
Designer预置了逻辑回归算法模板,便于您基于中学生的家庭背景及在校行为,通过逻辑回归算法快速生成期末成绩预测模型,从而获得影响中学生学业的关键因素。本文为您介绍逻辑回归算法预置模板的具体使用方法。
背景信息
通过本工作流获得学生考试成绩预测模型后,您可以将需要预测的内容上传至MaxCompute表中,从而进行离线预测。
前提条件
数据集
本工作流的数据集由25个特征列和一个目标列组成,具体字段如下。
字段名 | 类型 | 描述 |
sex | STRING | 性别。F表示女,M表示男。 |
address | STRING | 住址。U表示城市,R表示乡村。 |
famsize | STRING | 家庭成员数。LE3表示少于三人,GT3表示多于三人。 |
pstatus | STRING | 是否与父母一起住。T表示与父母一起住,A表示与父母分开住。 |
medu | DOUBLE | 母亲的文化水平,从0~4表示学历依次增高。 |
fedu | DOUBLE | 父亲的文化水平,从0~4表示学历依次增高。 |
mjob | STRING | 母亲的工作,包括教师相关、健康相关及服务业。 |
fjob | STRING | 父亲的工作,包括教师相关、健康相关及服务业。 |
guardian | STRING | 学生的监管人,包括mother、father及other。 |
traveltime | DOUBLE | 从家到学校需要的时间,单位为分钟。 |
studytime | DOUBLE | 每周的学习时间,单位为小时。 |
failures | DOUBLE | 挂科次数。 |
schoolsup | STRING | 是否有额外的学习辅助,取值为yes或no。 |
fumsup | STRING | 是否有家教,取值为yes或no。 |
paid | STRING | 是否有相关考试学科的辅助,取值为yes或no。 |
activities | STRING | 是否有课外兴趣班,取值为yes或no。 |
higher | STRING | 是否有向上求学意愿,取值为yes或no。 |
internet | STRING | 家里是否连网,取值为yes或no。 |
famrel | DOUBLE | 家庭关系,从1~5表示关系从差到好。 |
freetime | DOUBLE | 课余时间量,从1~5表示课余时间依次增多。 |
goout | DOUBLE | 与朋友出去玩的频率,从1~5表示从少到多。 |
dalc | DOUBLE | 日饮酒量,从1~5表示从少到多。 |
walc | DOUBLE | 周饮酒量,从1~5表示从少到多。 |
health | DOUBLE | 健康状况,从1~5表示状态从差到好。 |
absences | DOUBLE | 出勤量,取值范围0次~93次。 |
g3 | STRING | 期末成绩,使用20分制表示。 |
工作流数据的示例如下。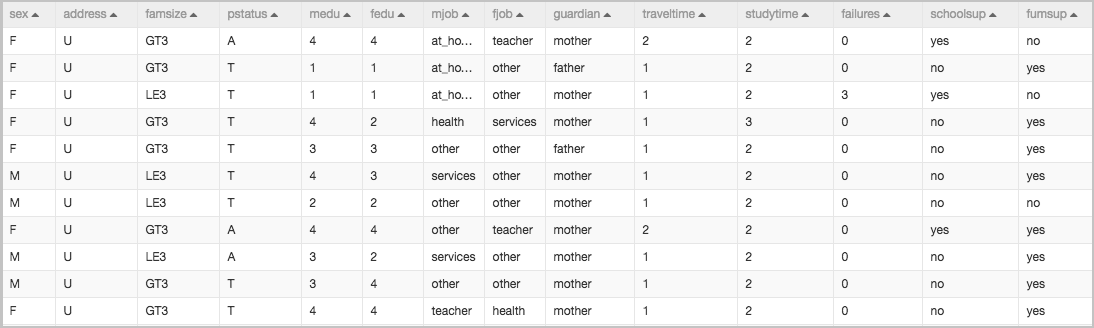
预测学生考试成绩
进入Designer页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择,进入Designer页面。
构建工作流。
在Designer页面,单击预置模板页签。
在模板列表的在线预测-中学生成绩预测区域,单击创建。
在新建工作流对话框,配置参数(可以全部使用默认参数)。
其中:工作流数据存储配置为OSS Bucket路径,用于存储工作流运行中产出的临时数据和模型。
单击确定。
您需要等待大约十秒钟,工作流可以创建成功。
在工作流列表,双击在线预测-中学生成绩预测工作流,进入工作流。
系统根据预置的模板,自动构建工作流,如下图所示。
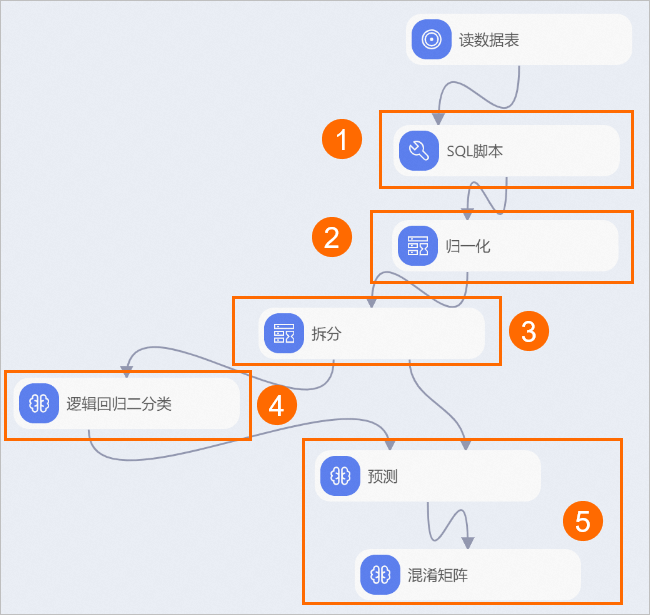
区域
描述
①
数据预处理。使用SQL脚本组件将文本数据结构化:
将源数据中的yes和no分别转换为0和1。
对于多种类的文本型字段,结合业务场景将数据抽象化。例如Mjob字段,将teacher表示为1,其他值表示为0,即抽象后该特征表示工作是否与教育相关。
对于目标列,将取值大于18的表示为1,反之表示为0。
②
使用归一化组件将所有字段转换为0~1之间,从而消除字段大小不均衡造成的影响。
③
将输入数据集按照8:2的比例拆分为训练数据集和预测数据集。
④
通过逻辑回归算法,生成离线模型。
⑤
通过混淆矩阵组件评估模型准确率。
运行工作流并查看输出结果。
单击画布上方的运行按钮
 ,运行工作流。
,运行工作流。工作流运行结束后,右键单击画布中的混淆矩阵,在快捷菜单,单击可视化分析。
在混淆矩阵对话框,单击统计信息页签,即可查看模型预测准确率为80%以上。
相关文档
关于算法组件更详细的内容介绍,请参见: