
本文通过PAI提供的文本分析组件,实现简单的商品标签自动归类系统。
背景信息
通常每件商品的描述会包含很多维度标签。例如,一双鞋子的商品描述可能是“少女英伦风系带马丁靴女磨砂真皮厚底休闲短靴”。一个包的商品描述可能是“天天特价包包2016新款秋冬斜挎包韩版手提包流苏贝壳包女包单肩包”。这些维度可以包含时间、产地及款式等,如何按照特定维度将数以万计的商品进行归类是电商平台的难题之一,其中最大的挑战是如何从商品描述中抽取维度标签。PAI提供的文本分析组件可以自动学习标签词语,从而实现标签自动归类。
前提条件
准备数据集
本工作流数据是整理的一份2016年双十一购物清单,共两千多条商品描述,每一行表示一件商品的标签聚合。
您需要前往DataWorks数据开发模块,新建一个只包含一个列名为content的表,并将上述准备好的数据上传至该表中。具体操作,请参见建表并上传数据。
相似标签自动归类
进入Designer页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应的工作空间。
在工作空间页面的左侧导航栏选择,进入Designer页面。
-
新建自定义工作流,并进入工作流页面,详情请参见新建自定义工作流。
-
构建并运行工作流。
-
在左侧组件列表,将源/目标下的读数据表组件拖入画布中,并重命名为shopping_data-1。
-
在左侧组件列表,将下的Split Word、词频统计及Word2Vec组件拖入画布中。
-
在左侧组件列表,将数据预处理下的增加序号列和类型转换组件拖入画布中。
-
在左侧组件列表,将下的K均值聚类组件拖入画布中。
-
在左侧组件列表,将自定义脚本下的SQL脚本组件拖入画布中。
-
将以上组件拼接为如下工作流,参照下表配置组件的关键参数,并运行组件。
-
在画布中单击shopping_data-1组件,并在右侧表选择页签配置已准备好的表名。
-
在画布中单击Split Word-1组件,并在右侧字段设置页签,选择列名为content。
-
首先单击shopping_data-1组件,在快捷菜单,单击执行该节点。待该组件执行完成后,再以相同的方式执行Split Word-1组件。
-
在画布中单击词频统计-1组件,在右侧字段设置页签,分别设置选择文档ID列为append_id,选择文档内容列为content。
-
单击词频统计-1组件,在快捷菜单,单击执行该节点。
-
向量距离近的两个词,其真实含义比较相近。
-
不同词之间的距离差值具有一定意义。
-
在画布中单击Word2Vec-1组件,在右侧字段设置页签,设置选择单词列为word,在参数设置页签,选中采用hierarchical softmax。
-
单击Word2Vec-1组件,在快捷菜单,单击执行该节点。
-
在画布中单击K均值聚类-1组件,在右侧字段设置页签,选择特征列为f0,附加列为word。
说明该组件在运行时,其上游输入数据表的行数必须大于或等于该组件参数中设定的聚类数目。
-
单击K均值聚类-1组件,在快捷菜单,单击执行该节点。
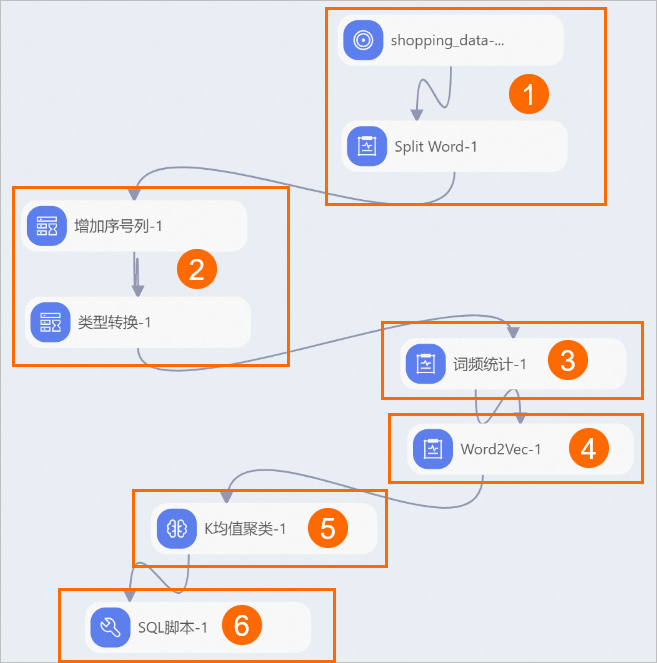
序号
描述
①
上传shopping_data数据,并通过分词组件对数据进行分词,具体操作步骤如下:
②
增加序号列。由于上传的数据只有一个字段,需要通过增加序号列为每个数据增加主键。
首先单击增加序号列-1组件,在快捷菜单,单击执行该节点。待该组件执行完成后,再以相同的方式执行类型转换-1组件。
③
统计词频,展示每个商品中出现的各种词语数量。
④
使用Word2Vec组件将每个词语按照意义在向量维度展开,生成词向量。词向量的含义包括:
经过Word2Vec组件将每个词映射到百维空间上。
结果示例:word2vec算法的输出结果表包含序号、word、f0至f13列,其中word列展示商品关键词(如加厚、韩版、新款、包邮、简约、冬季、秋冬、纯棉等),f0至f13列展示各词对应的浮点数词向量值。
⑤
词向量聚类。使用K均值聚类算法,在已经产生的词向量基础上,计算词向量的距离,并按照意义将标签词自动归类。
其结果展示每个词所属的聚类簇,结果示例如下:词语家用和g归属聚类簇83,男和儿童归属聚类簇79,保暖和加绒归属聚类簇98,套装归属聚类簇94,潮归属聚类簇90,正品归属聚类簇87。
⑥
结果验证。通过SQL脚本-1组件,在聚类簇中随意挑选一个类别,判断是否对同一类别的标签进行了自动归类。本工作流选用第10组聚类簇,在画布中单击SQL脚本-1组件,在右侧参数设置页签,配置SQL脚本为
select * from ${t1} where cluster_index=10。上述结果中,系统自动将与地理相关的标签进行了归类,但是混入了坚果等明显与类别不符的标签,可能是训练样本数量不足导致的。如果训练样本足够大,则标签聚类结果会非常准确。
-
相关文档
关于算法组件更详细的内容介绍,请参见: