
x13_arima是一种用于时间序列分析的算法,专门用于处理季节性数据的调整。它基于开源软件包X-13ARIMA-SEATS,结合了ARIMA模型和季节性调整技术,以提高预测的准确性和数据分析的有效性。
算法说明
Arima全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model),是由博克思(Box)和詹金斯(Jenkins)于70年代初提出的著名时间序列预测方法,所以又称为box-jenkins模型、博克思-詹金斯法。
算法规模如下:
支持规模
行:单Group数据最大1200条
列:1数值列
资源计算方式
不设置groupColNames,默认计算方式
coreNum=1 memSizePerCore=4096设置groupColNames,默认计算方式
coreNum=floor(总数据行数/12万) memSizePerCore=4096
组件配置
方式一:可视化方式
在Designer工作流页面添加x13_arima组件,并在界面右侧配置相关参数:
参数类型 | 参数 | 描述 |
字段设置 | 时序列 | 必选,仅用来对数值列排序,具体数值与计算无关。 |
数值列 | 必选。 | |
分组列 | 可选,多列以半角逗号(,)分隔,例如col0,col1,每个分组会构建一个时间序列。 | |
参数设置 | 格式 | 支持输入的格式为p,d,q。 p、d和q均为非负整数,取值范围为[0, 36]。
|
开始日期 | 支持输入的格式为year.seasonal。例如1986.1。 | |
series频率 | 支持输入正整数,取值范围为12。 | |
格式 | 支持输入的格式为sp,sd,sq。sp、sd和sq均为非负整数,取值范围为[0, 36]。
| |
seasonal周期 | 支持输入数字,取值范围为(0,12]。默认值为12。 | |
预测条数 | 支持输入数字,取值范围为(0,120]。默认值为12。 | |
预测置信水平 | 支持输入数字,取值范围为(0, 1)默认值为0.95。 | |
执行调优 | 核数目 | 节点个数,默认自动计算。 |
内存数 | 单个节点内存大小,单位为MB。 |
方式二:PAI命令方式
使用PAI命令配置x13_arima组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
PAI -name x13_arima
-project algo_public
-DinputTableName=pai_ft_x13_arima_input
-DseqColName=id
-DvalueColName=number
-Dorder=3,1,1
-Dstart=1949.1
-Dfrequency=12
-Dseasonal=0,1,1
-Dperiod=12
-DpredictStep=12
-DoutputPredictTableName=pai_ft_x13_arima_out_predict
-DoutputDetailTableName=pai_ft_x13_arima_out_detail参数 | 是否必选 | 默认值 | 描述 |
inputTableName | 是 | 无 | 输入表的名称。 |
inputTablePartitions | 否 | 默认选择所有分区 | 输入表中,用于训练的特征列名。 |
seqColName | 是 | 无 | 时序列。仅用来对valueColName排序。 |
valueColName | 是 | 无 | 数值列。 |
groupColNames | 否 | 无 | 分组列,多列用逗号分隔,例如col0,col1。每个分组会构建一个时间序列。 |
order | 是 | 无 | p、d和q分别表示自回归系数、差分、滑动回归系数。取值均为非负整数,范围为[0, 36]。 |
start | 否 | 1.1 | 时序开始日期。字符串类型,格式为year.seasonal,例如1986.1。请参见时序格式介绍。 |
frequency | 否 | 12 说明 12表示12月/年。 | 时序频率。正整数类型,范围为(0, 12]。请参见时序格式介绍。 |
seasonal | 否 | 无seasonal | sp、sd和sq分别表示季节性自回归系数、季节性差分、季节性滑动回归系数。取值均为非负整数,范围为[0, 36]。 |
period | 否 | frequency | seasonal周期。数字类型,取值范围为(0, 100]。 |
maxiter | 否 | 1500 | 最大迭代次数。正整数类型。 |
tol | 否 | 1e-5 | 容忍度,DOUBLE类型。 |
predictStep | 否 | 12 | 预测条数。数字类型,取值范围为(0, 365]。 |
confidenceLevel | 否 | 0.95 | 预测置信水平。数字类型,取值范围为(0, 1)。 |
outputPredictTableName | 是 | 无 | 预测输出表。 |
outputDetailTableName | 是 | 无 | 详细信息表。 |
outputTablePartition | 否 | 默认不输出到分区 | 输出分区,分区名。 |
coreNum | 否 | 默认自动计算 | 节点个数,与参数memSizePerCore配对使用,正整数。 |
memSizePerCore | 否 | 默认自动计算 | 单个节点内存大小,单位为MB。正整数,取值范围为[1024, 64 *1024]。 |
lifecycle | 否 | 默认没有生命周期 | 指定输出表的生命周期。 |
时序格式介绍
参数start和frequency规定了数据(valueColName)的两个时间维度ts1、ts2:
frequency:表示单位周期内数据的频率,即单位ts1中ts2的频率。
start:格式为
n1.n2,表示开始日期是第n1个ts1中的第n2个ts2。
单位时间 | ts1 | ts2 | frequency | start |
12月/年 | 年 | 月 | 12 | 1949.2 表示第1949年中的第2个月 |
4季/年 | 年 | 季 | 4 | 1949.2 表示第1949年中的第2个季度 |
7天/周 | 周 | 天 | 7 | 1949.2 表示第1949周中的第2天 |
1 | 任何时间单位 | 1 | 1 | 1949.1 表示第1949(年、天、时等) |
例如value=[1,2,3,5,6,7,8,9,10,11,12,13,14,15]
start=1949.3,frequency=12表示数据是12月/年,预测开始日期是1950.06。year
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
1949
1
2
3
4
5
6
7
8
9
10
1950
11
12
13
14
15
start=1949.3,frequency=4表示数据是4季/年,预测开始的日期是1953.02。year
Qtr1
Qtr2
Qtr3
Qtr4
1949
1
2
1950
3
4
5
6
1951
7
8
9
10
1952
11
12
13
14
1953
14
15
start=1949.3,frequency=7表示数据是7天/周,预测开始的日期是1951.04。week
Sun
Mon
Tue
Wed
Thu
Fri
Sat
1949
1
2
3
4
5
1950
6
7
8
9
10
11
12
1951
13
14
15
start=1949.1,frequency=1表示任何时间单位,预测开始日期是1963.00。cycle
p1
1949
1
1950
2
1951
3
1952
4
1953
5
1954
6
1955
7
1956
8
1957
9
1958
10
1959
11
1960
12
1961
13
1962
14
1963
15
具体示例
准备测试数据
使用的数据集为AirPassengers.csv,是1949~1960年每个月国际航空的乘客数量,如下表所示。关于该数据集更详细的内容介绍,请参见AirPassengers。
id | number |
1 | 112 |
2 | 118 |
3 | 132 |
4 | 129 |
5 | 121 |
... | ... |
使用MaxCompute客户端的Tunnel命令上传数据,命令如下。关于MaxCompute客户端的安装及配置请参见使用本地客户端(odpscmd)连接,关于Tunnel命令使用详情请参见Tunnel命令。
create table pai_ft_x13_arima_input(id bigint,number bigint);
tunnel upload xxxx/airpassengers.csv pai_ft_x13_arima_input -h true;执行PAI 命令
您可以使用SQL脚本执行如下PAI命令,也可以使用ODPS SQL节点执行如下PAI命令。
PAI -name x13_arima
-project algo_public
-DinputTableName=pai_ft_x13_arima_input
-DseqColName=id
-DvalueColName=number
-Dorder=3,1,1
-Dseasonal=0,1,1
-Dstart=1949.1
-Dfrequency=12
-Dperiod=12
-DpredictStep=12
-DoutputPredictTableName=pai_ft_x13_arima_out_predict
-DoutputDetailTableName=pai_ft_x13_arima_out_detail输出说明:
输出表outputPredictTableName
字段说明
column name
comment
pdate
预测日期。
forecast
预测结论。
lower
置信度为 confidenceLevel(默认0.95)时,预测结论下界。
upper
置信度为 confidenceLevel(默认0.95)时,预测结论上界。
数据展示
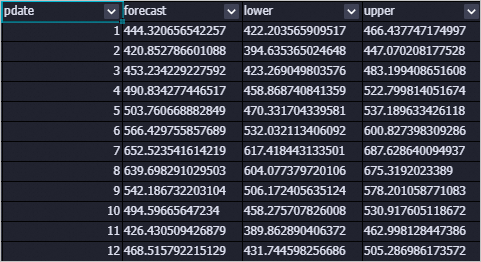
输出表outputDetailTableName
字段说明
column name
comment
key
model:表示模型
evaluation:表示评估结果
parameters:表示训练参数
log:表示训练日志
summary
存储具体信息。
数据展示

常见问题
为什么预测结果都一样?
在模型训练异常时,会调用均值模型,则所有预测结果都是训练数据的均值。常见的异常包括时序差分diff后不稳定、训练没有收敛、方差为0等,您可以在logview中查看单独节点的stderr文件,获取具体的异常信息。
参数非常多,如何设置?
x13_arima组件需要设置p、d、q、sp、sd和sq等参数,如果不确定如何配置,建议使用
x13_auto_arima组件。该组件只需设置上界,系统会自动搜索最优参数。
异常信息:
ERROR: Number of observations after differencing and/or conditional AR estimation is 9, which is less than the minimum series length required for the model estimated, 24异常原因为数据较少,请调整频率,或增加数据。
异常信息:
ERROR: Order of the MA operator is too large异常原因为数据较少。
异常信息:
ERROR: Series to be modelled and/or seasonally adjusted must have at least 3 complete years of data如果填写了季节性参数,则需要3年的数据。
相关文档
x13_arima组件需要设置p、d、q、sp、sd和sq等参数,如果不确定如何配置,建议使用x13_auto_arima组件。该组件只需设置上界,系统会自动搜索最优参数。详情请参见x13_auto_arima。