
您可以使用文本摘要预测组件,对已训练好的文本摘要模型进行测试,并根据预测结果评估模型的推理效果。本文为您介绍文本摘要预测组件的配置方法。
前提条件
已开通OSS并完成授权,详情请参见开通OSS服务和云产品依赖与授权:Designer。
使用限制
仅支持DLC计算资源。
可视化配置组件参数
您可以在Designer中,通过可视化的方式配置组件参数。
输入桩
输入桩(从左到右)
类型
建议上游组件
是否必选
预测数据
OSS
是
预测模型
组件输出
否
组件配置
页签
参数
描述
字段设置
输入数据格式
输入文件的文本列。默认值为target:str:1,source:str:1。
原文列选择
原文在输入表中对应的列名。默认值为source。
输出追加列选择
将输入文件的若干文本列追加到输出文本列之后,多列之间使用半角逗号(,)分隔。默认值为source。
输出列选择
配置数据结果表的列名。默认值为predictions,beams。
预测数据输出
配置预测结果文件在OSS Bucket中的路径。
使用自有模型
是否使用PAI默认模型,进行直接预测。取值如下。
是
否(默认值)
是否为Megatron模型
仅支持文本摘要训练组件中列出的带mg前缀的预训练模型,取值如下。
是
否(默认值)
模型存储路径
仅使用自有模型为是时,才需要配置该参数。
自定义模型所在OSS Bucket中的存储路径。
参数设置
批次大小
训练过程中的批处理大小。INT类型,默认值为8。
如果使用多机多卡,则表示每个GPU上的批处理大小。
文本最大长度
表示序列整体最大长度。INT类型,取值范围为(1,512),默认值为512。
语言
表示当前文本处理的语言:
zh:中文。
en:英文。
是否从原文中拷贝文本
表示是否采用复制机制,取值如下:
false(默认值)
true
解码器最小长度
表示解码器最小长度,INT类型,默认值为12。模型输出长度大于该值。
解码器最大长度
表示解码器最大长度,INT类型,默认值为32。模型输出长度小于该值。
最小不重复字段
表示不重复的片段大小,INT类型,默认值为2。
集束搜索数量
表示集束搜索大小,INT类型,默认值为5。
返回候选答案数量
表示返回结果的数量,INT类型,默认值为5。
重要该参数配置需要与集束搜索数量相同。
执行调优
GPU机型类型
计算资源的GPU机型,默认值为gn5-c8g1.2xlarge。
使用示例
您可以使用文本摘要预测组件构建如下工作流,存在以下两种调用方式。
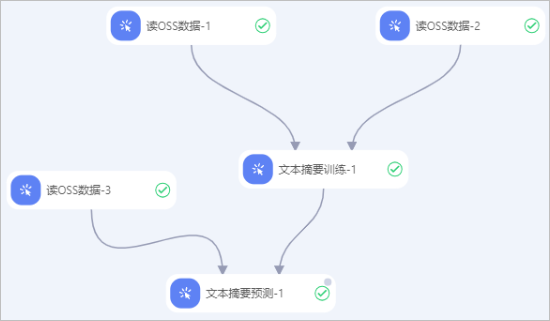
方式一:使用文本摘要训练组件微调过的模型。
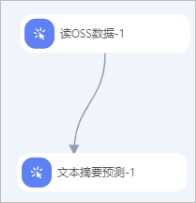
方式二:使用自定义模型。
本示例中,您需要按照以下流程配置组件并运行工作流:
参照文本摘要训练组件的使用示例构建工作流。
准备需要生成摘要的数据(predict_data.txt),并上传至OSS的Bucket。本示例使用的测试数据是通过制表符分隔的TXT文件。
同时支持对CSV文件的处理,您可以通过MaxCompute客户端的Tunnel命令,将数据集上传至MaxCompute。关于MaxCompute客户端的安装及配置,详情请参见使用客户端(odpscmd)连接;关于Tunnel命令的更多内容,详情请参见Tunnel命令。
使用方式一中的读OSS数据-3或方式二中的读OSS数据-1组件读取测试数据集。即配置读OSS数据组件的OSS数据路径参数为存放测试数据集的OSS路径。
将模型文件和测试数据集接入文本摘要预测组件,并配置具体参数,详情请参见可视化配置组件参数。
当使用文本摘要训练组件微调过的模型时,您需要将文本摘要训练组件的模型输出端连接到文本摘要预测的模型输入端。
当使用自有模型时,您可以将字段设置页签的使用自定义模型参数配置为是,并配置模型存储路径参数为存储模型的OSS路径。
单击
 按钮运行工作流。工作流运行成功后,您可以在文本摘要预测的预测数据输出参数配置的OSS路径下,查看输出的摘要结果。
按钮运行工作流。工作流运行成功后,您可以在文本摘要预测的预测数据输出参数配置的OSS路径下,查看输出的摘要结果。