
为了提高列存索引(IMCI)处理复杂查询的能力,列存索引优化器通过结合变换规则与表中各个列的统计信息,基于代价生成高效的执行计划,以此来增强自身的优化器能力。本文介绍列存索引查询优化功能的工作原理、使用方法以及使用限制等内容。
工作原理
SQL是声明式查询语言,不会具体的描述SQL语句的查询计划,获取一条SQL语句的正确结果时,可能存在若干个可行的查询计划。示例如下:
SELECT * FROM t0, t1, t2, t3 WHERE t0.a = t1.a AND t1.a = t2.a AND t2.a = t3.a AND t3.b = t1.b;对于上述SQL语句,通过以下两种查询计划均可以获取到正确的查询结果。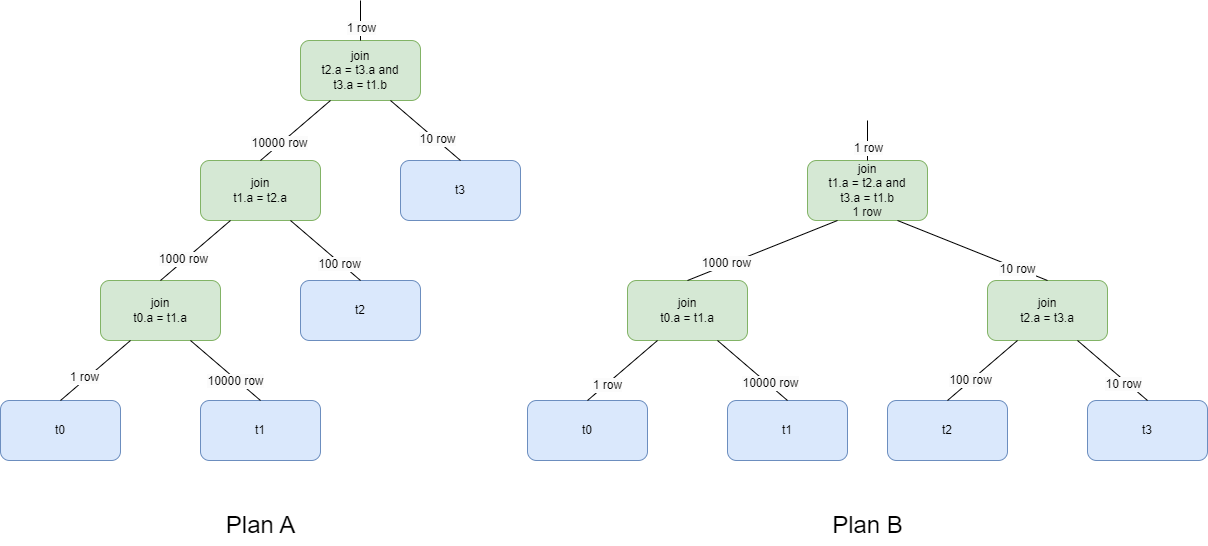 Plan A与Plan B称之为等价查询计划。查询优化器作为一个搜索框架,其会通过从一个查询计划到另一个等价查询计划的变换,来搜索与当前SQL语句对应的等价查询计划。例如:
Plan A与Plan B称之为等价查询计划。查询优化器作为一个搜索框架,其会通过从一个查询计划到另一个等价查询计划的变换,来搜索与当前SQL语句对应的等价查询计划。例如:t1 INNER JOIN t2与t2 INNER JOIN t1为一对等价查询计划,t1 INNER JOIN t2可以通过等价查询变换生成t2 INNER JOIN t1。优化器的这类变换称之为查询变换规则。
查询优化器工作流程如下:
-
输入由数据库解析SQL语句获得的初始查询计划。
-
通过应用查询变换规则,由初始状态的查询计划生成等价查询计划。
-
优化器通过结合统计信息与代价模型,从等价查询计划中选择出执行代价最小的查询计划,作为最终的执行计划交由执行层执行。
查询优化功能需要依靠统计信息进行基数估算和代价计算以判别查询计划的优劣,在列存索引中,表的统计信息包括以下内容:
-
直方图。描述对应列的值的分布范围,主要用于估算单张表上的取值范围及等值谓词的选择率。
-
对应列的特殊值的个数。主要用于估算
Group By中的分组个数,也可用于辅助估计等值谓词的选择率。 -
其他约束。如该列是否存在唯一索引,该列是否与其他列存在外键约束等。
查询优化器通过以下两方面来计算查询计划中各个节点操作符的代价:
-
查询计划中操作符处理的总行数,可以通过统计信息进行估算。
-
查询计划中各个操作符使用的算法复杂度。
其中,查询计划中操作符处理的总行数为算法复杂度函数的参数。各个节点的操作符代价和就是整个查询计划的执行代价。如上图中的两个查询计划,假设采用hash join作为join的执行算法,其代价公式为:
Costjoin=Cardinner+Cardouter
两个执行计划的代价分别为:
CostA==10000+1+1000+100+10000+10=21111
CostB==10000+1+100+10+1000+10=11121
由执行计划的代价可以看出,Plan B的执行代价更低。因此,优化器将选择Plan B作为最终的执行计划。
前提条件
PolarDB集群版本需满足以下条件之一:
-
PolarDB MySQL版8.0.1版本,且修订版本为8.0.1.1.31及以上。
-
PolarDB MySQL版8.0.2版本,且修订版本为8.0.2.2.12及以上。
您可以通过查询版本号来确认集群版本。
使用限制
以下情形可能会导致基数估算出现较大误差,从而导致优化器选择次优查询计划。您可以通过HINT语法指导优化器生成理想的查询计划。
-
带谓词的查询,查询同一张表的不同列时使用了比较运算符。如
t1.c1>t1.c2。 -
带谓词的查询,查询语句中使用的运算符不能使用统计信息进行估算。如
t1.c1 MOD 2=1、t1.c2 LIKE '%ABC%'。 -
带谓词的查询,查询语句中存在表达式,且无法在使用优化功能时进行计算。如
t1.c1+t1.c3>100。 -
查询语句中运算符所涉及的列没有用于估算谓词选择率的统计信息。如
SELECT a, SUM(b) FROM t1 HAVING SUM(b) > 10。 -
多个谓词之间使用
AND操作符连接。如t1.c1>10 AND t1.c3<5。 -
查询语句的查询层次太深。
-
查询语句中join的表太多。您可以通过修改参数
loose_imci_max_enum_join_pairs的值,来调整列存索引优化器搜索的join数量。
参数说明
您可以在控制台上设置以下参数,来开启和使用列存索引优化功能。在控制台上设置参数的操作步骤请参见设置集群参数和节点参数。
|
参数 |
说明 |
|
loose_imci_optimizer_switch |
列存索引查询优化功能控制开关。取值如下:
|
|
loose_imci_auto_update_statistic |
当统计信息过旧时,列存索引(IMCI)优化器是否重新收集统计信息。取值如下:
|
|
loose_imci_max_enum_join_pairs |
在使用列存索引功能并开启连接重排序时,允许列存索引优化器搜索的等价执行计划数量。 取值范围:0~4294967295。默认值为2000。 |
使用说明
使用列存索引优化功能,您需要先根据选择的信息采集策略采集统计信息,信息采集完成后,再开启列存索引查询优化功能,并执行查询语句。
-
采集统计信息。
您可以根据以下两种信息采集策略来采集统计信息。
-
在数据库中定期对需要使用列存索引优化功能的表执行
ANALYZE TABLE命令,来构建最新的统计信息。 -
(推荐)对于新添加列存索引的表,在只读节点上执行
ANALYZE TABLE命令构建初始的统计信息,再将参数loose_imci_auto_update_statistic的值设置为ASYNC来自动更新统计信息。
-
-
开启列存索引查询优化功能。
您可以在控制台上设置参数
loose_imci_optimizer_switch的值来开启列存索引查询优化功能。 -
执行查询语句。
查询效果对比
以TPCH-Q8为例,该查询语句涉及多张表,且在查询语句中使用了聚合函数。
SELECT
o_year,
SUM(
CASE
WHEN nation = 'BRAZIL' THEN volume
ELSE 0
END
) / SUM(volume) AS mkt_share
FROM
(
SELECT
EXTRACT(
year
FROM
o_orderdate
) AS o_year,
l_extendedprice * (1 - l_discount) AS volume,
n2.n_name AS nation
FROM
lineitem,
orders,
part,
supplier,
customer,
nation n1,
nation n2,
region
WHERE
p_partkey = l_partkey
AND s_suppkey = l_suppkey
AND l_orderkey = o_orderkey
AND o_custkey = c_custkey
AND c_nationkey = n1.n_nationkey
AND n1.n_regionkey = r_regionkey
AND r_name = 'AMERICA'
AND s_nationkey = n2.n_nationkey
AND o_orderdate BETWEEN DATE '1995-01-01'
AND DATE '1996-12-31'
AND p_type = 'ECONOMY ANODIZED STEEL'
) AS all_nations
GROUP By
o_year
ORDER BY
o_year;-
未开启列存索引优化功能的查询计划如下:
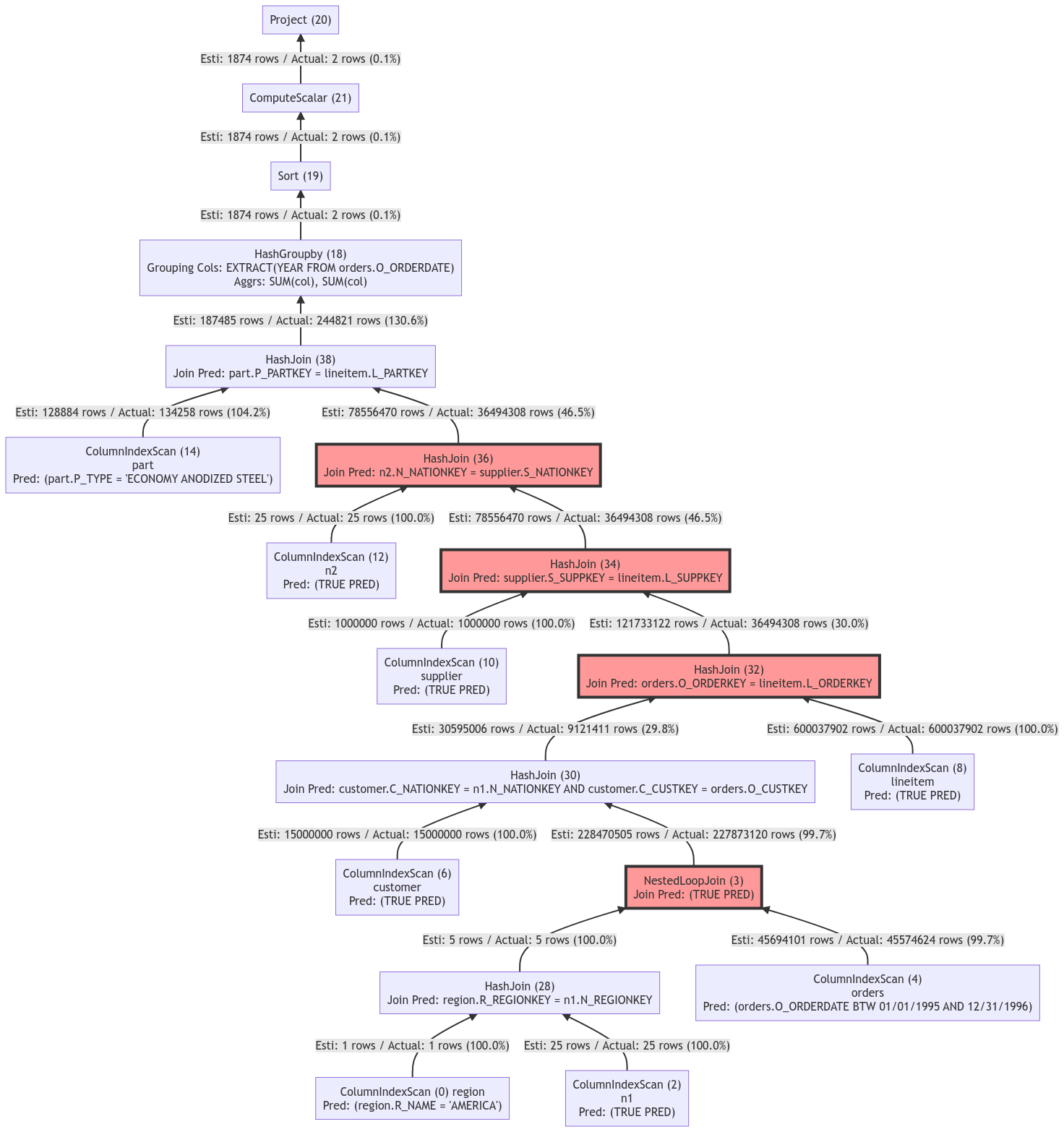 该查询计划中大量的join查询生成了较大的结果集,导致后续由操作符处理的数据与处理成本随之增加,查询时延延长。该查询计划在TPCH SF100规模的数据下,使用32C机器进行测试,该语句的查询耗时为7017ms。
该查询计划中大量的join查询生成了较大的结果集,导致后续由操作符处理的数据与处理成本随之增加,查询时延延长。该查询计划在TPCH SF100规模的数据下,使用32C机器进行测试,该语句的查询耗时为7017ms。 -
开启列存索引优化功能的查询计划如下:
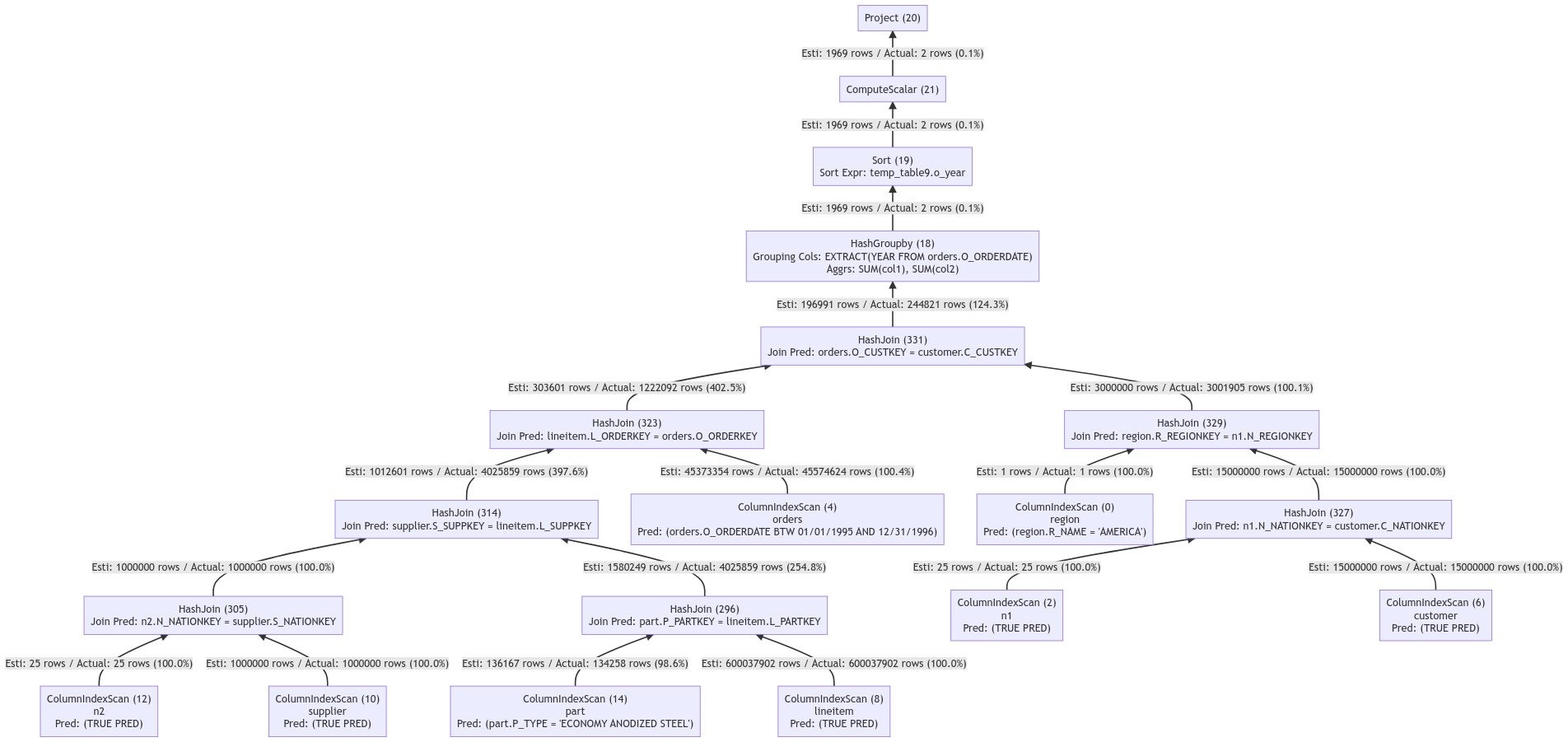 列存索引优化器通过对join查询进行重排序,使得几乎所有join操作符的输出结果数据量降到百万级别,有效地减少了后续各个操作符的处理成本。该查询计划在TPCH SF100规模的数据下,使用32C机器进行测试,该语句的查询耗时为1900ms。较未开启查询优化功能的查询耗时缩短了73%。
列存索引优化器通过对join查询进行重排序,使得几乎所有join操作符的输出结果数据量降到百万级别,有效地减少了后续各个操作符的处理成本。该查询计划在TPCH SF100规模的数据下,使用32C机器进行测试,该语句的查询耗时为1900ms。较未开启查询优化功能的查询耗时缩短了73%。