
本文通过分析北京一年的真实天气数据,构建雾霾天气预测模型,从而挖掘对雾霾天气(指PM 2.5)影响最大的污染物。
数据集
本实验为2016年全年(以小时为单位)的北京空气指标数据,具体字段如下。
字段名 | 类型 | 描述 |
time | STRING | 日期,精确到天。 |
hour | STRING | 第几小时的数据。 |
pm2 | STRING | PM 2.5指标。 |
pm10 | STRING | PM 10指标。 |
so2 | STRING | 二氧化硫指标。 |
co | STRING | 一氧化碳指标。 |
no2 | STRING | 二氧化氮指标。 |
雾霾天气预测
进入Designer页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应的工作空间。
在工作空间页面的左侧导航栏选择,进入Designer页面。
构建工作流。
在Designer页面,单击预置模板页签。
在模板列表的雾霾天气预测区域,单击创建。
在新建工作流对话框,配置参数(可以全部使用默认参数)。
其中:工作流数据存储配置为OSS Bucket路径,用于存储工作流运行中产出的临时数据和模型。
单击确定。
您需要等待大约十秒钟,工作流可以创建成功。
在工作流列表,双击雾霾天气预测工作流,进入工作流。
系统根据预置的模板,自动构建工作流,如下图所示。
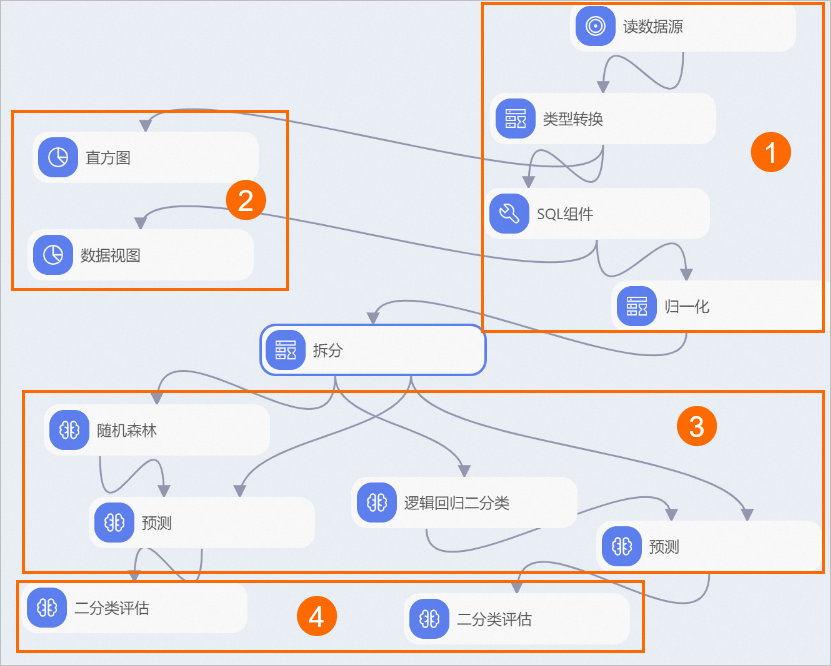
区域
描述
①
数据导入及预处理:
通过读数据表组件,导入数据源。
通过类型转换组件,将STRING类型的数据转换为DOUBLE类型。
通过SQL脚本组件,将目标列转换为0和1的二值类型。本实验中,pm2列为目标列。数值大于200的作为重度雾霾天气,将其标记为1,反之标记为0。SQL语句如下。
select time,hour,(case when pm2>200 then 1 else 0 end),pm10,so2,co,no2 from ${t1};通过归一化组件,去除量纲,即将不同指标污染物的单位统一。
