
本文为您介绍如何使用DLC提供的基于AIMaster的容错监控功能。
背景信息
深度学习广泛使用,随着模型和数据规模增大,常采用分布式方式运行。当任务实例增多时,软件栈和硬件环境可能出现异常,导致任务停止。
为保障大规模分布式深度学习任务稳定运行,DLC提供了基于AIMaster的容错监控功能。AIMaster是任务级别组件,开启后会启动一个AIMaster实例与任务其他实例一起运行,起到任务监控、容错判断和资源控制的作用。
使用限制
目前AIMaster支持以下框架:PyTorch、MPI、TensorFlow、ElasticBatch。
步骤一:配置容错监控参数
以下是容错监控功能的全量参数说明,您可以参考常用参数配置示例,提前规划任务的容错监控内容。后续开启容错监控功能时,可以根据需求设置到容错监控的其他配置处。
全量参数说明
配置分类 | 功能介绍 | 配置参数 | 参数说明 | 默认值 |
通用配置 | 任务运行类型 | --job-execution-mode | 配置任务运行类型,取值如下:
不同任务类型容错行为不同。对于可重试错误:
| Sync |
任务重启设置 | --enable-job-restart | 在满足容错条件或检测到运行时异常时,是否允许任务重启。取值如下:
| False | |
--max-num-of-job-restart | 配置任务最大重启次数。超过最大重启次数后,会将任务标记为失败。 | 3 | ||
运行时配置 说明 针对没有实例运行失败的场景。 | 任务Hang(挂起)异常检测 | --enable-job-hang-detection | 是否开启任务运行时的Hang异常检测,只支持同步任务。取值如下:
| False |
--job-hang-interval | 配置任务暂停执行的持续时长,正整数,单位为秒。 当任务停止时长超过该值时,则将任务标记为异常,并触发任务重启。 | 1800 | ||
| 是否开启C4D(Calibrating Collective Communication over Converged ethernet - Diagnosis)检测功能,用于快速诊断并定位任务执行过程中出现的慢速节点和导致任务Hang(挂起)的故障节点。 说明 该参数仅在同时开启 | False | ||
任务退出时Hang(挂起)异常检测 | --enable-job-exit-hang-detection | 是否开启任务快要结束退出时的Hang异常检测,只支持同步任务。取值如下:
| False | |
--job-exit-hang-interval | 配置任务退出时停止执行的持续时长,正整数,单位为秒。 当任务退出时长超过该值时,则将任务标记为异常,并触发任务重启。 | 600 | ||
容错配置 说明 针对有实例运行失败的场景。 | 容错策略 | --fault-tolerant-policy | 容错策略参数取值如下:
| ExitCodeAndErrorMsg |
相同错误最大允许出现次数 | --max-num-of-same-error | 配置单个实例上同一错误允许出现的最大次数。 当错误出现次数超过该值时,直接将任务标记为失败。 | 10 | |
最大容错率 | --max-tolerated-failure-rate | 设置最大容错率,当失败实例的比例超过该值时,job直接标记失败。 默认值-1表示该功能默认不开启。示例:设置0.3表示30%以上的worker出现错误后,job可以直接标记为失败。 | -1 |
常用参数配置示例
针对不同的训练任务,常用的容错监控参数配置示例如下。
同步训练任务(常见于PyTorch任务)
当实例异常且满足容错条件时,重启任务。
--job-execution-mode=Sync --enable-job-restart=True --max-num-of-job-restart=3 --fault-tolerant-policy=ExitCodeAndErrorMsg异步训练任务(常见于TensorFlow任务)
对于可重试的错误,重启异常的Worker实例。PS或Chief实例出错时,默认不重启任务,如需重启可设置--enable-job-restart=True。
--job-execution-mode=Async --fault-tolerant-policy=OnFailure离线推理任务(常见于ElasticBatch任务)
实例之间无依赖关系,相当于异步任务。当实例运行异常时,只会重启异常的实例。
