
K近邻算法进行分类的原理是针对预测表的每行数据,从训练表中选择与其距离最近的K条记录,将这K条记录中类别数量最多的类,作为该行的类别。
组件配置
您可以使用以下任意一种方式,配置K近邻组件参数。
方式一:可视化方式
在Designer工作流页面配置组件参数。
页签 | 参数 | 描述 |
字段设置 | 选择训练表特征列 | 用于训练的特征列。 |
选择训练表的标签列 | 训练的目标列。 | |
选择预测表特征列 | 如果未配置该参数,则表示其与训练表特征列相同。 | |
产出表附加ID列 | 用于标识该列的身份,从而获得某列对应的预测值。系统默认使用预测表特征列,作为附加ID列。 | |
输入表数据是稀疏格式 | 使用KV格式表示稀疏数据。 | |
kv间的分隔符 | 默认为英文逗号(,)。 | |
key和value的分隔符 | 默认为英文冒号(:)。 | |
参数设置 | 近邻个数 | 默认值为100。 |
执行调优 | 核心数 | 默认系统自动分配。 |
内存数 | 默认系统自动分配。 |
方式二:PAI命令方式
使用PAI命令方式,配置该组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
PAI -name knn
-DtrainTableName=pai_knn_test_input
-DtrainFeatureColNames=f0,f1
-DtrainLabelColName=class
-DpredictTableName=pai_knn_test_input
-DpredictFeatureColNames=f0,f1
-DoutputTableName=pai_knn_test_output
-Dk=2;参数 | 是否必选 | 描述 | 默认值 |
trainTableName | 是 | 训练表的表名。 | 无 |
trainFeatureColNames | 是 | 训练表的特征列名。 | 无 |
trainLabelColName | 是 | 训练表的标签列名。 | 无 |
trainTablePartitions | 否 | 训练表中,参与训练的分区。 | 所有分区 |
predictTableName | 是 | 预测表的表名。 | 无 |
outputTableName | 是 | 输出表的表名。 | 无 |
predictFeatureColNames | 否 | 预测表的特征列名。 | 与trainFeatureColNames相同 |
predictTablePartitions | 否 | 预测表中,参与预测的分区。 | 所有分区 |
appendColNames | 否 | 输出表中,附加预测表的列名。 | 与predictFeatureColNames相同 |
outputTablePartition | 否 | 输出表的分区。 | 全表 |
k | 否 | 最近邻的数量。取值范围为1~1000。 | 100 |
enableSparse | 否 | 输入表数据是否为稀疏格式。取值范围为{true,false}。 | false |
itemDelimiter | 否 | 如果输入表数据为稀疏格式,则KV对之间的分隔符。 | 英文逗号(,) |
kvDelimiter | 否 | 如果输入表数据为稀疏格式,则key和value之间的分隔符。 | 英文冒号(:) |
coreNum | 否 | 节点数量。与memSizePerCore搭配使用,取值范围为1~20000。 | 系统自动计算 |
memSizePerCore | 否 | 单个节点的内存,取值范围为1024 MB~64*1024 MB。 | 系统自动计算 |
lifecycle | 否 | 输出表的生命周期。 | 无 |
示例
生成训练数据。
create table pai_knn_test_input as select * from ( select 1 as f0,2 as f1, 'good' as class union all select 1 as f0,3 as f1, 'good' as class union all select 1 as f0,4 as f1, 'bad' as class union all select 0 as f0,3 as f1, 'good' as class union all select 0 as f0,4 as f1, 'bad' as class )tmp;使用PAI命令,提交K近邻算法组件参数。
pai -name knn -DtrainTableName=pai_knn_test_input -DtrainFeatureColNames=f0,f1 -DtrainLabelColName=class -DpredictTableName=pai_knn_test_input -DpredictFeatureColNames=f0,f1 -DoutputTableName=pai_knn_test_output -Dk=2;查看训练结果。
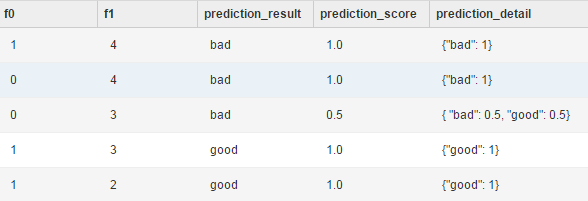 其中:
其中:f0和f1表示结果附件列。
prediction_result表示分类结果。
prediction_score表示分类结果对应的概率。
prediction_detail表示最近的K个分类及其对应的概率。