②
统计分析:
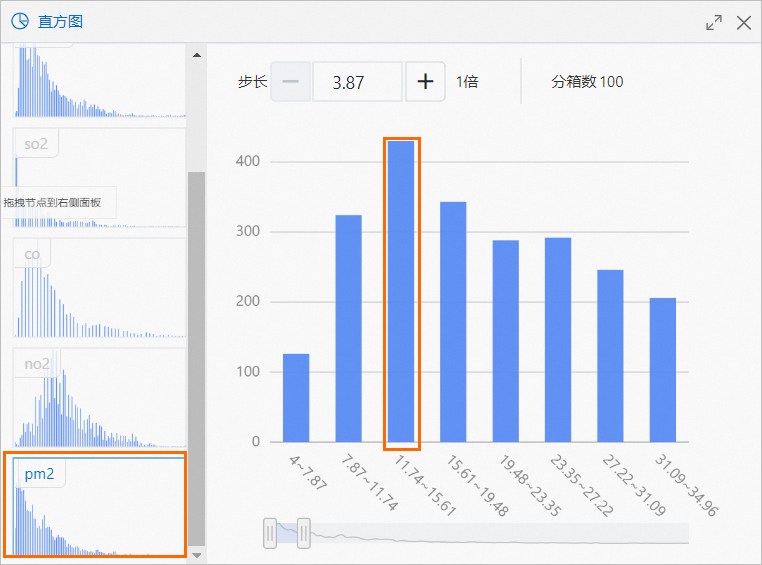
通过直方图组件以可视化的方式查看每种污染物的分布情况。
以PM2.5为例,数值出现最多的区间为11.74~15.61,共430次,如下图所示。
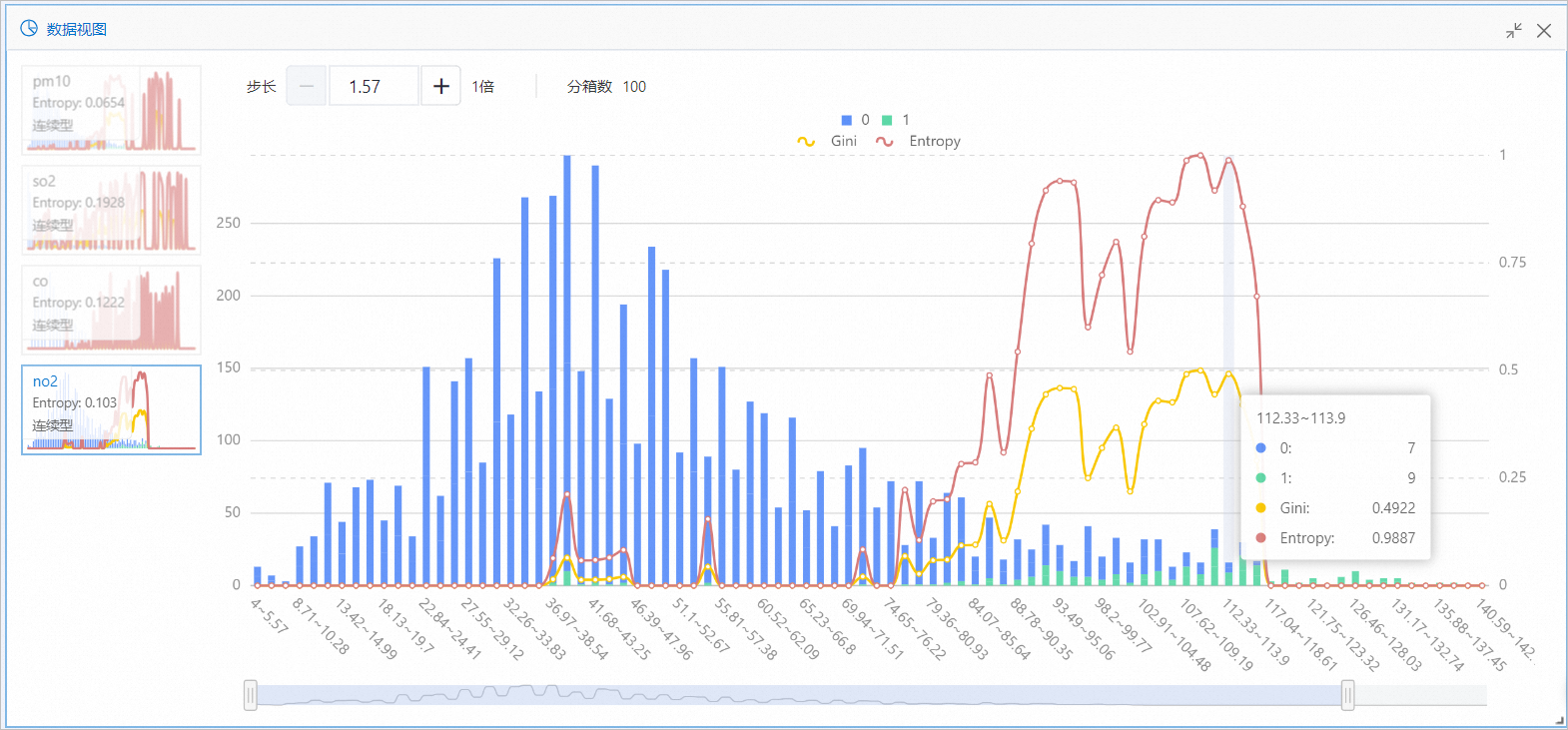
通过数据视图组件以可视化的方式查看每种污染物不同区间对于结果的影响。
以no2为例,在112.33~113.9区间产生了7个目标列为0的目标和9个目标列为1的目标(如下图所示)。因此,no2在112.33~113.9区间时,出现重度雾霾天气的概率较高。Entropy和Gini表示该特征区间对于目标值的影响(信息量层面的影响),数值越大影响越大。
③
模型训练及预测,本实验分别使用随机森林和逻辑回归二分类组件进行模型训练。
④
模型评估。