--job-execution-mode=Async --fault-tolerant-policy=OnFailure
步骤二:开启容错监控功能
您可以在提交DLC训练任务时,通过控制台或SDK的方式开启容错监控功能。
通过控制台开启容错监控功能
在控制台提交DLC训练任务时,您可以在容错与诊断区域,打开自动容错开关,并配置额外参数,详情请参见创建训练任务。这样DLC任务在运行过程中会额外启动一个AIMaster角色,进行全程监控,并在遇到错误时进行容错处理。

其中:
支持在其他配置文本框中配置额外参数,参数配置说明请参见步骤一:配置容错监控参数。
启用任务挂起检测后,可开启C4D检测功能。C4D(Calibrating Collective Communication over Converged ethernet - Diagnosis)是阿里云自研的,专门针对大模型训练中任务Slow(慢)或任务Hang(挂起)的问题诊断工具,帮助定位大模型训练中的问题。详情请参见使用C4D。
说明C4D依赖阿里云自研高性能集合通信库ACCL,请确保ACCL已安装,详情请参见ACCL:阿里云高性能集合通信库。
目前,DLC任务选择灵骏智算资源时,可以使用C4D检测功能。
启动任务挂起检测后,可以使用任务函数调用栈分析工具来帮助定位任务具体Hang(挂起)在了哪一行代码,需要针对“任务挂起(Hang)检测阈值”做专门的配置,详情请参见“使用函数调用栈快照分析工具”
通过DLC SDK开启容错监控功能
使用GO SDK
通过GO SDK提交任务时打开容错开关。
createJobRequest := &client.CreateJobRequest{} settings := &client.JobSettings{ EnableErrorMonitoringInAIMaster: tea.Bool(true), ErrorMonitoringArgs: tea.String("--job-execution-mode=Sync --enable-job-restart=True --enable-job-hang-detection=True --job-hang-interval=3600"), } createJobRequest.SetSettings(settings)其中:
EnableErrorMonitoringInAIMaster:表示是否打开容错监控功能。
ErrorMonitoringArgs:表示容错监控额外参数。
使用Python SDK
通过Python SDK提交任务时打开容错开关。
from alibabacloud_pai_dlc20201203.models import CreateJobRequest, JobSettings settings = JobSettings( enable_error_monitoring_in_aimaster = True, error_monitoring_args = "--job-execution-mode=Sync --enable-job-restart=True --enable-job-hang-detection=True --job-hang-interval=30" ) create_job_req = CreateJobRequest( ... settings = settings, )其中:
enable_error_monitoring_in_aimaster:表示是否打开容错监控功能。
error_monitoring_args:表示容错监控额外参数。
步骤三:配置容错监控增强功能
您可以根据任务的容错监控需求场景,选择使用以下容错监控增强功能。
配置容错消息通知
任务开启容错监控后,如果您希望容错发生时进行通知,可以在工作空间详情,选择工作空间配置 > 事件通知配置,然后单击新建事件规则,并选择事件类型为DLC任务 > 任务自动容错。具体操作,请参见工作空间事件中心。
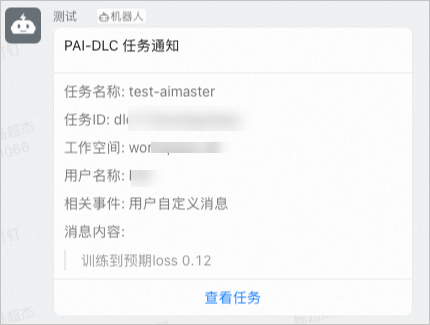
当任务训练出现异常时,比如loss出现Nan,可以在代码中使用AIMaster SDK发送自定义通知消息:
本功能需要安装AIMaster whl包,详情请参见常见问题解答。
from aimaster import job_monitor as jm
job_monitor_client = jm.Monitor(config=jm.PyTorchConfig())
...
