内。
支持SQL近实时查询(Incremental Query),且在完成写入后,可在分钟级别内进行查询。
通过StorageService、AutoCompaction和AutoSorting功能,实现对数据文件的自动管理。
近实时数仓-增量计算&增量物化视图(Incremental MV)
MaxCompute的增量计算结合了CDC和Stream增量查询能力,使用户可以通过自定义SQL来构建自己的增量数据处理链路。增量物化视图(MV)可有效地构建增量计算模型,用户只需使用声明式SQL表达预期的数据结果,便可通过配置不同的刷新参数来指定刷新频率或数据新鲜度,后台引擎将自动进行增量刷新和内部优化,从而实现近实时数据分析Pipeline。其主要核心特性包括:
声明式SQL。
增量与全量数据一体化,支持统一的SQL、存储和计算。
增量物化视图(MV)支持智能Pipeline编排 。
增量CDC应用,支持周期性任务及流处理特性。
数据新鲜度,提供实时或自定义的增量数据刷新。公式为:
MV(T1) = delta(T0, T1) + MV(T0)。
近实时数仓-MCQA2.0查询加速
MaxCompute的MCQA2.0查询加速引擎旨在满足对性能、隔离性以及稳定性有更高要求的业务需求。它构建类似Virtual Warehouse的资源隔离管理引擎,从而显著提升了交互式查询的性能。支持租户级独占计算资源,使用多线程Pipeline执行,以充分利用精准独享的计算资源管理。此外,还支持全链路的Cache能力,全类型的SQL作业、屏显作业以及DDL、DML作业等特性。
支持单租户环境下构建多Quota组进行资源隔离,并支持对Quota组进行交互式查询。
支持分时资源的分组管理。
交互式查询性能加速,与上一版本相比,性能提升1倍。
操作视频
操作步骤
步骤一:MaxCompute项目准备
步骤 | 操作 | 预期结果 |
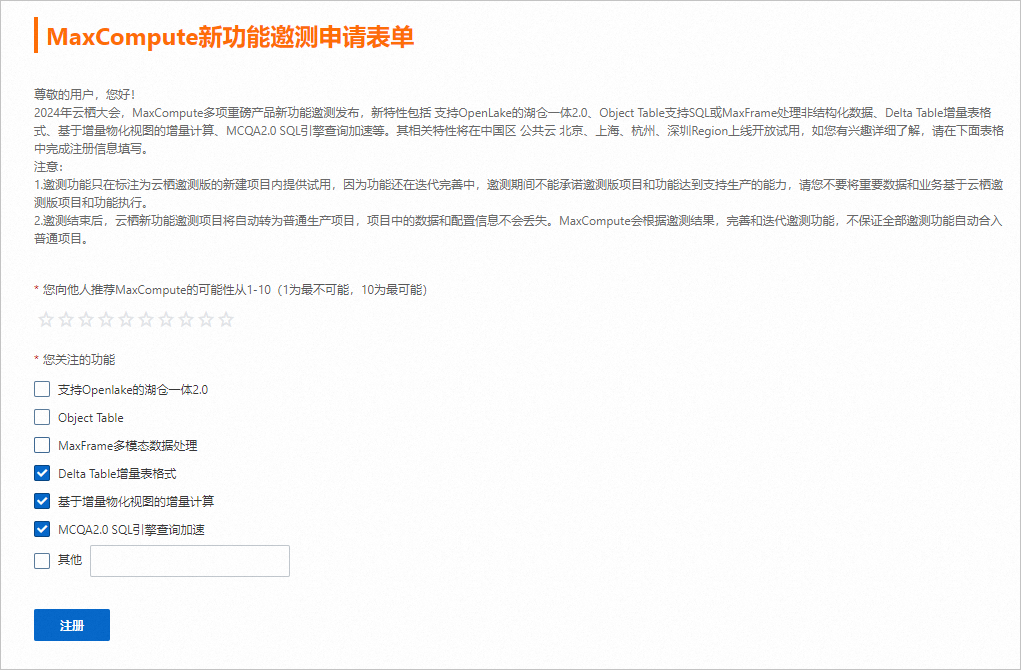
Step 0 注册MaxCompute新功能邀测申请表单 |
| 开通MaxCompute新功能。 |
