
RDS PostgreSQL支持pgvector插件,提供了一个新的数据类型,能够方便快捷地对高维向量进行检索,是一款功能强大的向量相似度匹配搜索插件。
您可以加入RDS PostgreSQL插件交流钉钉群(103525002795),进行咨询、交流和反馈,获取更多关于插件的信息。
背景
RDS PostgreSQL支持pgvector插件,能够存储向量类型数据,并实现向量相似度匹配,为AI产品提供底层数据支持。
pgvector主要提供如下能力:
-
支持数据类型vector,能够对向量数据存储以及查询。
-
支持精确和近似最近邻搜索(ANN,Approximate Nearest Neighbor),其距离或相似度的度量方法包括欧氏距离(L2)、余弦相似度(Cosine)以及内积运算(Inner Product)。索引构建支持HNSW索引、并行索引IVFFlat、向量的逐元素乘法、L1距离函数以及求和聚合。
-
最大支持创建16000维度的向量,最大支持对2000维度的向量建立索引。
相关概念及实现原理
嵌入
嵌入(embedding)是指将高维数据映射为低维表示的过程。在机器学习和自然语言处理中,嵌入通常用于将离散的符号或对象表示为连续的向量空间中的点。
在自然语言处理中,词嵌入(word embedding)是一种常见的技术,它将单词映射到实数向量,以便计算机可以更好地理解和处理文本。通过词嵌入,单词之间的语义和语法关系可以在向量空间中得到反映。
实现原理
-
嵌入可以将文本、图像、音视频等信息在多个维度上抽象,转化为向量数据。
-
pgvector提供vector数据类型,使RDS PostgreSQL数据库具备了存储向量数据的能力。
-
pgvector可以对存储的向量数据进行精确搜索以及近似最近邻搜索。
假设需要将苹果、香蕉、猫三个对象存储到数据库中,并使用pgvector计算相似度,实现步骤如下:
-
先使用嵌入,将苹果、香蕉、猫三个对象转化为向量,假设以二维嵌入为例,结果如下:
苹果:embedding[1,1] 香蕉:embedding[1.2,0.8] 猫:embedding[6,0.4] -
将嵌入转化的向量数据存储到数据库中。如何将二维向量数据存储到数据库中,具体请参见使用示例。
在二维平面中,三个对象分布如下:
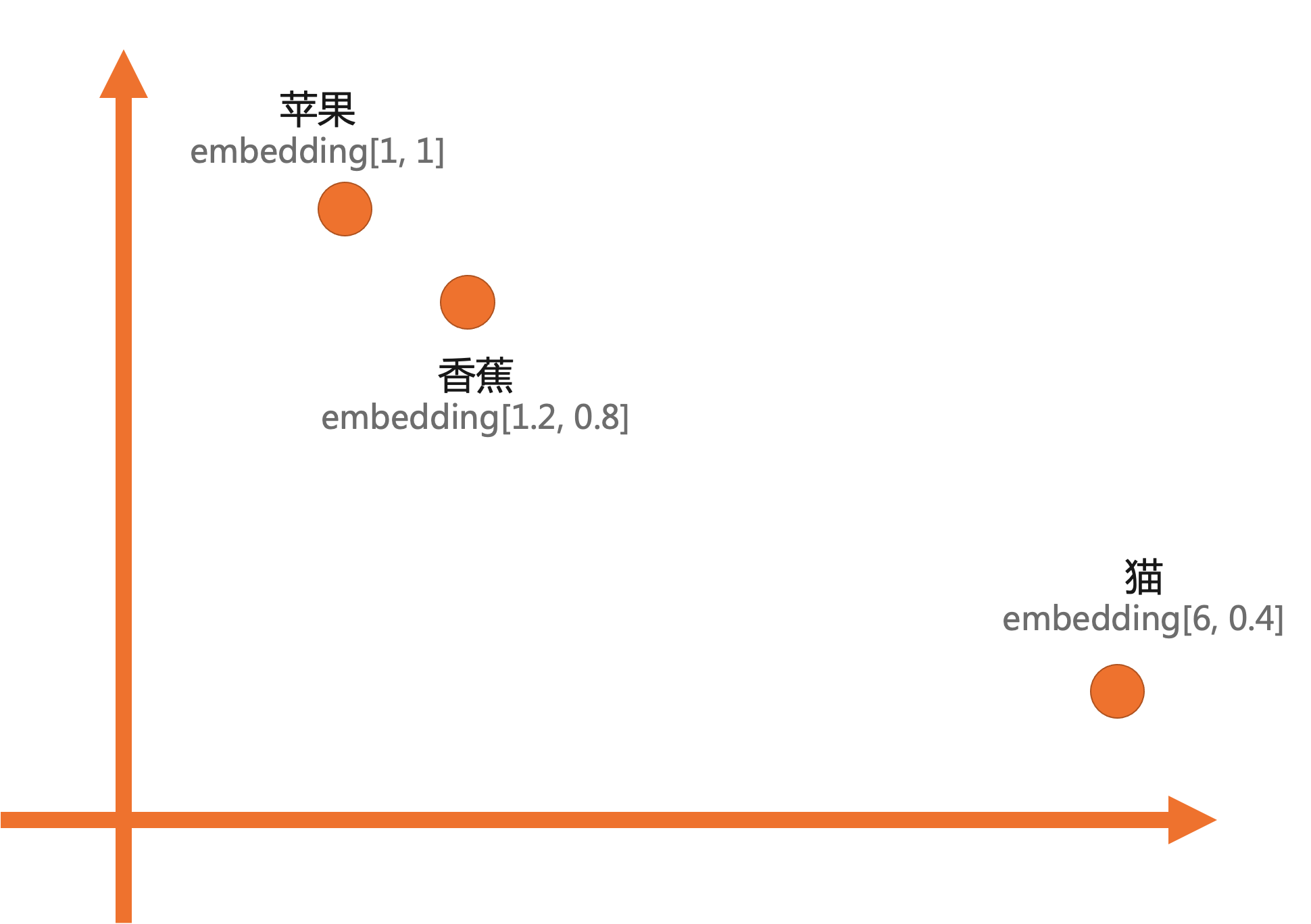
对于苹果和香蕉,都属于水果,因此在二维坐标视图中二者的距离更接近,而香蕉与猫属于两个完全不同的物种,因此距离较远。
可以对水果的属性进一步细化,比如水果的颜色,产地,味道等,每一个属性都是一个维度,也就代表了维度越高,对于该信息的分类就更细,也就越有可能搜索出更精确的结果。
应用场景
-
存储向量类型数据。
-
向量相似度匹配搜索。
前提条件
RDS PostgreSQL实例需满足以下要求:
-
实例大版本为PostgreSQL 14或以上。
-
实例内核小版本为20230430或以上。对于RDS PostgreSQL 17版本的实例,其内核的小版本应为20241030或以上。
-
已创建RDS PostgreSQL高权限账号,如何创建高权限账号请参见创建账号。
插件管理
通过控制台管理插件
-
安装插件
-
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
-
在左侧导航栏单击插件管理。
-
在插件市场页面中,请向下滚动以找到vector插件,并单击安装。
您也可以在管理插件页面,搜索vector插件,并单击操作列的安装。
-
在弹出的窗口中选择目标数据库和高权限账号后,单击安装,将插件安装至目标数据库。
当实例的状态由维护实例中变为运行中时,表示插件已成功安装。
-
-
更新和卸载插件
-
在管理插件页面的已安装插件页签,单击目标插件操作列的升级版本,将插件升级到最新版本。
说明如果操作列没有升级版本按钮,表示该插件的版本已是最新。
-
在管理插件页面的已安装插件页签,单击目标插件操作列的卸载,卸载目标插件。
-
通过SQL命令管理插件
仅高权限账号可以执行以下命令。如何创建高权限账号请参见创建账号。
-
创建插件
CREATE EXTENSION IF NOT EXISTS vector; -
删除插件
DROP EXTENSION vector; -
更新插件
ALTER EXTENSION vector UPDATE [ TO new_version ]说明new_version配置为pgvector的版本,pgvector的最新版本号及相关特性,请参见pgvector官方文档。
使用示例
如下仅是对pgvector的简单使用示例,更多使用方法,请参见pgvector官方文档。
-
在目录数据库中,使用具备建表权限的用户创建一个存储vector类型的表(items),用于存储embeddings。
CREATE TABLE items ( id bigserial PRIMARY KEY, item text, embedding vector(2) );说明上述示例中,以二维为例,pgvector最大支持创建16000维度的向量。
-
将向量数据插入表中。
INSERT INTO items (item, embedding) VALUES ('苹果', '[1, 1]'), ('香蕉', '[1.2, 0.8]'), ('猫', '[6, 0.4]'); -
使用余弦相似度操作符
<=>计算香蕉与苹果、猫之间的相似度。SELECT item, embedding <=> '[1.2, 0.8]' AS cosine_distance FROM items ORDER BY cosine_distance;说明-
在上述示例中,直接使用
<=>操作符计算余弦距离,距离越小,相似度越高。 -
您也可以使用欧氏距离操作符
<->或内积运算操作符<#>计算相似度。
结果示例:
item | cosine_distance ------+---------------------- 香蕉 | 0 苹果 | 0.019419362524530137 猫 | 0.13289443670962842在上述结果中:
-
香蕉结果为 0,表示完全匹配(距离为0)。
-
苹果的结果为 0.019,表示苹果与香蕉距离很近,相似度很高。
-
猫的结果为 0.133,表示猫与香蕉距离较远,相似度较低。
说明您可以在实际业务中设置一个合适的相似度阈值,将相似度较低的结果直接排除。
-
-