运行工作流并查看模型效果。
单击画布上方的运行按钮
 。
。工作流运行结束后,右键单击画布中随机森林下游的二分类评估,在快捷菜单,单击可视化分析。
在二分类评估对话框,单击评估图表页签,即可查看随机森林训练模型的预测效果。
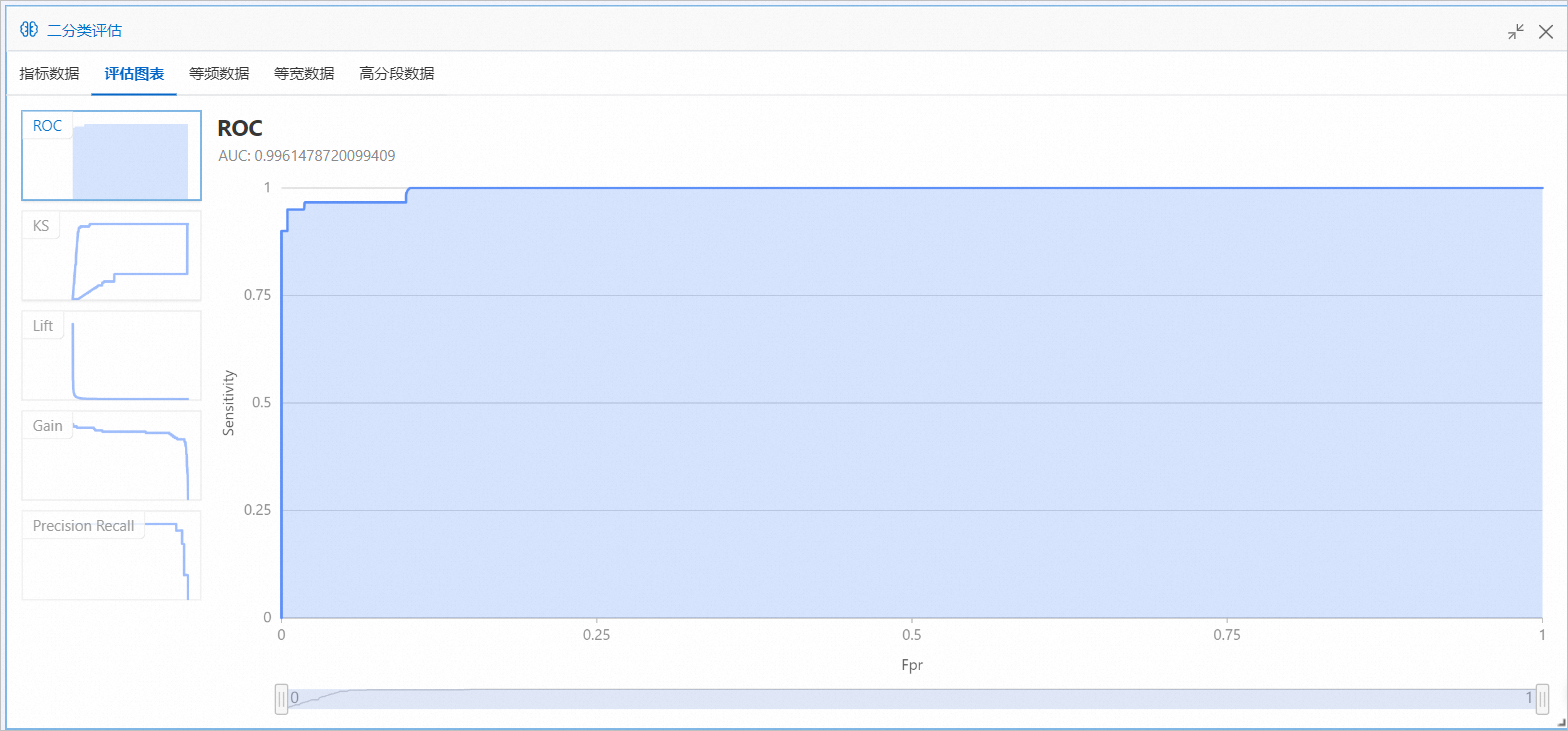 AUC的取值表示随机森林组件训练的雾霾天气预测模型的准确率达到了99%以上。
AUC的取值表示随机森林组件训练的雾霾天气预测模型的准确率达到了99%以上。右键单击画布中的逻辑回归二分类下游的二分类评估,在快捷菜单,单击可视化分析。
在二分类评估对话框,单击评估图表页签,即可查看逻辑回归二分类训练模型的预测效果。
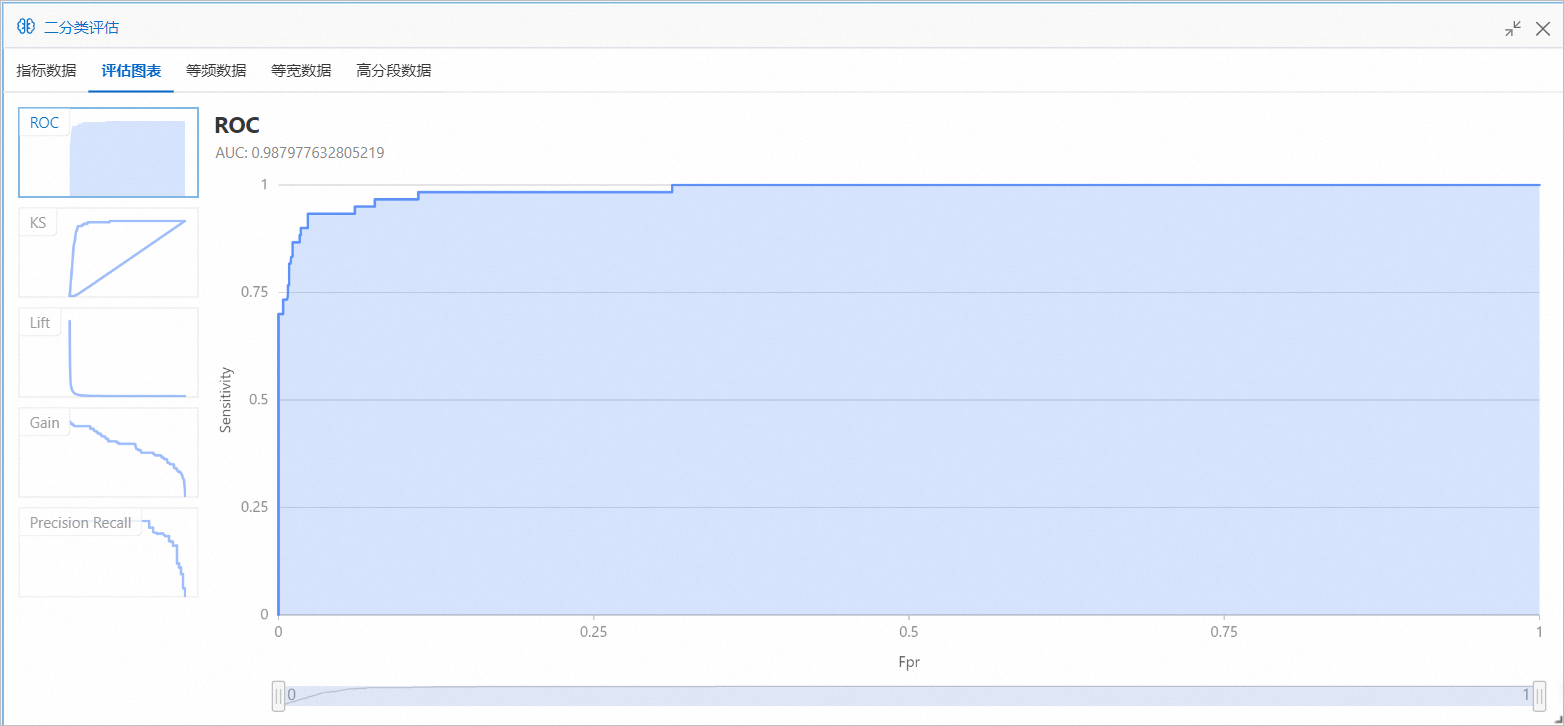 AUC的取值表示逻辑回归二分类组件训练的雾霾天气预测模型的准确率达到了98%以上。
AUC的取值表示逻辑回归二分类组件训练的雾霾天气预测模型的准确率达到了98%以上。