if loss == Nan and rank == 0:
st = job_monitor_client.send_custom_message(content="任务训练loss出现Nan")
if not st.ok():
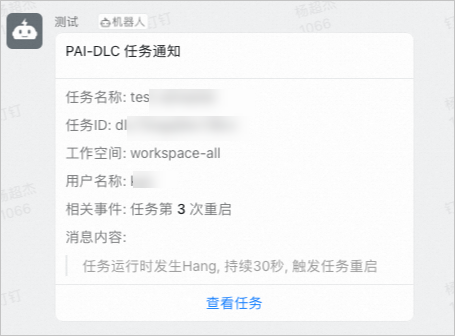
print('failed to send message, error %s' % st.to_string())发送到钉钉群的消息通知示例如下:
|
|
配置自定义容错关键字
容错监控功能已内置了常见的可重试错误的监控模块,如果您希望任务异常实例日志中出现某些关键字时也进行容错,可以在代码中使用以下方法进行配置。配置完成后,容错监控模块会扫描失败的实例尾部日志进行关键信息匹配。
容错策略需要配置为ExitCodeAndErrorMsg。
PyTorch任务自定义容错关键字配置示例
from aimaster import job_monitor as jm jm_config_params = {} jm_config = jm.PyTorchConfig(**jm_config_params) monitor = jm.Monitor(config=jm_config) monitor.set_retryable_errors(["connect timeout", "error_yyy", "error_zzz"])其中:monitor.set_retryable_errors中配置的参数即为自定义容错关键字。
TF任务自定义容错关键字配置示例
from aimaster import job_monitor as jm jm_config_params = {} jm_config = jm.TFConfig(**jm_config_params) monitor = jm.Monitor(config=jm_config) monitor.set_retryable_errors(["connect timeout", "error_yyy", "error_zzz"])
分阶段自定义任务Hang异常检测
目前任务Hang异常检测的配置是针对整个任务的,但是任务状态是分阶段的。例如:在任务初始化阶段,各个节点建立通信可能耗时比较长,但训练阶段日志更新比较快。为了在训练过程中能快速发现任务Hang异常的节点,DLC提供了分阶段自定义任务Hang异常检测功能,支持您在不同训练阶段配置不同的任务Hang异常检测时长,具体配置方法如下。
monitor.reset_config(jm_config_params)
# Example:
# monitor.reset_config(job_hang_interval=10)
# or
# config_params = {"job_hang_interval": 10, }
# monitor.reset_config(**config_params)PyTorch任务分阶段自定义任务Hang异常检测示例如下。
import torch
import torch.distributed as dist
from aimaster import job_monitor as jm
jm_config_params = {
"job_hang_interval": 1800 # 全局30min检测。
}
jm_config = jm.PyTorchConfig(**jm_config_params)
monitor = jm.Monitor(config=jm_config)
dist.init_process_group('nccl')
...
# impl these two funcs in aimaster sdk
# user just need to add annotations to their func
def reset_hang_detect(hang_seconds):
jm_config_params = {
"job_hang_interval": hang_seconds
}
monitor.reset_config(**jm_config_params)
def hang_detect(interval):
reset_hang_detect(interval)
...
@hang_detect(180) # reset hang detect to 3 min, only for func scope
def train():
...
@hang_detect(-1) # disable hang detect temporarily, only for func scope
def test():
...
for epoch in range(0, 100):
train(epoch)
test(epoch)
self.scheduler.step()
使用C4D
C4D(Calibrating Collective Communication over Converged ethernet - Diagnosis),是阿里云自研的用于大模型训练中诊断任务Slow(慢)或Hang(挂起)问题的工具。使用C4D需要依赖阿里云自研的高性能集合通信库ACCL,请确保ACCL已安装并正确配置了环境变量,详情请参见ACCL:阿里云高性能集合通信库。目前,DLC任务选择灵骏智算资源时,可以使用C4D检测功能。
功能介绍
C4D通过汇总任务内所有节点的状态信息,分析判断是否有节点出现通信或非通信层面的问题。系统架构如下图所示:

全量参数说明
开启C4D检测功能后,在其他配置文本框中支持配置的参数如下:
参数 | 描述 | 示例值 |
--c4d-log-level | 设置C4D输出日志级别,取值如下:
默认值为Warning,表示会输出Warning和Error级别的日志。建议在正常运行情况下使用默认值。若需排查性能问题,则可将其设置为Info级别。 |
|
--c4d-common-envs | 设置C4D执行的环境变量,格式为
|
|
当前针对Error级别的日志,AIMaster会自动化隔离对应节点并重新拉起任务。各级别日志处理逻辑如下:
错误等级 | 错误描述 | 处理动作 |
Error | 默认情况下,如果通信层面Hang(挂起)时间超过三分钟,则会导致任务失败。您可以通过配置C4D_HANG_TIMEOUT和C4D_HANG_TIMES两个参数来修改默认值。 | AIMaster会直接自动化隔离日志中的节点。 |
Warn | 默认情况下,如果通信层面Hang(挂起)时间超过10秒,虽然影响性能,但不会导致任务失败。您可以通过配置C4D_HANG_TIMEOUT参数来修改默认值。 | 暂时不会自动化隔离日志中的节点,需要人工二次确认。 |
非通信层面Hang(挂起)时间超过10秒,有可能会导致任务失败。 | 暂时不会自动化隔离日志中的节点,需要人工二次确认。 | |
Info | 通信层面慢和非通信层面慢。 | 这部分诊断日志主要是针对性能问题,需要人工二次确认。 |
在DLC任务运行过程中,如果发现任务Slow(慢)或Hang(挂起)的情况,您可以在DLC任务列表中,单击任务名称,进入任务概览页面。在下方的实例区域,查看任务的AIMaster节点日志,即可看到C4D的诊断结果。关于诊断结果详情,请参见诊断结果样例。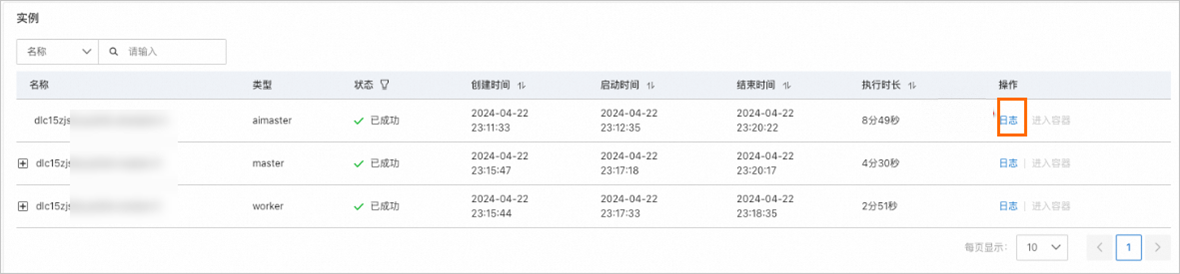
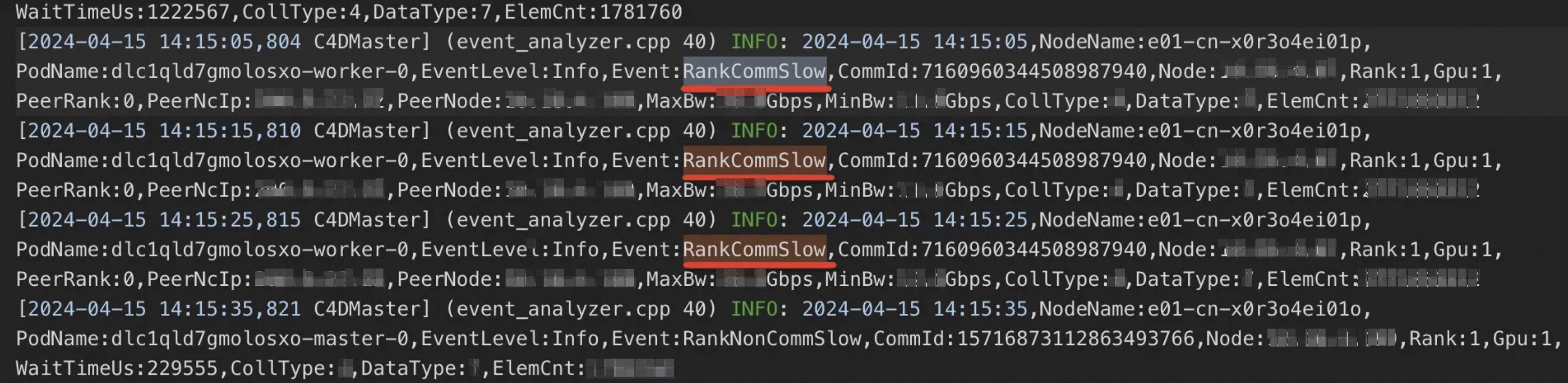
诊断结果样例
RankCommHang:表示有节点出现了通信层面Hang(挂起)的问题。

RankNonCommHang:表示有节点出现了非通信层面Hang(挂起)的问题,例如计算部分出现了Hang(挂起)。
RankCommSlow:表示有节点出现了通信层面慢的问题。
RankNonCommSlow:表示有节点出现了非通信层面慢的问题。



使用函数调用栈快照分析工具
大模型训练任务常见的故障类型之一就是任务有时会Hang(挂起),其中很常见的一种类型是NCCL Hang,此时任务失败的时候会打印“Watchdog caught collective operation timeout”这类日志,针对这类常见的问题,我们开发了模型任务函数调用栈快照分析工具,来帮助用户快速定位任务Hang的根因,具体使用步骤如下:
步骤一:安装pystack或者py-spy
用户需要先确认自己使用的容器镜像中是否已安装pystack或者py-spy工具,如果没有则需要事先安装下,下面是安装pystack工具的命令样例:
pip install pystack -i https://mirrors.cloud.aliyuncs.com/pypi/simple/ --trusted-host mirrors.cloud.aliyuncs.com步骤二:打开自动容错功能中的Hang检测开关
开启方法请参见通过控制台开启容错监控功能,开启“任务挂起(Hang)检测”开关之后,还需要对“任务挂起(Hang)检测阈值”部分的时间配置一个合适的值,才能正常使用函数调用栈快照分析工具,需要先确认下自己模型任务的超时时间是多少,这个超时时间一般可以在任务Hang(挂起)之后报错的日志中看到,下面是一个样例:
Watchdog caught collective operation timeout: WorkNCCL(SeqNum=2143, OpType=ALLREDUCE, NumelIn=659, NumelOut=659, Timeout(ms)=600000) ran for 600535 milliseconds before timing out从这条报错日志的Timeout字段,可以看出这个模型任务的超时时间是600秒,也就是10分钟,在这种情况下我们一般建议将“任务挂起(Hang)检测阈值”配置为450秒,如果任务报错日志中的Timeout字段是1800秒,则建议将“任务挂起(Hang)检测阈值”配置为1500秒,原则就是尽量让“任务挂起(Hang)检测阈值”的取值比Timeout字段的值小150~200秒左右。
按照前面说的步骤正确配置了Hang(挂起)检测功能之后,在任务发生了Hang(挂起)之后,AIMaster就会自动触发针对模型任务进程的函数调用栈的采集和分析,分析结果可以在AIMaster节点的日志中看到, 下面是一个任务Hang(挂起)住之后工具输出的函数调用栈分析结果样例:
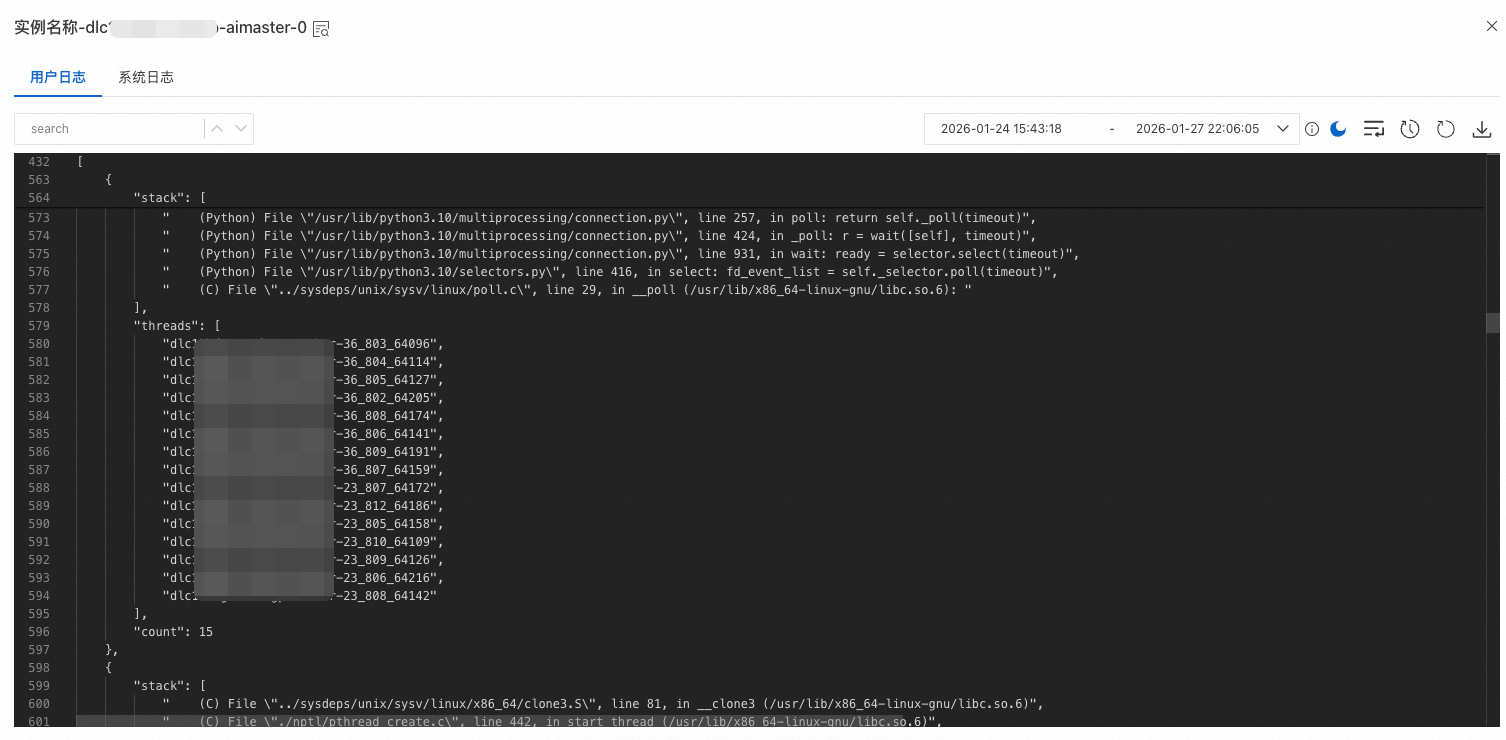
函数调用栈分析结果中的stack字段代表具体的函数调用栈,threads字段代表出现这些函数调用栈的线程是哪些,count字段代表出现这个函数调用栈的线程数量,对于count为1的这些栈需要重点怀疑是其导致了任务出现了Hang(挂起)。
步骤四:查看重启原因
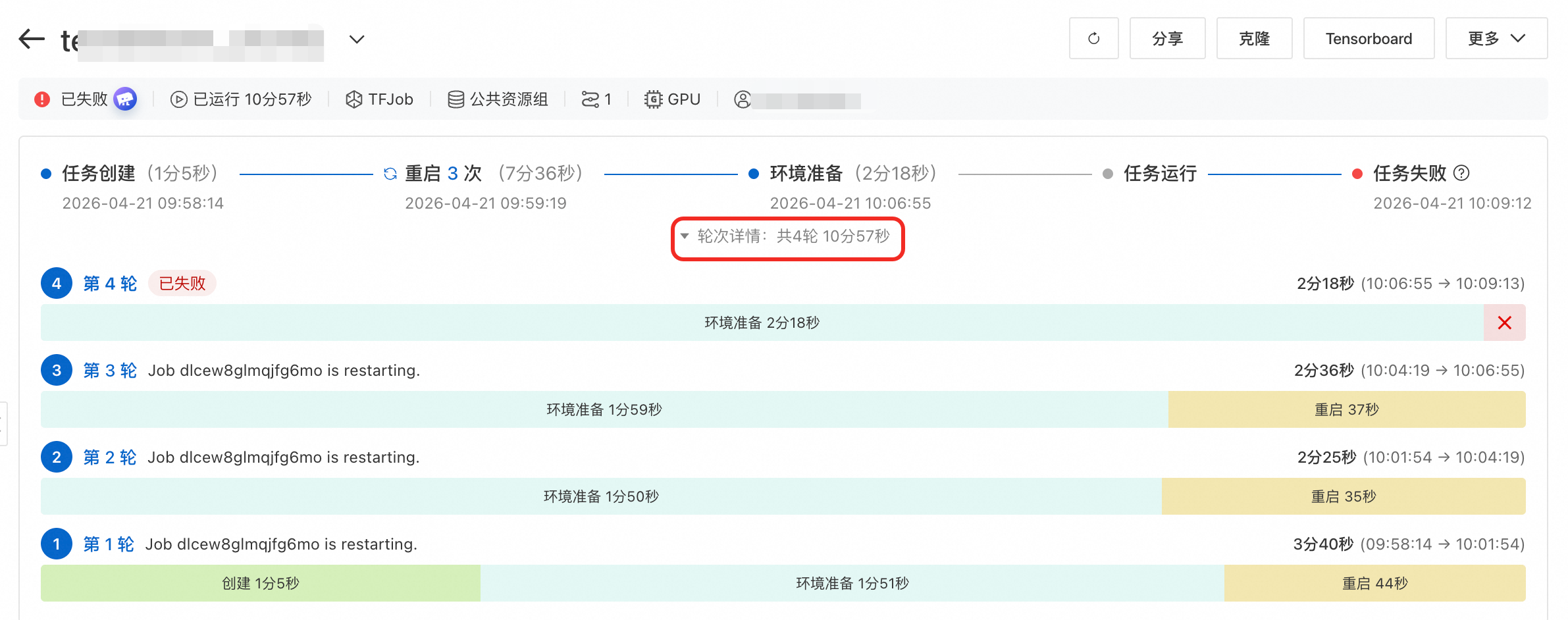
查看重启轮次:任务重启信息按轮次进行划分,您可以在任务详情页通过单击展开轮次详情,查看任务在各个阶段耗费的时长等信息,从而更精准地了解任务运行状况。
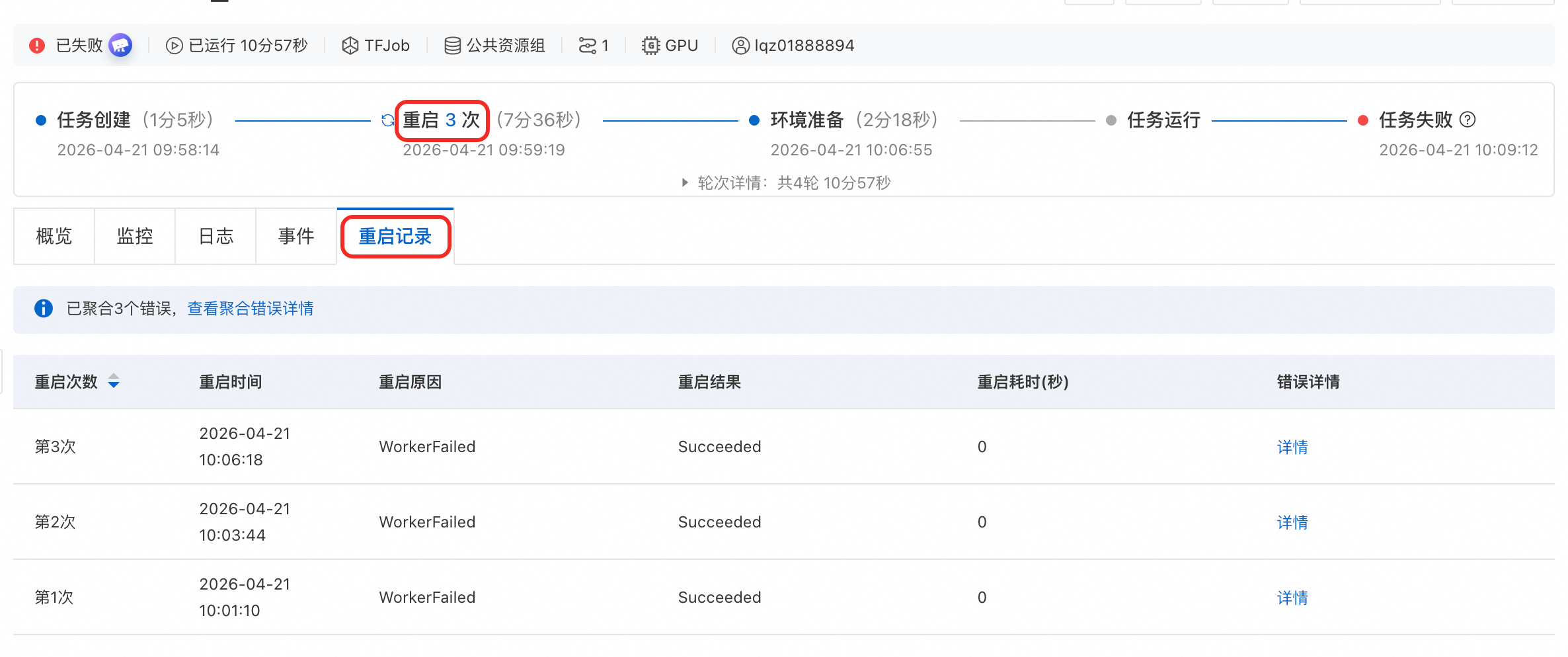
查看重启记录:您可以单击重启次数或直接单击重启记录页签,查看相关重启信息,包括重启原因、重启结果、重启耗时等。
具体操作如下:
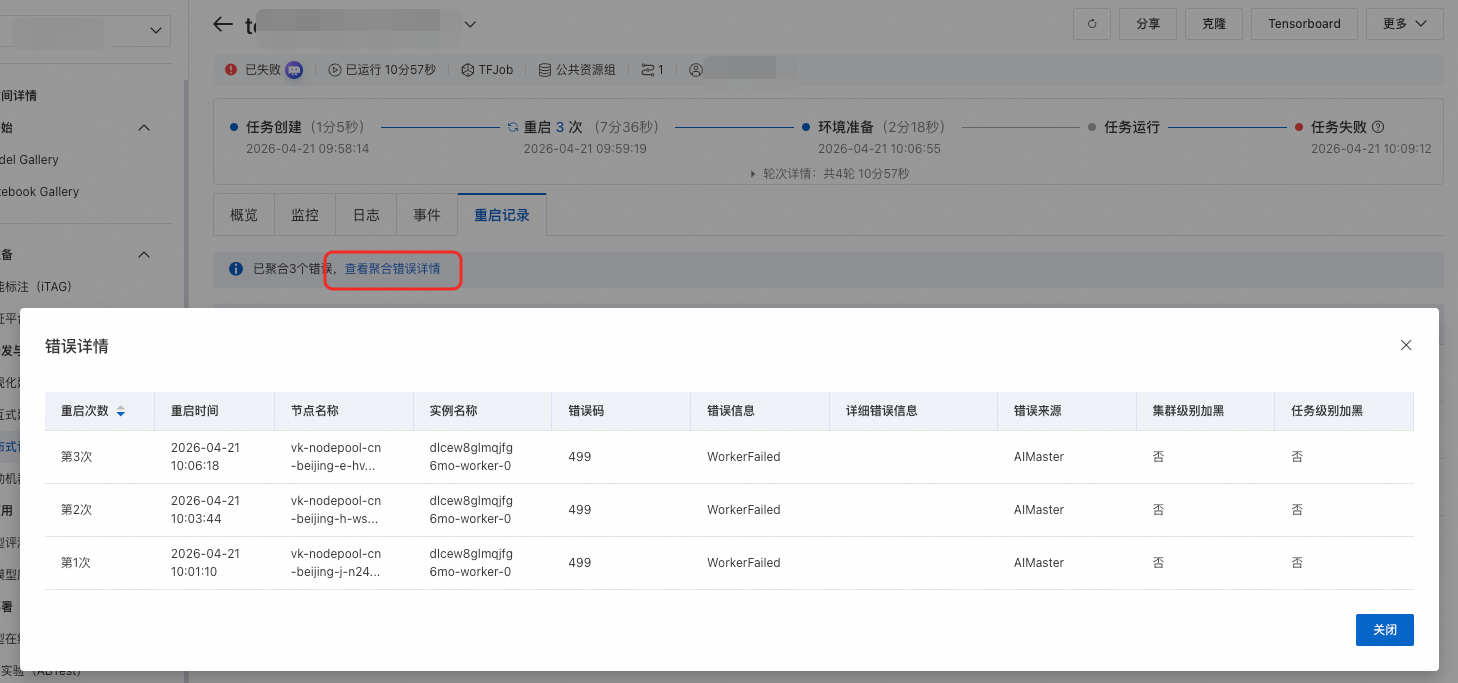
在重启记录列表中,单击详情可查看该次重启的详细信息,包含重启次数、重启时间、节点名称、实例名称、错误码、错误信息、错误来源等信息。
单击查看聚合错误详情可展开全部重启记录的详情列表。
常见问题解答
Q:如何安装AIMaster SDK ?
根据您的Python版本,使用以下命令安装对应的whl包。
# Python 3.6
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp36-cp36m-linux_x86_64.whl
# Python 3.8
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp38-cp38-linux_x86_64.whl
# Python 3.10
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp310-cp310-linux_x86_64.whl