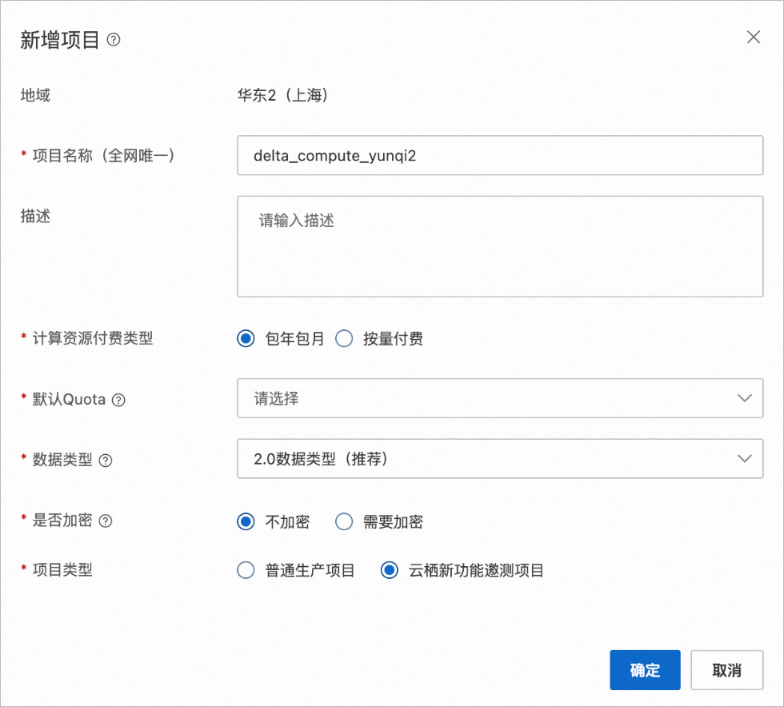
Step 1 初始化MaxCompute新项目 |
|
|
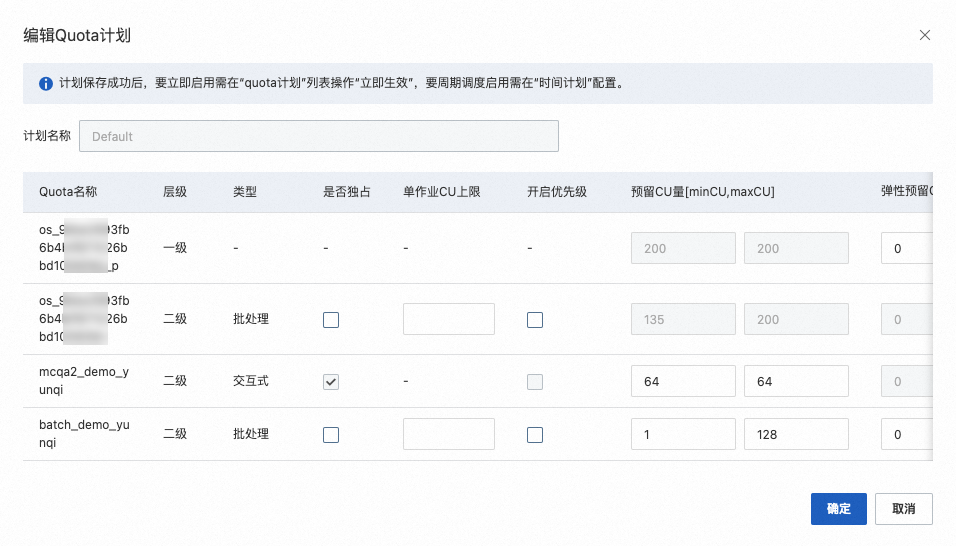
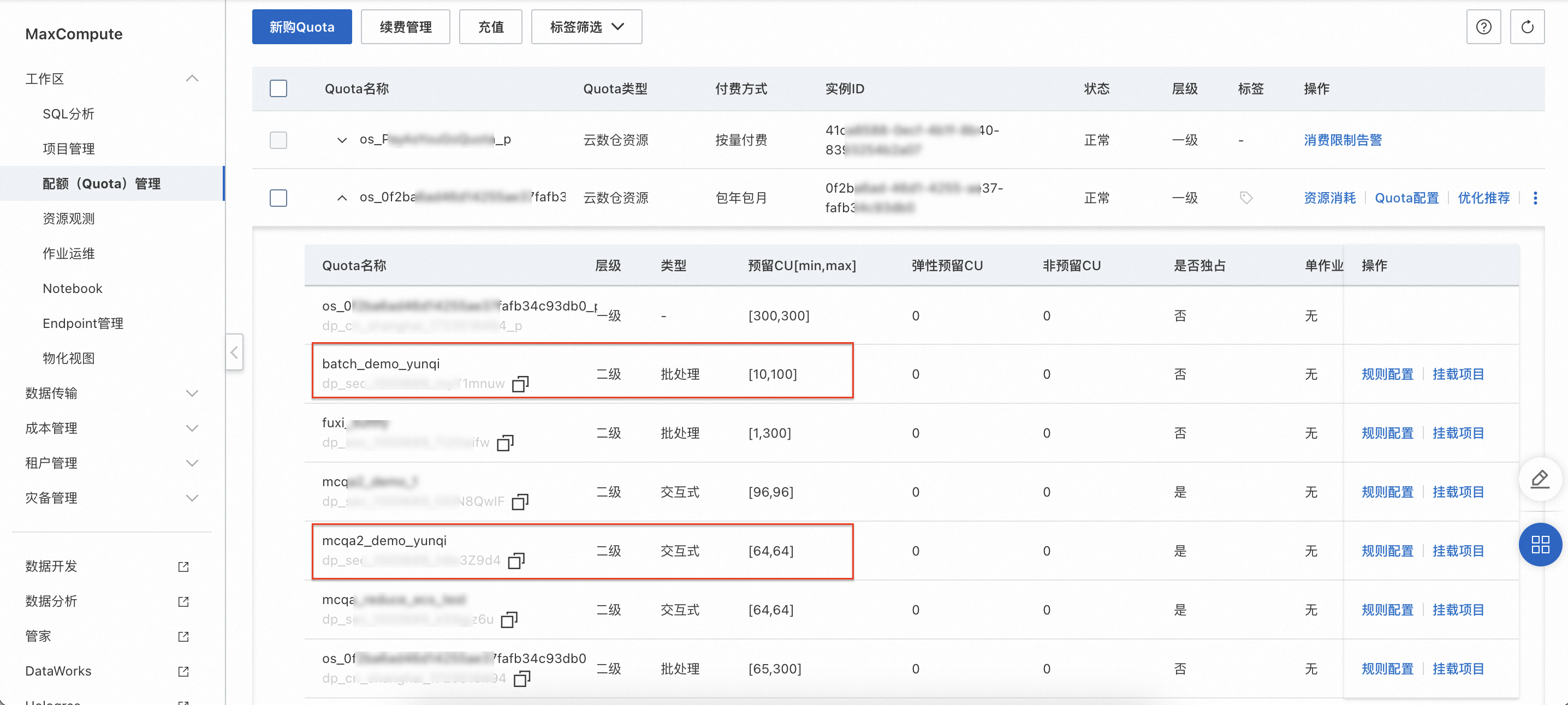
Step 2 配额(Quota)管理上新购Quota |
| 在配额(Quota)管理页面,确认批处理Quota组和交互式Quota组已成功创建。 |
Step 3 新建MaxCompute Delta Table增量表 | 在SQL分析页面,执行如下示例命令,创建2个MaxCompute内部表:
| 在SQL分析页面,选择项目
|


步骤二:实时增全量数据写入
通过FlinkCDC或DataWorks数据集成能力获取基于GitHub Archive公开实时数据集。
您可以按需选择以下任意一种方式写入数据。
Flink CDC
步骤 | 操作 | 预期结果 |
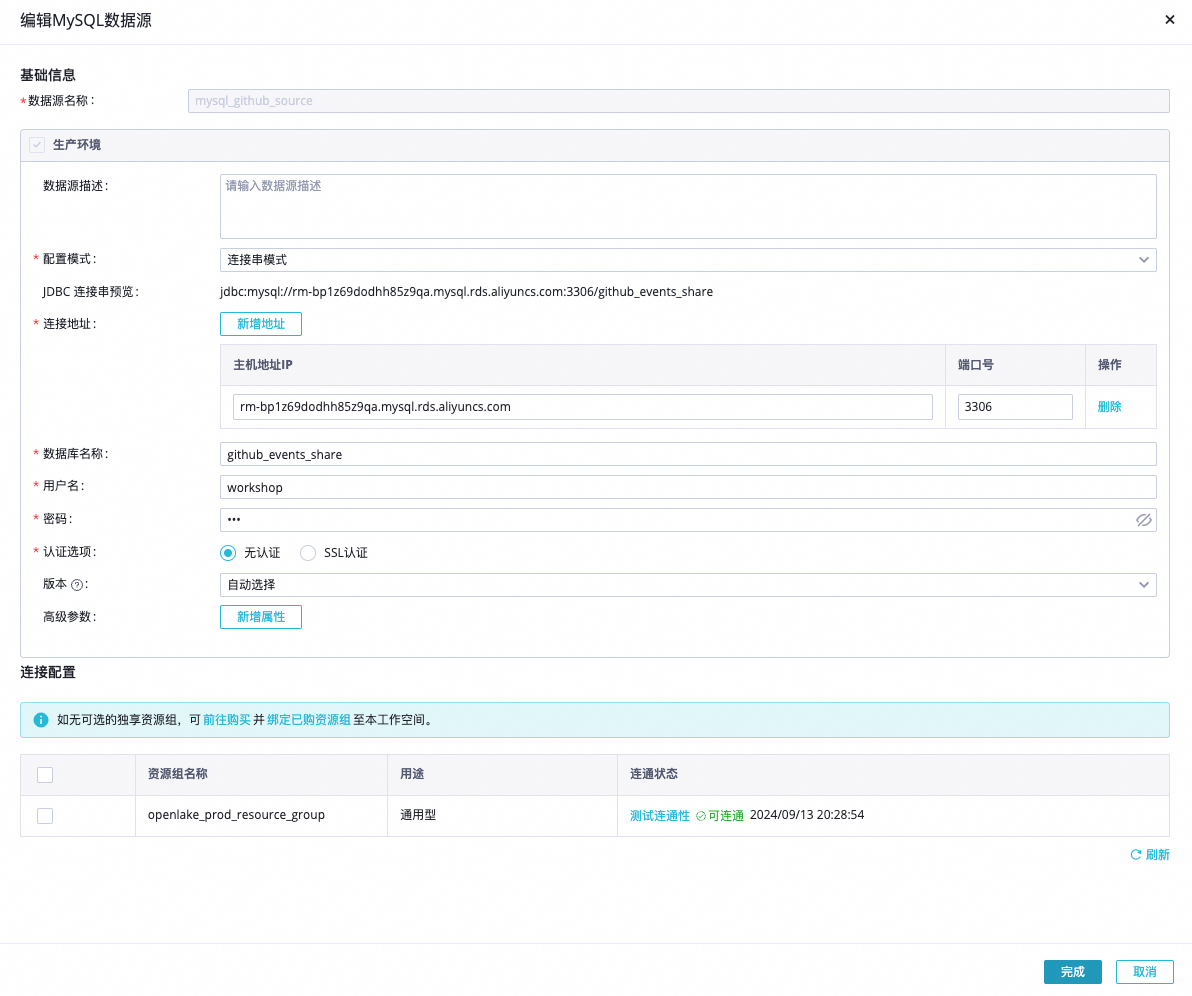