为了提高相似度查询的效率,pgvector支持为向量数据建立索引,执行如下语句,为embedding字段建立索引。
创建HNSW索引
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64);参数说明:
参数
说明
m
表示构建HNSW索引时,每层中每个节点的最大邻近节点数目。
该值越大,图的稠密度越高,通常会导致召回率的提高,同时构建和查询所需的时间也相应增加。
ef_construction
表示构建HNSW索引时,候选集的大小,即搜索在构建过程中保留多少候选节点用于选择最优连接。
该值越大,通常召回率也越高,但构建和查询所需的时间也相应增加。
创建IVF索引
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);参数说明:
参数/取值
说明
items
添加索引的表名。
embedding
添加索引的列名。
vector_cosine_ops
向量索引方法中指定的访问方法。
-
余弦相似性搜索,使用
vector_cosine_ops。 -
欧氏距离,使用
vector_l2_ops。 -
内积相似性,使用
vector_ip_ops。
lists = 100
lists参数表示将数据集分成的列表数,该值越大,表示数据集被分割得越多,每个子集的大小相对较小,索引查询速度越快。但随着lists值的增加,查询的召回率可能会下降。
说明-
召回率是指在信息检索或分类任务中,正确检索或分类的样本数量与所有相关样本数量之比。召回率衡量了系统能够找到所有相关样本的能力,它是一个重要的评估指标。
-
构建索引需要的内存较多,当lists参数值超过2000时,会直接报错
ERROR: memory required is xxx MB, maintenance_work_mem is xxx MB,您需要设置更大的maintenance_work_mem才能为向量数据建立索引,该值设置过大实例会有很高的OOM风险。设置方法,请参见设置实例参数。 -
您需要通过调整lists参数的值,在查询速度和召回率之间进行权衡,以满足具体应用场景的需求。
您可以使用如下两种方式之一来设置ivfflat.probes参数,指定在索引中搜索的列表数量,通过增加ivfflat.probes的值,将搜索更多的列表,可以提高查询结果的召回率,即找到更多相关的结果。
-
会话级别
SET ivfflat.probes = 10; -
事务级别
BEGIN; SET LOCAL ivfflat.probes = 10; SELECT ... COMMIT;
ivfflat.probes的值越大,查询结果的召回率越高,但是查询的速度会降低,根据具体的应用需求和数据集的特性,lists和ivfflat.probes的值可能需要进行调整以获得最佳的查询性能和召回率。
说明如果ivfflat.probes的值与创建索引时指定的lists值相等时,查询将会忽略向量索引并进行全表扫描。在这种情况下,索引不会被使用,而是直接对整个表进行搜索,可能会降低查询性能。
-
性能数据
为向量数据设置索引时,需要根据实际业务数据量及应用场景,在查询速度和召回率之间进行权衡。相关性能测试请参见: