
多元索引(Search Index)基于倒排索引和列式存储,可以解决大数据的多维查询和统计分析难题。当日常业务中有非主键列查询、多列组合查询、模糊查询、全文检索和向量检索等复杂查询需求以及求最值、统计行数、数据分组等数据分析需求时,您可以将这些属性作为多元索引中的字段并使用多元索引查询与分析数据。
背景信息
多元索引只适用于宽表模型。
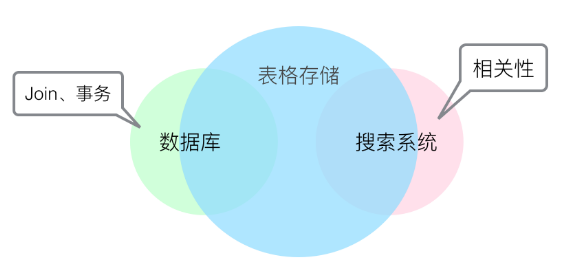
多元索引与数据库、搜索引擎等其他系统均能解决大数据中复杂的查询问题。它们的主要区别如下:
除了Join、事务和相关性外,表格存储能覆盖数据库和搜索系统中的其他功能,同时具备数据库的数据高可靠性和搜索系统的高级查询能力,可以替换常见的数据库 + 搜索系统组合架构方式。
如果您的使用场景中不涉及Join操作、事务处理和复杂的相关性分析,您可以选择使用表格存储多元索引。
索引介绍
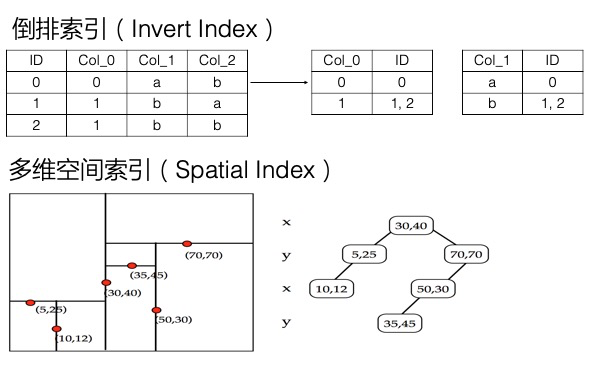
多元索引基于倒排索引和列式存储,可以解决大数据的多维数据查询和统计分析难题,包括非主键列查询、前缀查询、模糊查询、多字段自由组合查询、嵌套查询、地理位置查询、全文检索、向量检索和统计聚合(max、min、count、sum、avg、distinct_count、group_by、percentiles和histogram)等功能。
下图展示了多元索引采用的倒排索引和列式存储的原理以及多维空间索引结构。
多元索引的使用方式不同于MySQL等传统数据库的索引使用方式,无最左匹配原则的限制,使用时非常灵活。一般情况下一张表只需要创建一个多元索引即可。例如有一个学生表,包括姓名、学号、性别、年级、班级、家庭住址等列,如果要实现姓名等于张三且年级为三年级的学生、家庭住址在附近1公里内且性别为男的学生、找出三年级二班住在某小区的学生等任意条件的组合查询,您可以创建一个多元索引实现,在创建多元索引时,将这些列添加到同一个多元索引中即可。
索引对比
表格存储为数据表提供了数据表主键查询方式,还提供了二级索引(Secondary Index)和多元索引两种加速查询的索引结构。下表展示了三种查询方式的区别。
查询方式 | 原理 | 场景 |
数据表主键 | 数据表类似于一个巨大的Map,它的查询能力也类似于Map,只能通过主键查询。 | 适用于可以确定完整主键(Key)或主键前缀(Key prefix)的场景。 |
二级索引 | 通过创建一张或多张索引表,使用索引表的主键列查询,相当于把数据表的主键查询能力扩展到了不同的列。 | 适用于能提前确定待查询的列,待查询列数量较少,且可以确定完整主键或主键前缀的场景。 |
多元索引 | 使用了倒排索引、BKD树、列存等结构,具备丰富的查询能力。 | 适用于除数据表主键和二级索引之外的其他所有查询和分析场景,例如非主键列的条件查询、任意列的自由组合查询、关系查询、全文检索、地理位置查询、模糊查询、嵌套结构查询、Null值查询、统计聚合等。 |
适用场景
多元索引可广泛应用于各类应用系统中进行数据查询与分析。多元索引的实际应用场景包括但不限于下表的样例场景。
应用系统 | 样例场景 |
电商平台 | 在电商平台中使用多元索引实现商品的分类、属性筛选等功能,方便用户进行快速的商品搜索和筛选。 |
社交应用 | 在社交网络中使用多元索引实现用户的关注关系、好友关系等查询以及根据用户的兴趣标签进行推荐和匹配。 |
日志分析 | 在日志分析场景中使用多元索引进行日志的关键字搜索、按照时间范围查询等操作,用于快速定位问题和分析日志数据。 |
物联网数据分析 | 在物联网场景中使用多元索引进行设备数据的查询和分析,例如按照设备类型、地理位置等进行筛选和统计。 |
应用性能监控 | 在应用性能监控中使用多元索引进行指标数据的聚合和查询,例如按照时间范围、应用名称等进行筛选和汇总。 |
地理位置服务 | 在地理位置服务中使用多元索引进行地理位置的查询和附近搜索,用于提供附近的店铺、景点、服务等信息。 |
文本搜索引擎 | 在文本搜索引擎中使用多元索引进行全文检索和相关性排序,用于快速搜索和查找文档、文章等信息。 |
功能说明
功能列表
多元索引的功能列表请参见下表。
功能 | 说明 | 文档 |
任意列的查询(包括主键列和非主键列) | 使用任意列进行数据查询,适用于大多数场景下的查询需求。 当使用主键列或主键列前缀查询无法满足需求时,您可以创建一个多元索引并在索引中添加要查询的字段,即可通过该列的值查询数据。 | 多元索引任意查询,例如基础查询等 |
多字段自由组合查询 | 灵活组合多个字段进行高效查询,适用于订单系统、日志分析、用户画像等需要多条件筛选的场景。 以订单场景为例,表中可能包含多达几十个字段。在关系型数据库中,为满足多种字段组合的查询需求,可能需要创建上百个索引。同时如果某种组合方式未提前预想到且未创建相应索引,则无法高效查询。 使用表格存储,只需创建一个多元索引并在索引中添加可能要查询的字段。查询时可自由组合这些字段。此外,多元索引还支持多种逻辑关系查询,例如And、Or、Not。 | |
地理位置查询 | 随着移动设备的普及,地理位置信息的价值越来越大,朋友圈、微博、外卖、运动、车联网等应用中均增加了地理位置功能,这些应用中的数据包含地理位置信息,因此需要相匹配的查询能力。 多元索引提供以下地理位置查询功能:
基于上述功能,如果应用中需要地理位置相关查询,使用表格存储多元索引即可一站式解决,无需依赖其他数据库或搜索系统。 | |
全文检索 | 查找包含指定短语的数据,适用于大数据分析、内容搜索、知识管理、社交媒体分析、日志分析、智能问答系统、合规审查、个性化推荐等场景。 多元索引的分词能力可用于实现全文检索,但是多元索引只提供最基础的BM25相关性,不提供自定义相关性能力。因此,如果有复杂相关性的搜索需求,建议使用搜索系统实现,否则可以使用多元索引满足需求。 目前多元索引提供了单字分词、分隔符分词、最小数量语义分词、最大数量语义分词和模糊分词5种分词类型,请根据实际场景配置。此外,如需在返回结果中对关键词进行高亮显示,可使用摘要与高亮功能实现。 | |
向量检索 | 多元索引支持向量检索能力,您能够利用数值向量进行高效的近似最近邻查询,从而在大规模数据集中找到最相似的数据项。该功能适用于检索增强生成(RAG)、推荐系统、相似性检测(图像、视频和语音等)、自然语言处理等应用场景。 | |
模糊查询 | 多元索引提供了通配符查询、前缀查询和后缀查询功能,以满足用户不同场景的模糊查询需求。
| |
列存在性查询(NULL查询) | 查询某一列是否为空值,类似于NULL查询,适用于数据完整性检查、数据清洗等场景。 | |
嵌套查询 | 在线应用的数据中,除了常见的扁平化结构外,还存在一些更复杂的多层嵌套结构场景,例如图片标签。假设某个系统中存储了大量图片,每张图片包含多个实体(例如房子、轿车、人等),这些实体在图片中的位置和空间大小各不相同,因此每个实体的权重(score)也不同。这种情况下,每张图片均对应多个标签,每个标签由一个名称和一个权重分组成。 如果要根据标签中的条件筛选图片,可以使用嵌套类型查询功能。其中图片标签采用JSON格式存储,数据样例如下: 嵌套类型查询能够有效处理具有多层逻辑关系的数据存储与查询需求,为复杂数据建模提供了极大的灵活性和便利性。 对于包含嵌套类型的复杂数据结构(例如JSON)支持使用摘要与高亮功能来精准定位所需信息。 | |
去重 | 多元索引提供了查询结果的去重功能,能够有效提升结果的多样性。去重功能通过限制某个属性在单次查询结果中的最大出现次数,避免结果过度集中于某一特定值。例如,在电商搜索场景中,当搜索 | |
排序 | 表格存储默认按照主键的字母序排序,如果需要按照其他字段进行排序,您可以使用多元索引的排序功能。 多元索引提供了丰富的排序能力,包括正序或逆序、单条件排序以及多条件排序等,所有排序均为全局排序。多元索引的默认返回结果按照表中主键的字母序排列。 | |
数据总行数 | 使用多元索引查询数据时支持指定返回本次请求命中的数据行数。此功能可用于数据校验、运营等场景。
| |
统计聚合 | 多元索引提供常见的统计聚合功能,包括最大值(Max)、最小值(Min)、平均值(Avg)、求和(Sum)、统计行数(Count)、去重统计行数(DistinctCount)、分组(GroupBy)、百分位(Percentile)、直方图(Histogram)等功能,可以满足用户在轻量级分析场景对基本统计聚合的需求。 |
支持地域
目前多元索引功能开放的地域包括华东1(杭州)、华东2(上海)、华北1(青岛)、华北2(北京)、华北3(张家口)、华北6(乌兰察布)、华南1(深圳)、华南3(广州)、西南1(成都)、中国香港、日本(东京)、新加坡、马来西亚(吉隆坡)、印度尼西亚(雅加达)、菲律宾(马尼拉)、泰国(曼谷)、德国(法兰克福)、英国(伦敦)、美国(硅谷)、美国(弗吉尼亚)、华东1 金融云、华东2 金融云、华北2 阿里政务云1。其中美国(硅谷)地域暂不支持向量检索功能。
容灾能力
多元索引在具备同城容灾能力的地域默认提供同城冗余的容灾能力,会将数据同时存储到地域内多个不同的可用区。在单可用区遇到断电、断网、火灾等故障时仍能保障数据的正常读写服务、不会影响读写可用性。
目前多元索引支持同城冗余的地域包括华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华北6(乌兰察布)、华南1(深圳)、中国香港、日本(东京)、新加坡、印度尼西亚(雅加达)、德国(法兰克福)、华东1 金融云、华东2 金融云、华北2 阿里政务云1。
数据生命周期
如果数据表无UpdateRow更新写入操作,则您可以使用多元索引TTL。更多信息,请参见生命周期管理。
当只需要保留一段时间内的数据且时间字段不需要更新时,您可以通过按时间分表的方法实现数据生命周期功能。按时间分表的原理、原则和优点请参见下表说明。
维度 | 按时间分表 |
原理 | 按照固定时间,例如“日”、“周”、“月”或者“年”分表,并为每个表建立一个多元索引,根据需要保留所需时间的数据表。 例如当数据需要保留6个月时,可以将每个月的数据保存在一张数据表中,例如table_1、table_2、table_3、table_4、table_5、table_6,并为每个数据表创建一个多元索引,每个数据表和多元索引中只会保存一个月的数据,只需要每个月删除6个月前的数据表即可。 当使用多元索引查询数据时,如果时间范围在某个表中,只需要查询对应表;如果时间范围在多个表中,需要对涉及的数据表均查询一次,再将查询结果合并。 |
原则 | 单表(单索引)大小不超过500亿行,当单表(单索引)大小不超过200亿行时,多元索引的查询性能最好。 |
优点 |
|
数据多版本
多元索引不支持数据多版本,即不能对设置了数据多版本的数据表创建多元索引。
当在单版本中每次写入数据时自定义了timestamp,且先写入版本号较大的数据,后写入版本号较小的数据,此时先写入的版本号较大的数据可能会被后写入的版本号较小的数据覆盖。
Search和ParallelScan请求的结果数据中不一定包括timestamp属性。
使用限制
多元索引使用异步的方式从数据表中同步数据,存在数据延迟的现象,无法实时查询数据,延迟通常在3秒以内。更多关于多元索引的使用限制,请参见多元索引使用限制。
计费说明
使用多元索引时,索引数据量占用的存储空间为多元索引存储,通过多元索引查询与分析数据会消耗计算资源。更多信息,请参见计费概述。
开发集成
接口说明
多元索引提供了索引管理和数据查询的接口。其中数据查询接口包括通用查询(Search)接口和数据导出(ParallelScan)接口,两种数据查询接口的功能大部分相同,但是ParallelScan接口为了提高某些方面的性能和吞吐能力舍弃了部分功能。
分类 | 接口 | 描述 |
索引管理 | 创建一个多元索引。 | |
更新多元索引的配置,包括数据生命周期(TTL)和多元索引schema。 | ||
获取多元索引的详细描述信息。 | ||
列出多元索引的列表。 | ||
删除某个多元索引。 | ||
数据查询 | 全功能查询接口,支持多元索引的所有功能点,包括所有的查询功能以及排序、统计聚合等分析能力,其结果会按照指定的顺序返回。
| |
多并发数据导出接口,只包括所有的查询功能,舍弃了排序、统计聚合等分析能力,能将命中的数据以更快的速度全部返回。 相对于Search接口,ParallelScan可以提供更好的性能,单并发时性能(吞吐能力)是Search接口的5倍。
多并发导出数据时,您还需要通过ComputeSplits接口获取当前ParallelScan单个请求的最大并发数。 |
集成方式
您可以使用以下的SDK或命令行工具操作多元索引。
常见问题
相关文档
如果要使用SQL查询与分析数据,您可以使用表格存储的SQL查询功能实现。更多信息,请参见SQL查询。
说明您也可以通过MaxCompute、Spark、Hive或者HadoopMR、函数计算、Flink等计算引擎分析表格存储中的数据。更多信息,请参见计算与分析概述。
使用合适的索引能大幅提升数据查询效率以及降低使用成本,建议您参考多元索引最佳实践进行索引设计。
基于多元索引可以实现搭建亿量级店铺搜索系统等方案。更多方案介绍,请参见多元索引实践。
附录:与SQL匹配情况
多元索引部分功能可以实现与SQL功能等价的效果。SQL中的大部分功能在多元索引中相匹配的功能请参见下表。
SQL | 多元索引 | 多元索引文档 |
Show | DescribeSearchIndex | |
Select | 任意Query中的ColumnsToGet参数 | 多元索引任意查询,例如基础查询等 |
From | 任意Query中的IndexName参数 重要 已经支持单索引,多索引尚未支持。 | 多元索引任意查询,例如基础查询等 |
Where | 任意Query中的条件 | 多元索引任意查询,例如基础查询等 |
Order by | 任意Query中的sort参数 | |
Limit | 任意Query中的limit参数 | |
Delete |
| |
Like | WildcardQuery | |
And | BoolQuery中operator = and | |
Or | BoolQuery中operator = or | |
Not | BoolQuery(mustNotQueries) | |
Between | RangeQuery | |
Null | ExistsQuery | |
In | TermsQuery | |
Min | Aggregation:min | |
Max | Aggregation:max | |
Avg | Aggregation:avg | |
Count | Aggregation:count | |
Count(distinct) | Aggregation:distinctCount | |
Sum | Aggregation:sum | |
Group By | GroupBy |