Step 1 实时MySQL数据源对接与验证 | MySQL数据源连接信息格式如下。 说明 请确保MySQL数据源可以通过公网访问,如无法通过公网访问,可以配置公网NAT网关。 | 确认公开Github数据源可用。 |
Step 2 通过Flink CDC写入数据 | 实时GitHub Event数据通过FlinkCDC实时数据写入MaxCompute Delta Table增量表,更多信息,请参见利用Flink CDC实现数据同步至Delta Table。
| 查看MaxCompute的yunqi_github_events_odps_cdc数据表的数据变化。 |
DataWorks数据集成
步骤 | 操作 | 预期结果 |
Step 1 实时MySQL数据源对接与验证 | MySQL数据源连接信息格式如下。 说明 请确保MySQL数据源可以通过公网访问,如无法通过公网访问,可以配置公网NAT网关。 | 确认公开Github数据源可用。 |
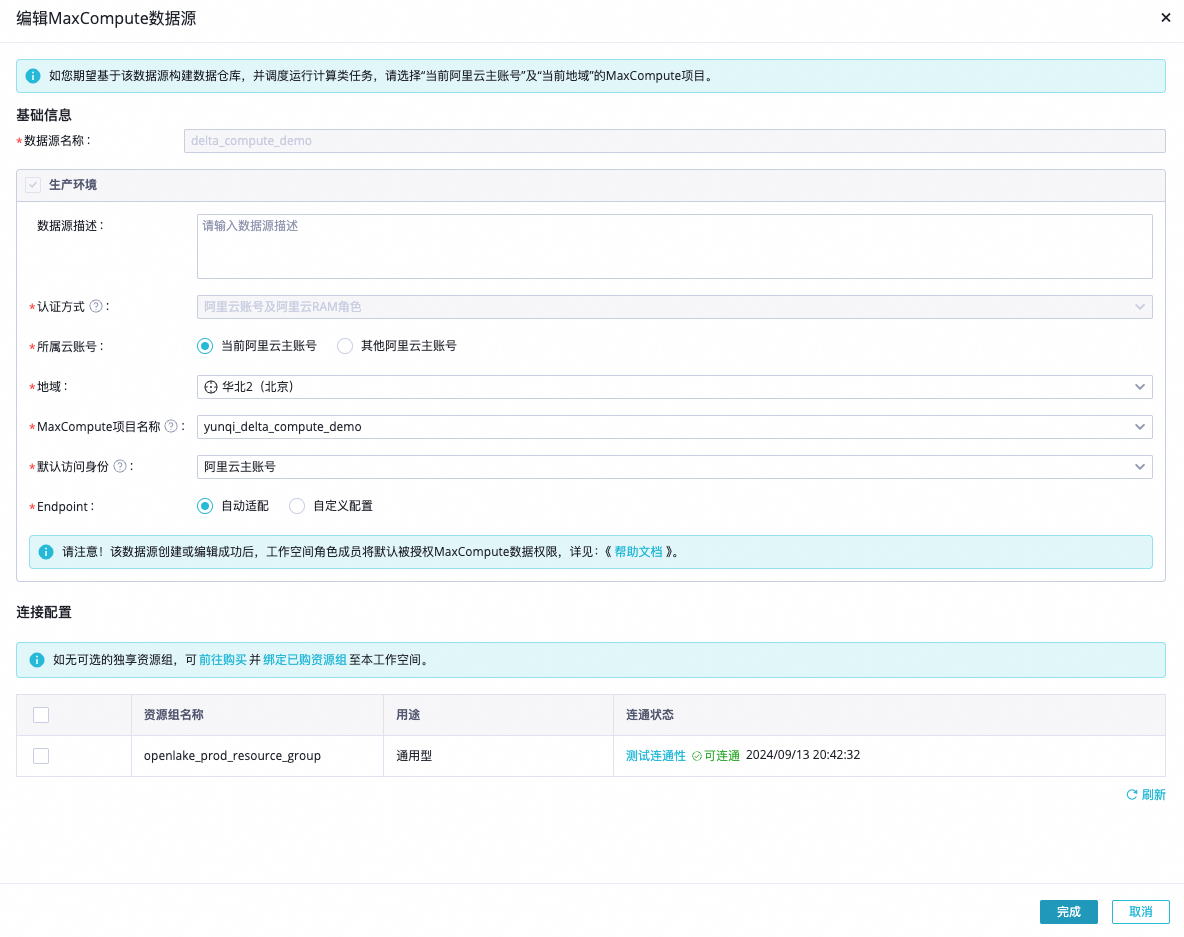
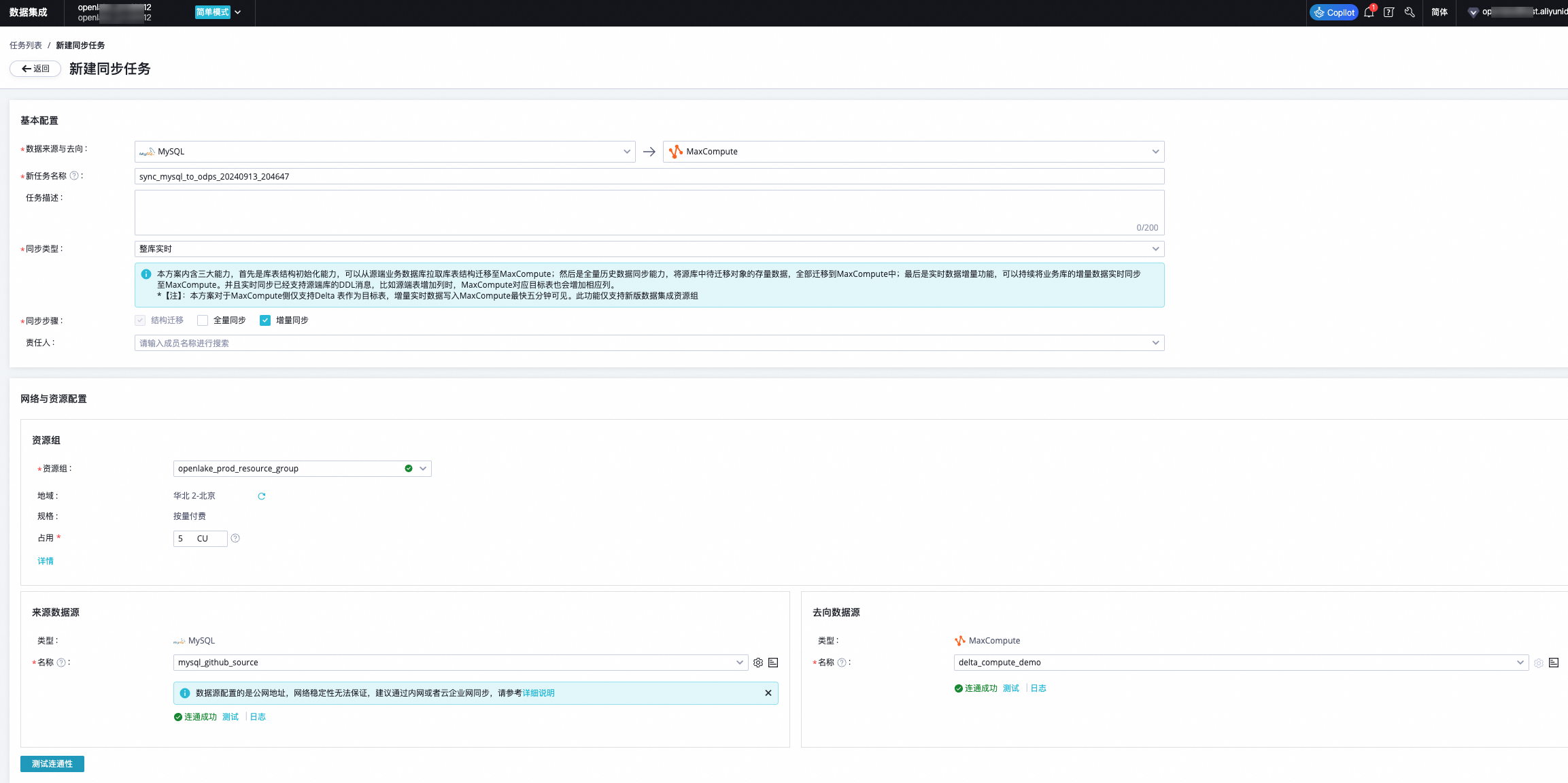
Step 2 配置DataWorks实时数据源 | 实时GitHub Event数据通过DataWorks数据集成实时数据写入MaxCompute Delta Table增量表(实时数据源)。
| 确认来源和去向数据源联通正常。 |
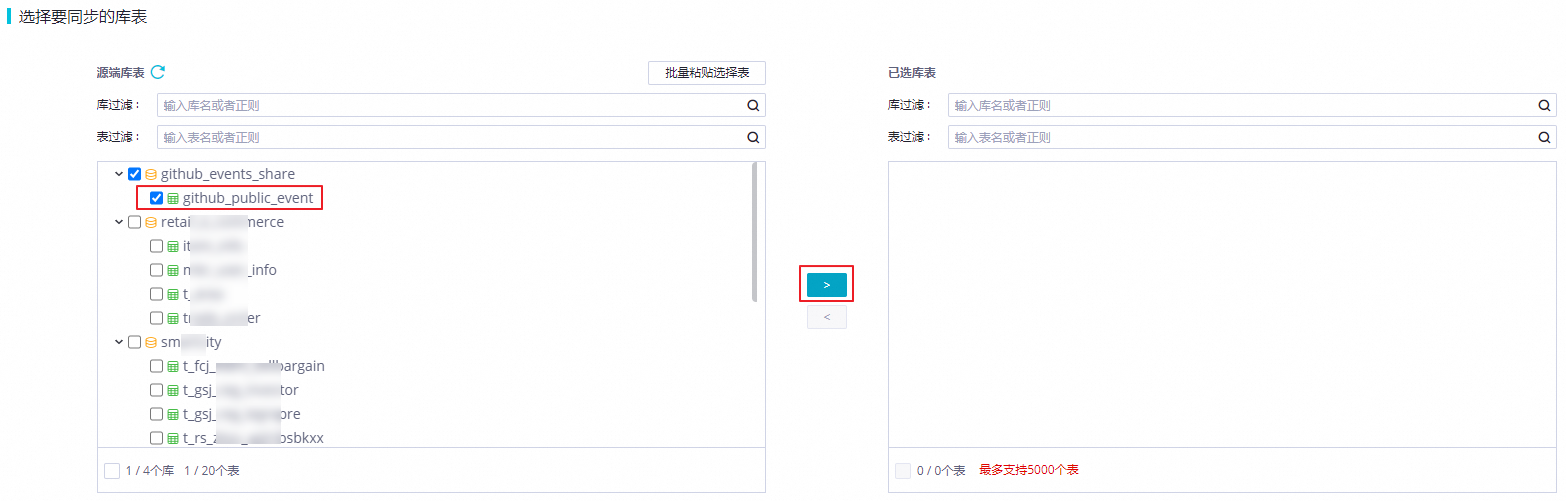
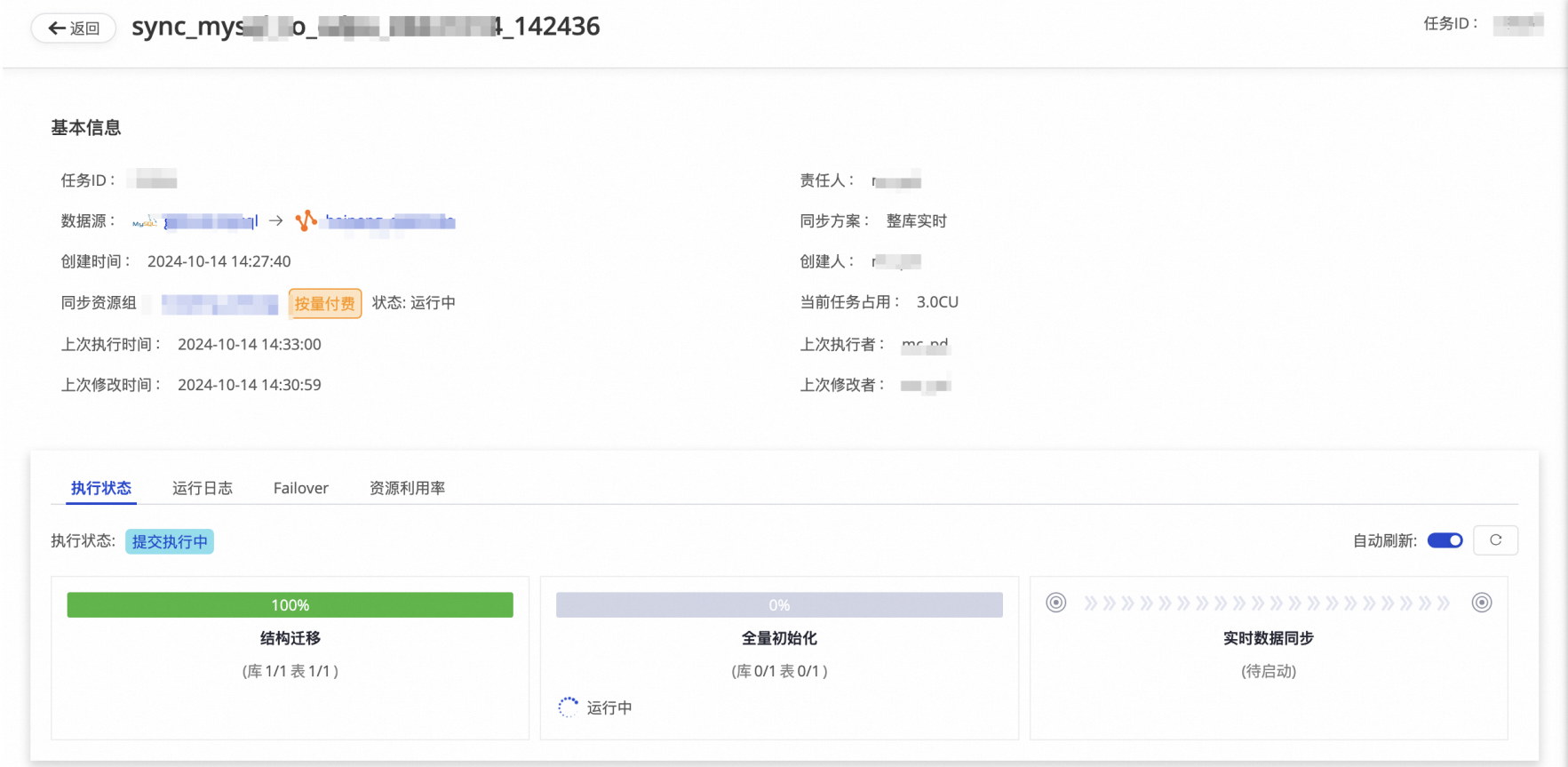
Step 3 DataWorks实时任务同步 | 实时GitHub Event数据通过DataWorks数据集成实时数据写入MaxCompute Delta Table增量表。
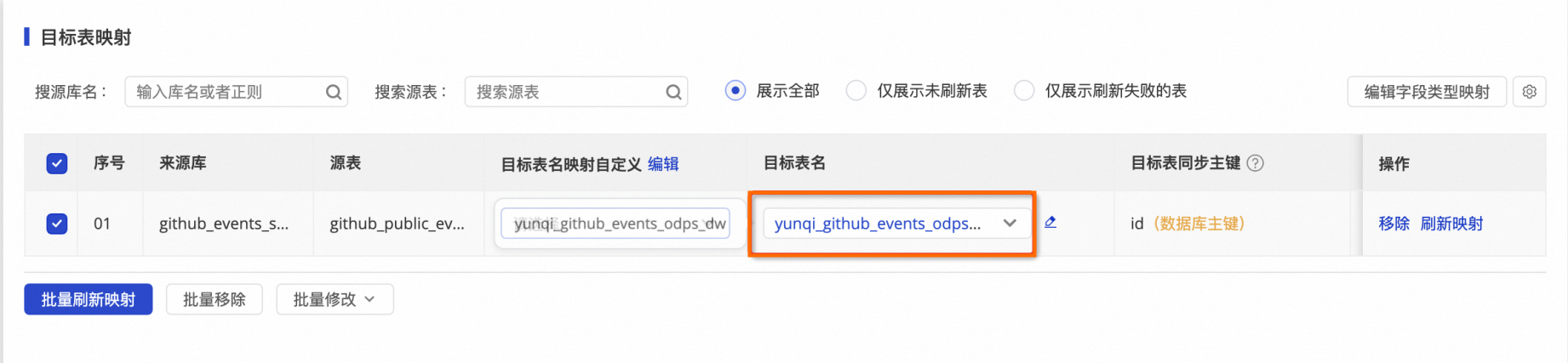
| 查看MaxCompute的yunqi_github_events_odps_dw数据表的数据变化。 |

步骤三:近实时查询分析和增量计算
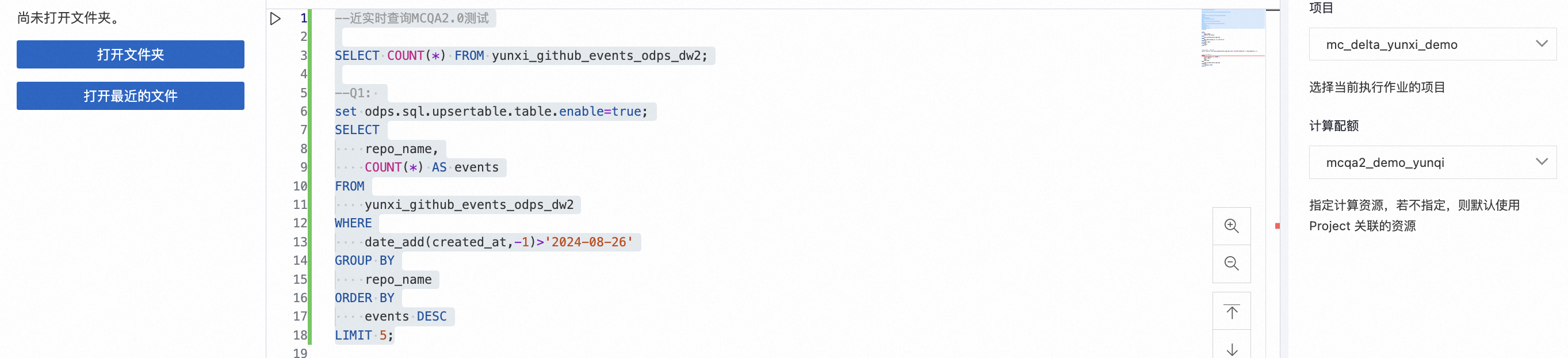
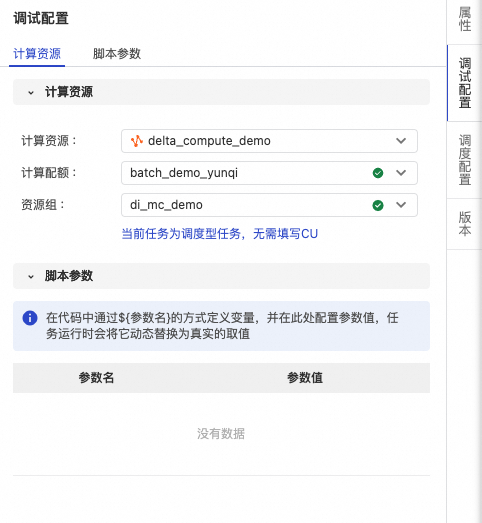
近实时数据分析:使用交互式Quota组-mcqa2_demo_yunqi(64CU)在MaxCompute TopConsole SQL数据分析。
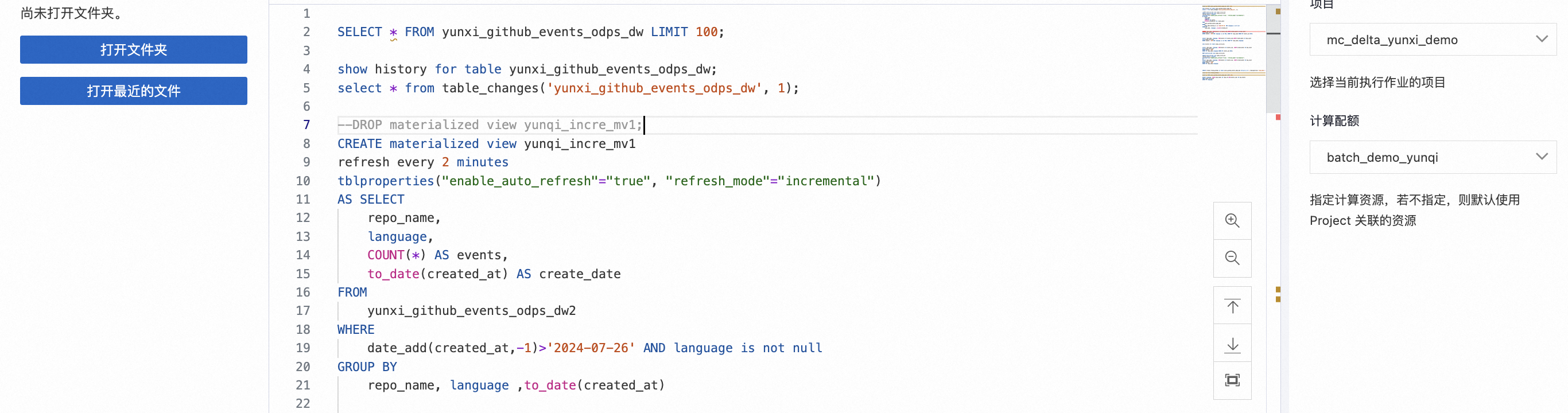
增量MV-自动化动态表:使用批处理Quota组-batch_demo_yunqi(128CU)在MaxCompute TopConsole进行动态表增量计算。
增量计算-CDC/Stream/周期性Tasks:使用批处理Quota组-batch_demo_yunqi在MaxCompute TopConsole进行自定义增量计算。
步骤 | 操作 | 预期结果 |
Step 1 使用交互式资源组-近实时数据分析 |
具体SQL分析步骤如下:
| 观察查询SQL结果。 |
Step 2 使用批处理资源组-增量计算-增量物化视图MV聚合查询 |
具体SQL分析步骤如下:
| 观察查询SQL结果。 |
Step 3 使用批处理资源组-增量计算-Stream&Task应用 |
具体SQL分析步骤如下:
| 观察查询SQL结果。 |
步骤四:多Quota资源配置和交互式查询加速
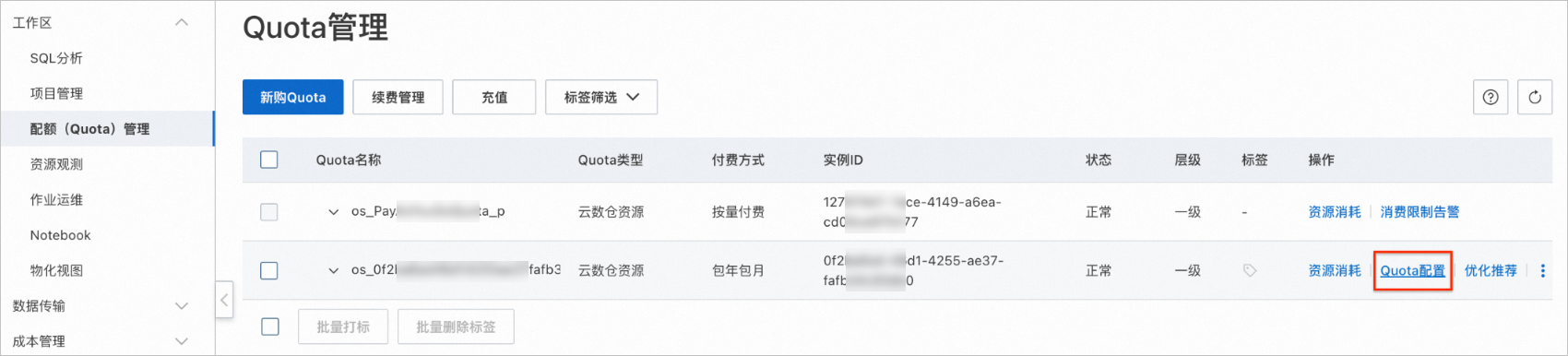
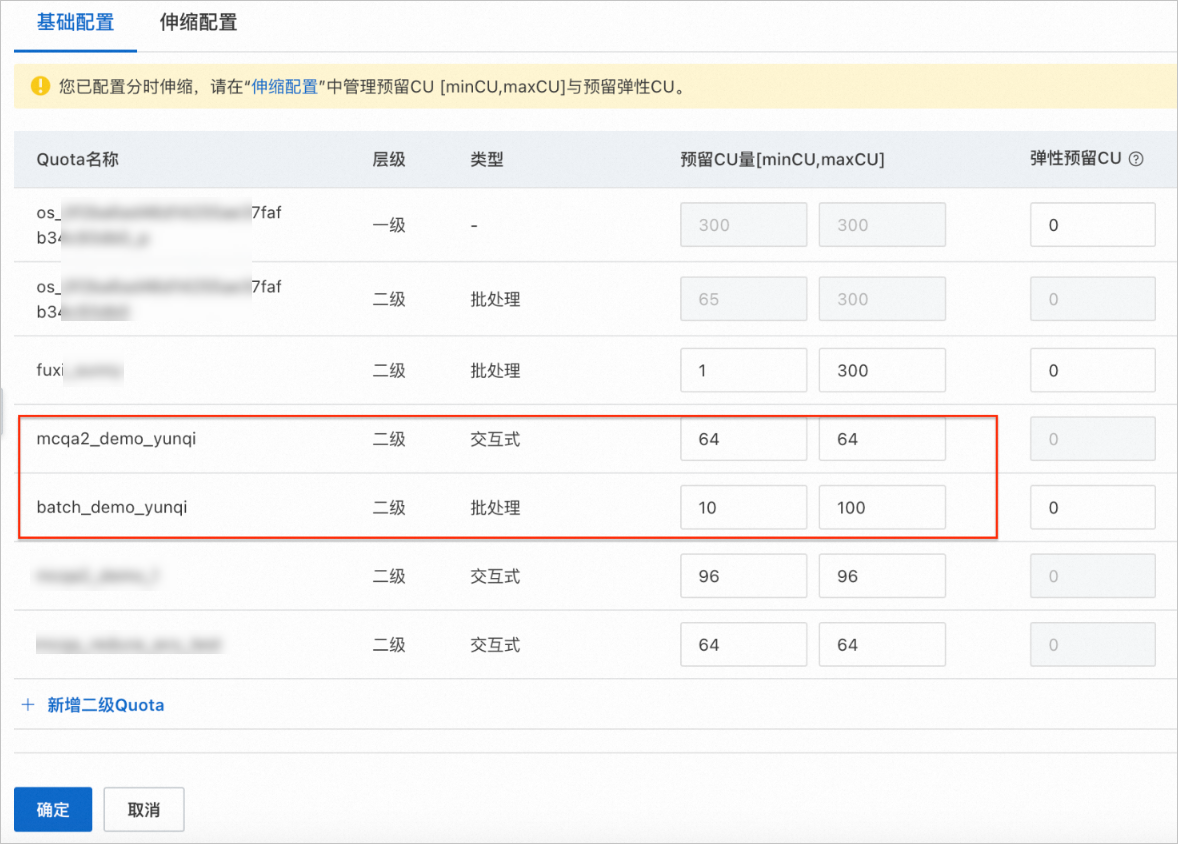
交互式Quota组扩容(64CU->96CU),在新规格的Quota组情况下,在MaxCompute TopConsole进行交互式查询, 观测查询加速性能提升。
步骤 | 操作 | 预期结果 |
Step 1 Quota扩容 |
| 目标Quota组资源扩容成功。 |
Step 2 查询对比分析与性能优化 |
具体SQL分析步骤如下:
| 观察查询SQL结果。 |
步骤五(可选):增全量一体交互式分析
使用DataWorks IDE模块-实现增全量一体的近实时数据分析。
步骤 | 操作 | 预期结果 |
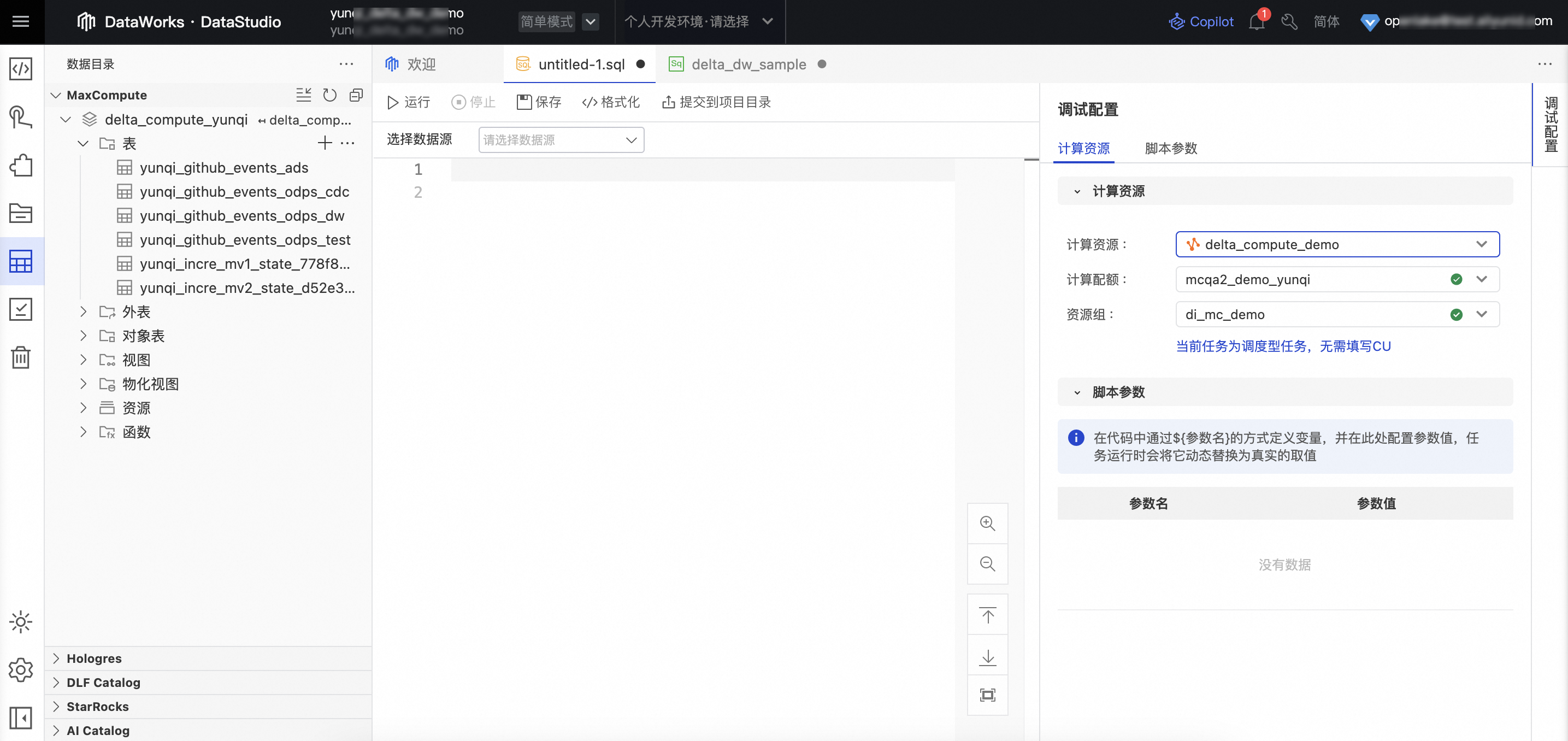
Step 1 在DataWorks IDE 数据开发模块配置MaxCompute计算资源 |
| 无 |
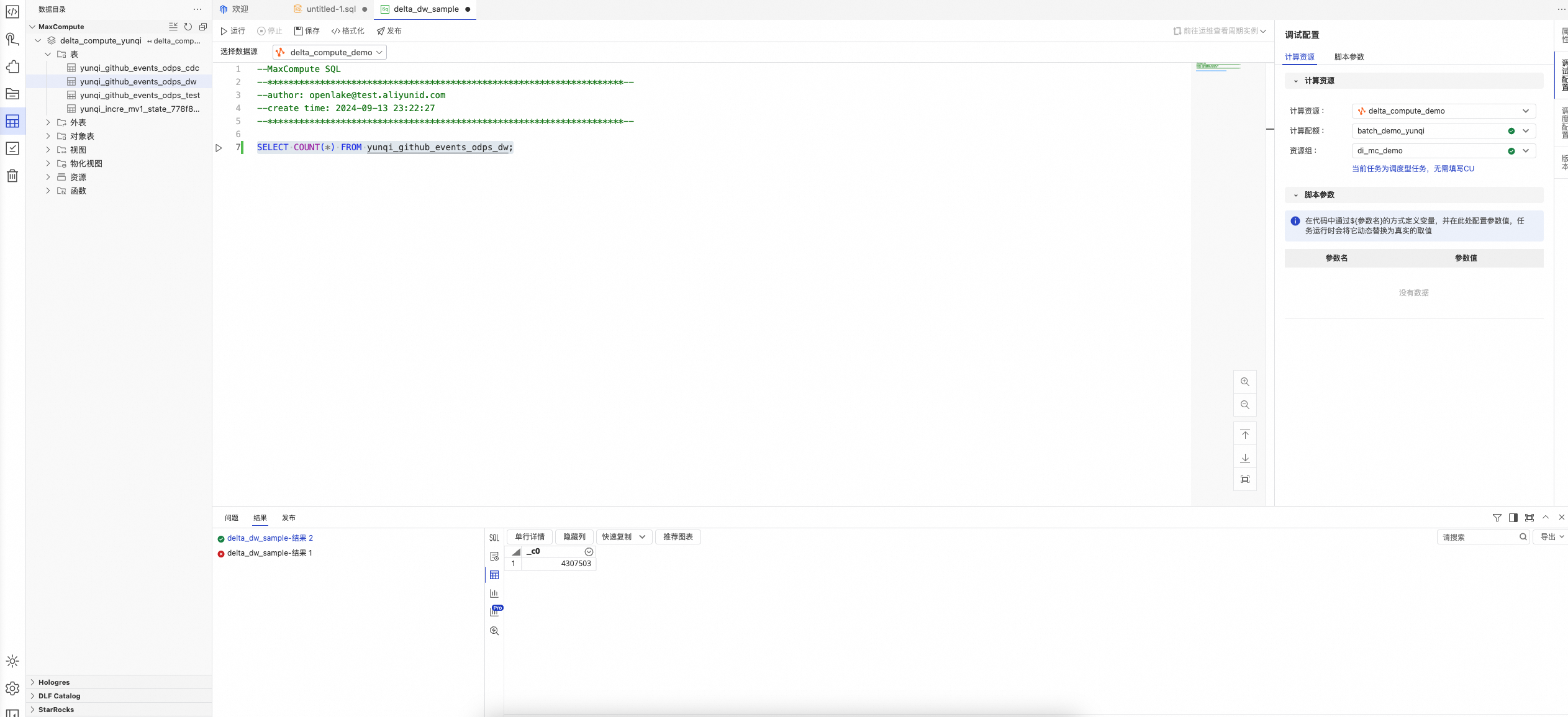
Step 2 在DataWorks IDE数据开发平台进行数据分析 | 具体SQL分析步骤如下:
| 观察查询SQL结果。 |

总结
本次示例展示了MaxCompute全新构建的基于近实时数仓产品特性的产品方案实践。MaxCompute提供增全量一体的数据处理和近实时查询能力,从数据存储层(Delta Table统一表格式)、计算层(增量计算:CDC/Task/增量MV)、加速层(MCQA2.0查询加速引擎)等三层架构来实现MaxCompute近线计算能力的全面升级。通过此次典型的Demo创建,您能够深度了解如何在MaxCompute产品上构建完备的近实时以及增全量计算的计算任务,简化数据全生命周期的计算优化工作。